
リーズナブルな並列分散処理が実現可能になった
Hadoop/Sparkはオープンソースの並列分散処理基盤で、いずれもApache Software Foundation参考1でメンテナンスされています。複数のサーバーでひとまとまりのシステム(クラスター)を構成して、単一のサーバーでは実現が難しかった数百TBや数PBクラスの大規模なデータの蓄積や、それらのデータを数分、数時間など現実的な時間での処理を可能にします。Hadoop/Sparkなどを用いずに一から並列分散処理アプリケーションを実装する場合、業務処理ロジック以外にも考えなければならないことがたくさんあります。例えば以下のような仕組みは必須です。
- 各サーバーを協調動作させるための仕組み
- 数台のサーバーが故障しても処理を継続する仕組み
- 複数のサーバー間でデータの整合性をとる仕組み
- 数台のサーバーが故障してもデータをロストしない仕組み
Hadoop/Sparkなどの並列分散処理基盤は上記のような並列分散処理特有の面倒な仕事をミドルウエアやフレームワーク側でカバーしてくれるため、並列分散処理アプリケーションを開発しやすくなります。更にHadoop/Sparkはオープンソースであり、専用の特殊なハードウエアを必要とせず、コモディティなサーバーを活用できます。またスケーラビリティが考慮された設計になっているため、サーバーを増やすことで処理性能や蓄積可能なデータ容量の増強が可能です。したがって、小規模のクラスターから運用を始めて、事業の成長に伴ってキャパシティの増強が必要になったタイミングでサーバーを追加し、大きく育てるといった運用が可能になります。このような特徴から、Hadoop/Sparkを活用することでリーズナブルな並列分散処理が可能になります。
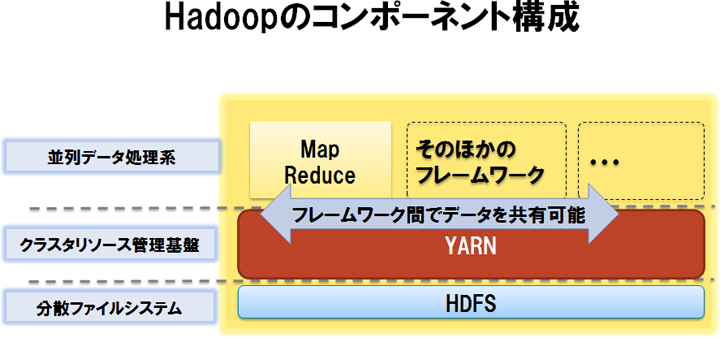
Apache Hadoop
Apache Hadoop参考2は、元々Googleが内部で利用していた並列分散処理基盤であるMapReduceとGFSに関する論文参考3、4の内容を元にオープンソースとして実装されたものです。オープンソースの実装としては、初めて商業的に成功した並列分散処理基盤であると言えます。Hadoopは以下のように、役割の異なる3つのコンポーネントから構成されています。
- HDFS(分散ファイルシステム)
クラスター全体で大きなファイルシステムを構成することで、大規模なデータを蓄積する機能を提供します。ファイルを複数のブロックに分割し、各ブロックを複数のサーバーに分散して保存するため、巨大なファイルでも蓄積可能です。またブロックあたりレプリカを3つ作成して複数のサーバーに分散して保存することで、一部のサーバーが故障してもデータが失われない工夫が盛り込まれています。ブロックサイズが128MBと一般的なファイルシステムよりも大きいこともHDFSの大きな特徴です。この特徴から、ファイルの読み出しにおいてレイテンシーが犠牲になるためランダムアクセスには不向きですが、ファイルの大部分に対するシーケンシャルアクセスにおいてスループットが最大化されます。HDFSが多くのファイルシステムと異なるもうひとつの点として、一度作成したファイルは読み込みか追記のみを許容し、ファイルの一部の書き換えができないという制約があります。この制約は、3つのレプリカ間の整合性の保証を容易にするための割り切りです。
- Hadoop MapReduce(並列データ処理系)
