
意味が「わかる」とはどういうことか
人間の知能を支えるもの
新井 私が「ロボットは東大に入れるか」というプロジェクト(※1)を始めたときに人工知能学、特に言語処理の方面から「何でこんな役に立たないことをするのか」という批判的なご意見を受けました。そんな中、長尾先生が「それは今やるのはなかなか面白かろう」と、言語処理学会の記念大会などに私を講師として呼んでくださったのが印象に残っています。
長尾 でも、それから4~5年のうちに東ロボをおやめになった。「もうちょっとやったら面白いところまで展開するのでは」と思っていたので、それが残念です。
新井 いえ、まだプロジェクトはやめていないのです。毎年11月の発表会をしばらく休んでいるだけで、それぞれの科目でまだ続けています。特に、数学がEnd to End(※2)で偏差値75の成果が出たのは、自分としてはこのプロジェクトの成果だと思います。長尾先生も自動証明の本を翻訳されているので、その困難さをとてもよくご存じだと思います。

(左)長尾真(ながお・まこと)/京都大学名誉教授。元京都大学総長。国立国会図書館元館長。1936年生まれ。1959年京都大学工学部電子工学科卒業。73年京都大学工学部教授、89年日本認知科学会会長、91年機械翻訳国際連盟設立初代会長、94年言語処理学会設立初代会長、97年第23代京都大学総長、98年電子情報通信学会会長、99年情報処理学会会長、01年国立大学協会会長、04年情報通信研究機構初代理事長、07年国立国会図書館館長。
(右)新井紀子(あらい・のりこ)国立情報学研究所 社会共有知研究センター センター長、同 情報社会相関研究系教授、一般社団法人 教育のための科学研究所 代表理事・所長。一橋大学法学部およびイリノイ大学数学科卒業、イリノイ大学大学院博士課程を経て東京工業大学より博士(理学)取得。専門は数理論理学。2011年より人工知能プロジェクト「ロボットは東大に入れるか」プロジェクトディレクタ。16年より読解力を診断する「リーディングスキルテスト」の研究開発を主導。
長尾 自動証明は1960年代初めからアメリカで言われていたものですが、人間の知能と関係していると感じられて面白かったです。私はLISP(※3)というプログラム言語が大好きで、いろいろと実験したことがあります。
新井 私も最初に作った自動証明機をLISPで動かしました。
長尾 ああいう言語は、今でも大学できちんと教えたほうがいいと思います。人間の知能を支えているのは、論理的で数学的なものであると思いますから。
新井 ええ。Python(※4)ばっかり教えていないで、ですね。
長尾 LISPで書いた自動証明プログラムを元に、生徒が証明するプロセスをチェックするシステムを作ったことがありました。数学の定理を証明するときや数学の問題を解決するとき、人間はどこかで間違えます。そのとき「定理証明機」が人間のやっている証明プロセスをパラレルにチェックしながら、「あなたはここで間違えましたよ」とか「これはこういう定理の適用の仕方を間違ったのではないですか?」と聞くんです。
この研究をもっと深めていくと、人間の理性的な推論プロセスというものを深く認識できるのではないかという気がしていましたが、残念ながら途中で中止してしまったんですね。
書いて、話している言葉の曖昧さ
新井 「ロボットは東大に入れるか」というプロジェクトは、「今のAIというものが、現実の18歳の人間に比べてどういうところでは凌駕しえて、どういうところは逆に厳しいのか」を一つひとつ浮き彫りにすることができると思って始めたものです。
例えば、数学の問題。自然言語文で書かれたものに関して、機械が読める形式に翻訳するのは、実は機械翻訳と同じですね。ただ、今あるような統計的な機械翻訳ではなく、辞書をかなり大量に書いてやらないといけないタイプの機械翻訳をしたのです。
それに対して構文解析などでは、ある程度の統計的な処理をしないと「こういう構文木(※5)ではないか」というものが出てきませんので、一部に統計的手法も用いました。それで辞書を数万の単位で書き、今に至ったんです。こうした辞書を整備しないと、人間には「これくらい当たり前だ」と思われるような文でさえ、AIには正確に翻訳できないのですね。
