
事後対応と未然防止
従来、システム障害に対する監視の方針は、事後対応(リアクティブ)が主流でした。閾値監視などによって問題が発生したことを検知し、事後的に復旧対応を行うというものです。そのため、監視技術の多くが、リソースの使用状況や内部の処理シーケンスといった「情報の可視化」に重点を置いてきました。
しかし現在、さまざまな種類の障害の未然防止(プロアクティブ)を可能にするための監視が検討されています。その中で、性能問題(スローダウン)の予兆検知技術について解説します。
性能問題に予兆はあるのか
そもそも、システムがスローダウンする際、その予兆は何らかの計測できる指標として把握できるのでしょうか。それができなければ、予兆検知は夢物語です。
実は、それが難しい種類のスローダウンもあります。これは、システム内で実行される処理ロジックが状況に応じて動的に組み替えられる仕組みを採用しているケースで、このパターンにおいてはロジックが変動する契機を完全に特定するのは難しく、事前検知はかなり困難です。こう書くと特殊例だと思われるかもしれませんが、現在一般的に利用されているリレーショナルデータベースは原則としてこのような仕組み(実行計画の動的最適化)を採用しています。
この種のスローダウン予防は、別の手段によって実現する必要がありますが、本稿の主題ではないので割愛します。
予兆をつかむ – 長期トレンドの把握
一方で、ある特定の指標が、スローダウンの発生前に特徴的な変化を見せるタイプもあります。たとえばプログラムで使用するメモリの解放漏れによって発生する「メモリリーク」起因のスローダウンはその典型です。メモリリークは、「leak(漏れる)」という名前のとおり、少しずつメモリが消費されていき、最終的にはメモリが枯渇することによって、大規模な遅延が発生したり、悪いときはシステムダウンによる大規模なサービス停止を引き起こします。
メモリリークが発生する場合、メモリの使用量は、図1または図2の2パターンの増え方をします。図1のように単調増加する場合と、図2のように解放と蓄積を繰り返しながら増加していくケースがありますが、どちらも長期的に見れば上昇トレンドを示します。

図1.メモリ使用量の増加イメージ(単調増加)

図2.メモリ使用量の増加イメージ(増減を繰り返しながら増加)
サービスを運用する中で業務量や蓄積データ量が増加することで緩やかに性能劣化が起きるケースも、このケースに該当すると言えます。従来の閾値監視だけではすでに手遅れの状況になってからしか問題を把握できなかったのに対し、上昇トレンドを早期発見することで未然に防ぐことが可能になります。
予兆をつかむ – 異常値の検出
リークのように、経験からスローダウンを引き起こすメカニズムが明らかになっている場合は、ある特定の指標に対する検知ルールを実装することで予兆監視が可能です。しかし、現在のシステムはハードウエアもソフトウエアも複雑化しているうえ次々に新しい技術や製品が登場するため、事前に遅延のメカニズムを予測することが困難なこともしばしばです。いわば、”新種”の原因が次から次に生み出されている状況です。
そのような場合、実装すべきルールが不明なので、別の手段を考える必要があります。現在私達が検討しているのが、複数の指標の相関関係を分析することによる異常値検知です。もともと統計の分野で考案された相関分析は、因果関係のメカニズムが明確でない状況において、因果関係の存在を推定するための手法であるため、スローダウンの検知のような問題にも応用できる可能性があります。
通常、性能に関連する指標──たとえばユーザアクセス量とサーバのCPU使用率──というのは、ある程度の相関をもって連動します。その相関関係から得られる情報を特徴量として、システムが正常稼動している時の特徴量を学習させたうえで、そこから外れるものを異常として検知するという仕組みです。
この特徴量の作り方は、相関関係から得られるものに限定されるものではありません。また、指標の選択についても、二つとは限らず、三つ以上の指標を利用することも考えられます。
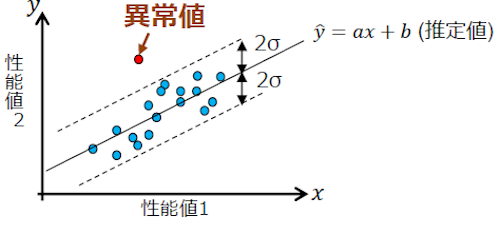
図3.二つの指標における異常値の検知
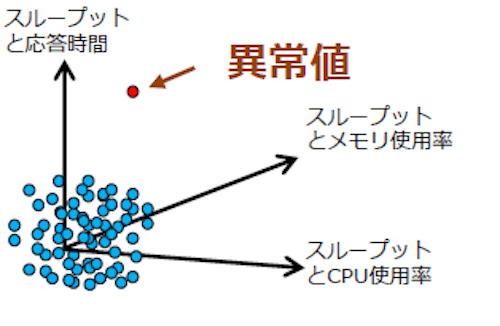
図4.三つの指標における異常値の検知
特徴量の選択も含め、機械学習を使った手法がスローダウンの予兆検知に利用できるかどうかは、まだ実験段階であり、今後さまざまな実際のデータを適用して有効性を検証していく必要がありますが、有望な道の一つであると期待しています。現在、機械学習による異常検知の性能データへの応用については、NTT ソフトウエアイノベーションセンタ(※1)と協力して、JubatusやLognosisなどの分析フレームワーク(※2)の応用可能性を模索しています。
・Jubatus
http://jubat.us/ja/
・Lognosis(統合ログ分析技術)
https://labevent.ecl.ntt.co.jp/forum2016/elements/pdf_jpn/02/A-22_j.pdf