MapReduceと呼ばれるアルゴリズムを活用してクラスター上で並列データ処理を行うエンジンと、当該エンジン上で動作するジョブ(MapReduceジョブ)を開発するためのフレームワークを提供します。MapReduceジョブ1回で実現できるデータ処理は単純であるため、複数のMapReduceジョブを組み合わせてアプリケーションを開発するケースが多いです。Hadoop MapReduceはHDFSと組み合わせることで特に大きな効果を発揮します。各サーバーがHDFS上のファイルを並列に読み出して処理することで、ディスクI/Oを並列化した高スループットの処理を実現します。また、処理を割り当てたサーバーにデータを移動するのではなく、必要なデータが存在するサーバーに処理を割り当てることでデータローカリティと呼ばれる性質を活用する工夫も、高スループットの処理の実現に寄与しています。
- YARN(クラスターリソース管理基盤)
Hadoop MapReduceや後述するSparkなどを用いて実装されたアプリケーションの実行に際して、CPUコアやメモリーなど、クラスター内の計算リソースの割り当てを制御する機能を提供します。初期のHadoopにYARNは含まれておりませんでしたが、1万台を超えるサーバー台数でもスケーラビリティが得られるように、効率的なリソース管理を行うために開発されました。
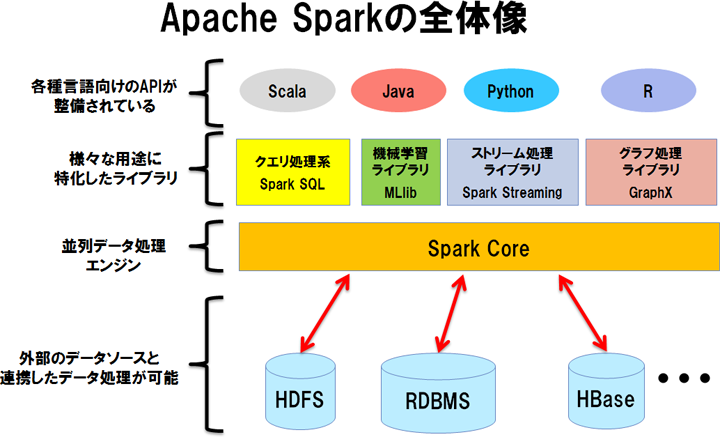
Apache Spark
Apache Spark参考5は、カリフォルニア大学バークレイ校での研究プロジェクトから生まれた並列データ処理系です参考6。クラスター上で並列データ処理を行うエンジンとフレームワークなどから構成されており、Hadoop MapReduceと似た役割を担います。Sparkが登場した背景には、Hadoop MapReduceが活用されていく中で分かってきた課題(下記(1)や(2))があります。
- (1)MapReduceジョブを多段に構成した際のレイテンシーが大きい
先に述べた通り、MapReduceジョブ1回でできることは単純であるため、複雑なデータ処理を行う場合にはMapReduceジョブを多段に構成する必要があります。しかしMapReduceジョブは1回あたりのレイテンシーが大きいため、多段に構成した場合の処理効率が良くありません。
- (2)大規模なデータを複数のMapReduceジョブ間で再利用する効率的な仕組みが存在しない
HDFS上の巨大なデータを複数のMapReduceジョブで利用する場合、都度HDFSから同じデータを読み出す必要があります。巨大なデータを何度もHDFSから読み出すのは非効率的です。
更に機械学習に代表されるような、同じ処理を反復するようなワークロードでは、上記2つの問題を両方抱えることになります。Sparkは、このような弱点を克服するために開発が始まりました。MapReduceジョブ1回あたりのレイテンシーが大きくなる理由はいくつかありますが、特に大きなものとして、MapReduceジョブ1回につき処理を行うサーバー上でJVMが起動することとHDFSへのI/Oを伴うことが挙げられます。このため、MapReduceジョブを多段に構成するとその分レイテンシーが大きくなります。
(1)の課題に対するアプローチとして、Sparkでは1回のジョブで複雑な処理が実現可能な設計になっています。Sparkでもジョブ実行時にデータの入出力にHDFSを利用することは多いですが、そもそもジョブを多段にするシチュエーションがMapReduceフレームワークを用いる場合ほど多くないため、ジョブ実行に伴うHDFSへのI/Oの機会を削減することができます。