この例と、長尾先生が提唱されている「産業日本語」(※6)には、ある意味で共通するものを感じました。「産業用にすぐプログラミングできるようきちんとした形の自然言語文で書くのであれば、こういう風に書いてくれないと困る」とか「あるシーンだとこういう風に書いてくれないとすぐに仕様にならない」という問題意識と通底すると感じたのです。

長尾 人間が書いたり喋ったりする言葉は曖昧で解釈の余地もあるし、いろいろ振れるから、正確性を期すためには「明確性を持った表現は何か」ということを、もっとハッキリさせていかねばならないのは事実です。例えば、フランスのアカデミーなどは「フランス語として正しい表現はこういうものであるべきだ」という、ある種の言語に関する規範、モデルを規定しています。
日本語の場合、国立国語研究所などの機関がある程度そういうことを規定してくれると期待していたのですが、実際はそうはならず、「この言葉は現在自由に使われていて、いかようにも解釈できる」とか「いろいろな単語で意味がどんどん拡張したり変遷したりしていく。そのことを是認する」といった世界に留まっています。
果たしてこれが良いのか悪いのか。そういう言葉への姿勢が日本人のキャラクターを表現しているという点では良いかもしれませんが、ロボットにとってこうした曖昧さは一番悩ましい点です。
新井 そうですよね。
長尾 新井さんの本にも、佐藤さん(※7)の言葉として「東大入試の問題のほとんどは、うまく定式化すれば数式処理で解ける。ただし、自動で『うまく定式化』できるとは思えない」(『AI vs.教科書が読めない子どもたち』(※8)p.60より)と書かれていたけれど、まさにその通りで「いかにクリアにできるか」がロボットにとって必須であるのに対し、人間の言語というのは全く逆です。

証明は機械にやらせればいい
新井 ご存知の通り、私は元々の専門が数学基礎論なので、フレーゲから始まり(※9)、ヒルベルトやラッセル、あるいはタルスキといった流れの中にいたわけです。今、先生がおっしゃったことは、まさにフレーゲやラッセルが持っていた問題意識と非常に近いと感じます。彼らは「数学の基盤をきちんとするために、人間の話す言葉、数学で使う言葉を整理していこう」とする流れを生みました。
それがまさに今日のコンピュータや人工知能、自然言語処理へと繋がったわけです。フレーゲやラッセルは、哲学者であり、数学基礎論の創始者でもあり、現代言語学の始祖でもある。そのような多義性を持って生まれたものが、現在にも通用する議論だったと思います。
長尾 確かにそうです。

新井 これまでの長尾先生のお仕事を見ていった場合にも、そうした多義性があるという感想を私は持っています。人工知能の初期のことであるとか、第五世代コンピュータ(※10)というようなロジックの流れは重々承知されていながらも、日本で最初に統計的あるいは確率統計的な方法で、人工知能的な問題解決をなさろうとお思いになったのが長尾先生でした。
例えば、初期に手掛けられた「郵便番号読み取り装置」(※11)のお仕事。あれは社会に対して非常にインパクトのあるお仕事でした。手書きの数字の教師データを使ったものだと思うのですが、今の画像認識やパターンマッチングに繋がるような統計的な手法でなされていらっしゃいました。
次に「かな漢字変換システム」を作られましたよね。かな漢字変換のない時代は、大きな箱から植字を探すようなことをしていましたが、キーボードの中で日本語を書けるようになりました。少数民族が使う言語をお救いになったというご功績が先生はおありになる。まさに言語モデルというか、マルコフ過程を上手にお使いになったということですよね。
先生は数学のマルコフ過程というものを大変に勉強されて「あ、これだったらいけるんじゃないか」とお思いになられたと思うのですが、その頃の気持ちはどのようなものでいらしたのですか。つまり「統計」や「確率過程」に注目しようとお思いになった理由を知りたいです。
