
Enhancing Reinforcement Learning with Quantum Computing for Robotic Arm control
Reinforcement Learning has emerged as an interesting approach for the control of robotic arm movement in unstructured environments. However, the challenges of learning versatile control capabilities are still far from being resolved for real-world applications, mainly because of two issues of such learning paradigm: the exploration strategy and the slow learning speed. The application of Quantum Computing to Reinforcement Learning promises to solve such issues.

Antonio Policicchio
NTT DATA Italia S.p.A.
Antonio obtained his PhD in Physics at the University of Calabria. He had several research positions at different universities and research institutions, including University of Washington, CERN and Sapienza University of Rome. In March 2020, he joined NTT DATA Italy in the Innovation & Advanced Technology service line. He is currently leading R&D projects in Quantum Computing and Artificial Intelligence.
Make robots autonomous with Reinforcement Learning
Autonomous robots are designed and engineered to deal with the environment on their own, without human intervention. They are intelligent machines that make decisions based on what they perceive from the environment, and then actuate a complex movement or manipulation task within that environment. To enable autonomous behavior of the robots, in recent years, research and industrial communities have been seeking for more software-based control solutions using low-cost sensors and focus on robust algorithms and software, which have less requirements for the operating environment and calibration. Deep Reinforcement Learning (DRL), the combination of Deep Learning and Reinforcement Learning (RL), has emerged as a promising approach for robots to autonomously acquire complex behaviors from low-level sensor observations of the environment, promising to enable physical robots to learn complex skills in highly unstructured environments. Instead of hard-coding directions in Programmable Logic Controllers with inverse kinematics to coordinate the robot movement, the control policy could be obtained by learning and then be updated accordingly. Using learning-based techniques for robot control is appealing because it can enable robots to move towards less structured environments, to handle unknown objects, and to learn a state representation suitable for multiple tasks like e.g., warehouse automation to replace human pickers for objects of different size and shape, clothes and textiles manufacturing, food preparation industry.
Challenges of Reinforcement Learning for robot controls
Compared to RL, DRL allows to fix critical issues relative to the dimensionality and scalability of data in tasks with sparse reward signals, such as robotic manipulation and control tasks. However, despite recent improvements, the challenges of learning robust manipulation skills for robots with DRL still remain to be solved for real-world applications. This is mainly due to some well know issues with DRL: sample efficiency, generalization, and computing resources for training the learning algorithms for complex problems. Sample efficiency means how much data are needed to be collected in order to build an optimal policy to accomplish the designed task. Several issues in robotics prevent an effective sample efficiency: the agent cannot receive a training set provided by the environment unilaterally, but rather information which is determined by both the actions it takes and the dynamics of the environment; although the agent aims at maximizing the long-term reward, it can only observe the immediate reward; there is no clear boundary between training and test phases, since the time the agent spends trying to improve the policy often comes at the expense of utilizing this policy, which is often referred to as the exploration–exploitation trade-off. On the other hand, generalization refers to the capacity to use previous knowledge from a source environment to achieve a good performance in a target environment, and applicability for flexible long-term autonomy. This is widely seen as a necessary step to produce artificial intelligence that behaves similar to humans. Moreover, it has to be noted that, given the large amount of data to reach optimal results, DRL is computationally intensive, and it requires high-performance computers for model training and fastening the learning process.
More progress is required to overcome such limitations, as both gathering experiences by interacting with the environment and collecting expert demonstrations for RL are expensive procedures. Quantum Computing (QC) promises the availability of computational resources and generalization capabilities well beyond the possibilities of classical computers, that can be leveraged to speed up and improve the learning process.
Quantum Computing for Machine Learning
Quantum computing is a technology that leverages the laws of quantum mechanics to solve problems too complex for classical computers. Even if fault-tolerant quantum devices are still far to come, near-term devices – Noisy Intermediate-Scale Quantum Computers (NISQ), limited in the number of qubits, coherence times and operations fidelity – can already be utilized for a variety of problems. One promising approach is the hybrid training of Variational or Parameterized Quantum Circuits (VQC), i.e. the optimization of a parameterized quantum algorithm as a function approximation with classical optimization techniques, similar to a classical Neural Network. The main approach in the scientific community is to formalize problems of interest as variational optimization tasks, then using a hybrid quantum-classical hardware setup to find approximate solutions.