(2)の課題に対するアプローチとしてはキャッシュが挙げられます。Sparkでは処理途中のデータを適宜キャッシュできます。これによって、複数のSparkジョブ間でデータを効率的に再利用することができます。反復処理などの実現においては、やはりジョブを多段に構成する必要があります。しかしそのような場合でも、キャッシュを活用することでHDFSへのI/Oを最小限に抑えられます。加えてSparkではJVMひとつで複数のジョブが起動可能であるため、複数のジョブ実行に伴うJVMの起動オーバーヘッドが1回で済みます。
このように、Sparkは並列データ処理エンジンも優れていますが、並列分散処理アプリケーションの開発の敷居を下げる特徴を備えていることも優れた点です。例えば以下のような特徴があります。
- リスト処理を記述するようにロジックを記述できるため、並列分散処理をあまり意識せずにアプリケーションを実装でき、しかも汎用的なデータ処理に利用できる
- 汎用的なデータ処理に利用できる一方で、機械学習やストリーム処理など、さまざまな用途に特化したライブラリが同梱されている
- さまざまなプログラミング言語のインターフェイスを備えている
- インタラクティブシェルが付属しており、処理ロジックのプロトタイピングや評価に際して、トライアンドエラーのサイクルを加速できる
比較的容易に並列分散処理アプリケーションが実装できる道具立てが整備されている点も、Sparkが昨今注目されている要因であると考えられます。
適材適所の使い分けや役割に応じた組み合わせが肝心
並列分散処理基盤と一口に言っても、その役割はプロダクトによってさまざまです。複数のプロダクトを役割に応じて組み合わせて利用することも多いです。例えばSparkの利用に際して、HDFSをストレージとして利用し、YARNをクラスター管理に用いることも可能です。役割が似ているプロダクトは、ワークロードの得意不得意やプロダクトの成熟度によって使い分けることが重要です。例えばHadoop MapReduceではアプリケーション開発の敷居が高かったり、性能要件が満たせない場合にSparkを選択する可能性がある一方で、Hadoop MapReduceとSparkのどちらでも要件を満たせる場合は、枯れたHadoop MapReduceを選択するといった判断も必要です。また単に使い分けるだけではなく、組み合わせることで得意分野を相互に補完する活用の仕方もあります。例えば処理の前段では安定性重視でHadoop MapReduceでデータ量をある程度削減し、後段では処理性能重視でSparkを活用するといった組み合わせが考えられます。
本記事では並列分散処理基盤の中でも特にHadoopやSparkについて紹介しましたが、昨今は他にもさまざまな並列分散処理基盤が登場しています。後発のプロダクトの中には先に登場したものよりも優位性を備えたものも多いです。例えばプロダクトによっては「○○よりもXX倍高速」などのように宣伝されることもあります(Sparkも、「Hadoop MapReduceより100倍高速」と紹介されることがあります)が、適用判断においてはそのプロダクトが解決を目指している問題とアプローチを理解し、謳われている優位性が発揮可能な条件やワークロードを把握している必要があります。加えて運用のしやすさや成熟度、将来性、サポートが受けられるかどうかなども考慮したうえで、冷静な判断を下すことが大切です。
更に詳しく知りたい方に
NTTデータでは、Hadoop/Sparkに関して積極的な情報発信を行っております。以下の情報も合わせてご覧頂くことで、Hadoop/Sparkの理解が深まります。