長尾 公理系があれば、そこからいろいろな形で定理が導き出されるから、これらは「人間が考えなくてもいいことではないか」と思ったのです。数学者の方々に言うと叱られるので、あまり言わないのですけどね(笑)。つまり「証明は機械にやらせればいい」と。それより、世の中には定理証明のプロセスでは解決できないような問題が山ほどあるに違いないから、人間がそれに取り組むためには、機械は何をやったらいいのかと考えたのです。
その着想があって、厳密な定理証明みたいなものでなく、曖昧性のあるものを扱うには、統計とか確率とかマルコフ過程などを用いて物事をモデルにして扱うことが必要ではないかと感じました。かな漢字変換もそういうことです。マルコフ過程で最も確率の頻度の高いところに飛んでいくような仕組みですね。
新井 普通だと変換候補を一から順番に出してしまうところを、マルコフ過程を使って「この直後だったら多分これだろう」とか「この人だったらこれだろう」と出すのは、本当に画期的でした。そういうユーザーインターフェイスに対する勘どころのようなものも先生は押さえていらっしゃる。その落としどころとか勘どころとかが、技術者ぽくないと言ったら変ですが、非常に多義的だと思うのです。
一期一会の状況は、統計にはない
長尾 人工知能という言葉は1950年代くらいに作られたものです。当時、アメリカなどを中心に「コンピュータは万能である」と言われていました。私が一番興味があったのは「コンピュータが人間の頭脳に取って代わるとは言わなくても、人間にどこまで迫れるか」ということでした。
機械翻訳にまず取っ付いたのは、言語というのは人間の特徴を現す最たるものであるから、その頭脳の中で言語はどう操られているかがわかれば「人間がわかった」ということに繋がっていくだろうとチャレンジしたのです。
しかし、工学部の人間としてそのことに取り組んでいるだけでは、20年、30年、40年経っても何の社会貢献もできない。基本的な問題にチャレンジしながら、社会に対してその時々にどのように貢献していけるかを考えていました。
新井 長尾先生は『「わかる」とは何か』(※12)という著書で「意味」のお話をお書きになっています。機械翻訳の場合、記号列どうしの直接の対応関係を考えればよいということなので、意味の部分を実はバイパスして(省いて)しまっていますよね。
長尾 そうですね。

新井 統計的に落としどころのある意味にしていくと、やはり「一期一会」の会話を機械翻訳するのは難しいと思います。例えば、先生と今日お話しさせていただいているのは、おそらく一期一会です。先生もこれより前に似たような内容をどこかでお話しになったかもしれないですけれど、今日は私のためにチューニングして、多分いつもと全く同じことはお話になっていらっしゃらないと思います。私も今日は長尾先生がお相手だと思い、覚悟を決めてお話をさせていただくので、こうやって誰かに一度も話したことがないようなことをお話しするわけです(笑)。
そうした一期一会の会話では「統計の中にはこの文はない」ということがあったとしても、二人だからわかることがあります。フレーゲであったり、マルコフ過程であったり……二人だとわかり合える話題なので、途中を省きますよね。
けれど、Google TranslateやVoiceTra(※13)だと翻訳し損ねるかもしれない。それらはスパースですからね。スパースな事象のモデリングに失敗して、どれが固有名詞かどうかもわからないという事態は面白いなと思います。
長尾 ヴィトゲンシュタイン(※14)などが言うように「言葉というのは場面に従う」と。あるいは「場面で解釈しなければ言葉の意味は定まらないのだ」という世界を、これからどういう風に築いていけるかですね。そういうことをもっと真剣に考えないとダメじゃないかと思います。
新井 「明けの明星」と「宵の明星」というのは、どちらも同じ金星を指しているわけです。でも、2つが同じ意味かというと違う。そういう「場面と状況における言語」というのが、今はどうしてもコンピュータで処理する際に抜けています。そうしたところが、機械翻訳とか「東ロボ」を通じて残された問題として明確になってきたと思います。