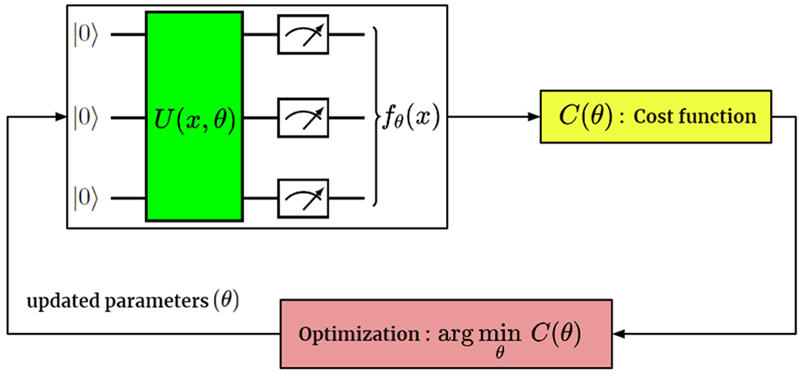
Figure 1: Schematic representation of a Variational Quantum Algorithm
By implementing some subroutines on classical hardware, the requirement of quantum resources is significantly reduced, particularly in the number of qubits, circuit depth, and coherence time. Therefore, in the hybrid algorithmic approach, NISQ hardware focuses entirely on the classically intractable part of the problem. Quantum Machine Learning (QML) typically involves training a VQC in order to analyze the classical data. QML models may offer some advantages over classical models in terms of memory consumption and sample complexity for classical data analysis. Moreover, recent researches presented a comprehensive study of generalization performance in QML after training on a limited number of training data points, showing that a good generalization is guaranteed from few training data. All such aspects look promising to overcome the DRL issues discussed above for robot control.
Enhancing Reinforcement Learning with Quantum Computing
Several research papers have discussed about a possible quantum advantage using quantum computers for Reinforcement Learning tasks – i.e., to speed up the decision process of the agent implementing a quantum agent operating in a classical environment. Long-term techniques, requiring a full-quantum approach such as the Grover search algorithm, lead to large circuits and fault-tolerant quantum computers, still to be developed. Today’s best approach involves hybrid “quantum-classical” algorithms, whose quantum part is implemented through smaller circuits and the VQC technique. In DRL, deep neural networks are employed as powerful function approximators. Typically, the approximation either happens in policy space (actor), in value space (critic), or both, resulting in so-called actor-critic approaches. Recently, VQCs were proposed and analyzed in their role as function approximators for the RL setting. Thus far there is no guaranteed quantum advantage for this approach. However, several of the papers and preprints demonstrate promising experimental results. Namely, VQC-based models can achieve at least the same performance as Neural Network based function approximators, and the usage of VQCs reduces significantly the required parameter complexity and the convergence time, and improves the training stability and the expressivity of the RL model (see e.g., https://arxiv.org/pdf/2211.03464.pdf for a comprehensive review).
Control a robotic arm with Quantum Reinforcement Learning
Starting from recent utilization of VQCs in RL problems, we investigated the possible application of quantum-classical hybrid algorithms to the control task of a robotic arm. And, by means of digital simulations of quantum circuits, we have experimented and assessed the advantages of the application of VQCs to one of the state-of-art Reinforcement Learning techniques for continuous control – the Soft Actor-Critic (SAC). Indeed, the task of robotic arm operation requires continuous control, due to the continuous-valued observations coming from sensors and actions for accurate movement control. A robotic arm can be described as a chain of links that are moved by joints containing motors to change the link position and orientation. For our experimentation we used a virtual 2-dimensional, four-joints robotic arm mounted and fixed on the first joint. The arm is able to move the links using the joints on the 2-dimensional plane and can independently move each link clockwise and counter-clockwise up to a given velocity. Last joint is referred to as the end effector. Such environment has been created using Box2D technology, by adapting parts of an OpenAI Gym environment called “Acrobot”.
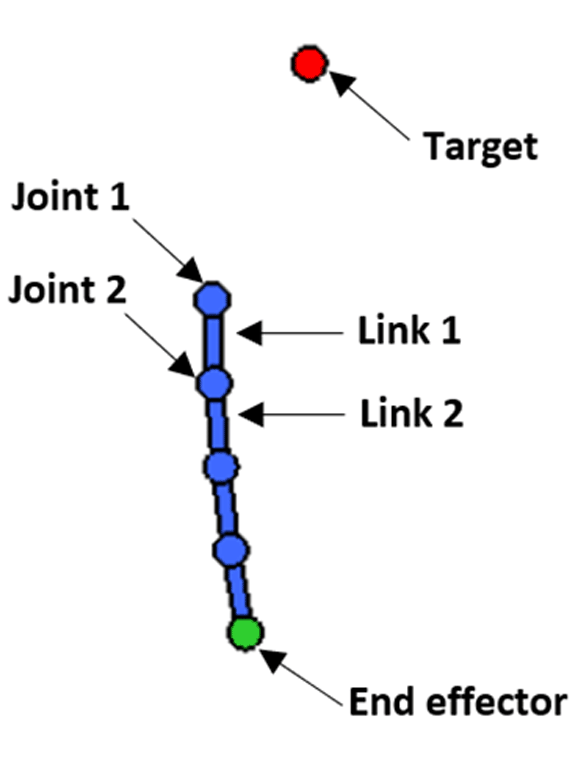
Figure 2: Schematic diagram of mechanical components of a four-joint robotic arm.
