
「自然言語処理」の必要性
NTT DATA Technology Foresightでは、将来、コンピューターが人間の知的活動を代行するという展望を掲げています参考1。また、カーツワイルも2020年~2045年の間にITが人間の能力を超えると予測しています参考2。人間の能力において言語を使った活動は特に大きな意味を持つため、言語情報を解釈する技術の発展は、コンピューターが人間を超えることに直結しています。
言語処理の中で特に重要なこと
言語処理を行う際は、「文内の単語間の関係解析」や「文間の相互関係の解析」など、さまざまな解析が必要ですが、特に「単語とその意味を特定すること」が重要になります。
単語を空間に配置するアプローチで解析
最近は、豊富な言語データを背景に、単語の使われ方を統計的に見て、単語の意味・性質を考えるアプローチがとられています。同じ意味を持つ単語は同じような使われ方をする、という考え方が基本にあります。具体的には、同一の文章の中で、一緒に使われやすいといった情報をもとに、Deep Learning参考3を用いることで、単語と単語の意味的な類似性を高精度で計算できるようになっています。
「単語を空間に配置するアプローチ」では、それぞれの単語の類似性を保ったまま、空に星を散りばめるように、空間上に単語を配置します。その際、性質が同じ単語は、ある位置から同距離、同方向に配置されます。更に解析精度の向上により、これまでできなかった、単語同士で足したり、引いたりする演算ができるようになりました。たとえば、(日本―東京)+中国を入力とすると「北京」が出力されるイメージ(図:参照)です。
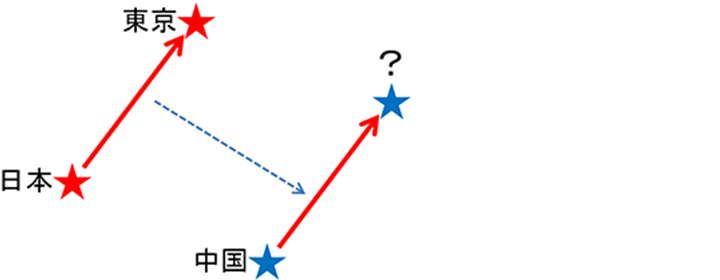
図:単語の演算イメージ
言語処理から新たな知見を得る
TwitterなどのSNSデータを分析する手法はマーケティングで活用されつつあり、商品を好意的に感じているか否かの感情分析(ポジネガ分析とも呼ばれています)も盛んに実施されています。当社の高精度日本語解析エンジン「なずき」参考4でも、この機能を提供しています。先ほどの「単語を空間に配置するアプローチ」を用いると、SNS情報に含まれる単語から、同様にそれぞれの単語の類似度を計算することができます。この類似度をもとに、たとえば、(A社―商品X)+B社=商品Yのように、競合他社A社の売れ筋商品Xから、自社B社の隠れた売れ筋商品Yを見つけ出すなど、新たな分析の方式が開発できる可能性も見えています。
- 注1区別する必要がある同音異義語、区別してはいけない同義語の特定が必要になります。
- 注2高速で簡単に利用できる解析ツールが提供されているので、誰でも気軽に試すことができます参考5。
NTTデータでは、「自然言語処理」技術の開発に取り組み、人間の知的活動をサポートするサービスの提供を目指しています。