The Quantum Soft Actor-Critic algorithm is quite similar to its classical counterpart, the only difference being the replacement of some Neural Network layers with a VQC.
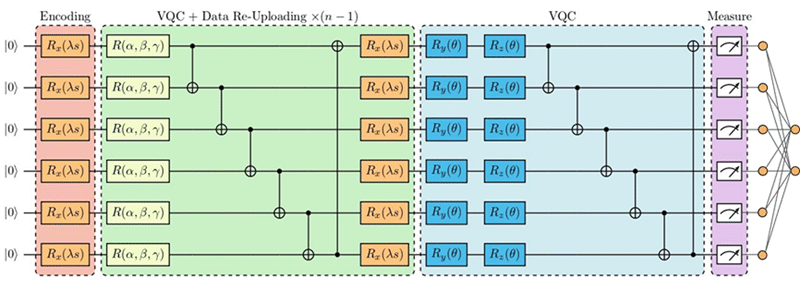
Figure 3: Architecture of quantum-classical hybrid Actor component of the Quantum Soft Actor-Critic.
The TensorFlow Quantum library from Google has been used as the development framework for Quantum Machine Learning. This library works by simulating the quantum circuit using Google Cirq library for quantum circuits, and distributing the computational workload through the multi-threading features of TensorFlow. All classical components of the quantum-classical hybrid algorithm have been implemented using the TensorFlow library for Machine Learning. A clear quantum advantage has been found in the number of learnable parameters. In particular, the classical Soft Actor-Critic algorithm with the same number of parameters as the quantum counterpart does not converge. The classic algorithm requires 100 times the amount of parameters compared to the quantum algorithm to solve the environment with performance comparable to the quantum agent.
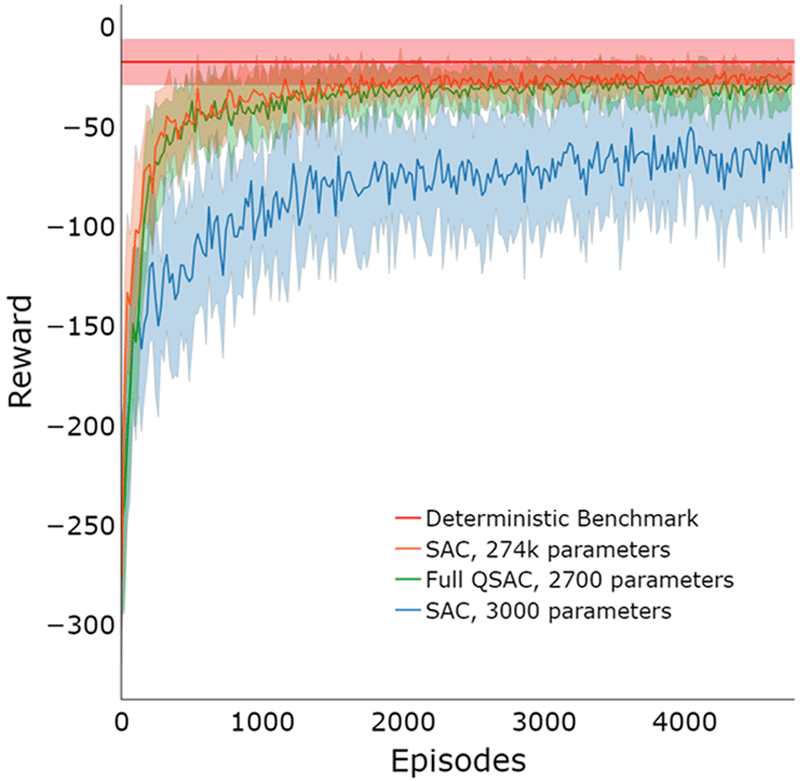
Figure 4: Learning curves of classical and quantum-classical SAC architectures tested on the robotic arm environment.
Conclusions
Through numerical simulations, we have shown that in the benchmark robotic control task considered, actor-critic quantum policies outperform the performance of classical models with similar architectures. This technique may have potential applications in various real-world scenarios, as the work demonstrates that robot control is a viable field of application for Quantum Reinforcement Learning and of future advancements in autonomous robotics.
Results of the work have been submitted to arXiv at the following link
https://arxiv.org/pdf/2212.11681.pdf.
This is an initiative of the Innovation Center, Research and Development Headquarters.