長尾 ロボットの世界でも、言語を解析して翻訳するとか、東大入試の問題の文章を解釈するとか、文字や画像を認識するとか、作業をするロボットとか、いろいろ開発されていますけども、いずれも不十分です。
それをもう少し「人間らしいロボット」にしていこうとするなら、人間の持つ五感にあたるようなものをその都度取り入れ、統合的に解釈して、何かの仕事をするとか、判断するという機能をまず持たせないといけない。言語や画像の認識だけでは解決できない問題が山ほどあるわけです。
これからのロボットの研究というのは「トータルな世界へいかにチャレンジしていけるか」になるでしょう。ドメイン(領域)を広げて、人間が住んでいる世界と同じようなドメインでロボットがどこまで勝負できるかという段階に入って来つつあると思うんですね。
新井 数学の側から言うと、今のコンピュータはどこまで行っても計算機なので、「じゃあ、どうやって私たちが住んでいるこの空間、世界のデータを取りますか」と言ったとき、結局は数値データになってしまうのです。私たちの日常を膨大にセンシングして、IoTと言われているような装置でビッグデータが集まってきたとして、その数値をどう解釈すべきか。「わかる」ということが統計的手法ではまずかろうという感じがします。
一期一会の状況というのは統計にはないと思ったとき、今ある言語としては「論理」と「確率」と「統計」しかないものですから、数学者として申し訳ないです。どうやってセマンティクス(※15)に、つまり「わかる」というところに接地させていくのかが難しい。でも、それが間もなく必要になることは皆が気づいている状況だと思います。
1980年以降細分化された人工知能分野を再統合することで新たな地平を切り拓くことを目的に、2016年度までに大学入試センター試験で高得点をマークすること、また2021年度に東京大学入試を突破することを目標に、国立情報学研究所(大学共同利用機関法人 情報・システム研究機構)が中心となって研究活動が進められているプロジェクト。
https://21robot.org/
情報通信分野では「二者間を結ぶ経路」を言う。終端間。ここでは「端(問題文)から端(解答)まで」との意味。
プログラム言語のひとつ。他のLISPプログラムを処理するように書くというメタプログラミングが可能であり、言語自身の機能をほとんど際限なく拡張することが可能。多くのLISP方言ができたため、それらを一つに統合するために設計されたプログラム言語としてcommon Lispが生まれた。
ディープラーニングに適しているため、近年では人工知能用プログラムを作る際に使われることが多いプログラム言語。
構文解析の経過や結果をツリー構造であらわしたもの。単語のみに基づいた文の構造を利用しない翻訳では誤訳が多くなるが、構文木に基づく翻訳では入力文の構文情報を利用することでより正確な翻訳ができる。
産業・技術情報を人に理解しやすく、かつコンピュータにも処理しやすく表現するための日本語。
東京理科大学の佐藤洋祐教授。新井教授にとって数学基礎論分野の先輩になる。
・ゴットロープ・フレーゲ(Frege):ドイツの論理学者、数学者、哲学者(1848-1925)。
・ダフィット・ヒルベルト(Hilbert):ドイツの数学者(1862-1943)。「現代数学の父」と呼ばれる。
・バートランド・ラッセル(Russell):イギリスの論理学者、数学者、哲学者、社会批評家、政治活動家(1872-1970)。
・アルフレト・タルスキ(Tarski):ポーランドおよびアメリカの数学者、論理学者(1901-1983)。「4人の偉大な論理学者」の一人。
述語論理による推論を高速実行する並列推論マシンとそのオペレーティングシステムを構築することを目的に、1982年から1992年にかけて、当時の通商産業省(現経済産業省)が取り組んだ国家プロジェクト。
正式名称は、郵便番号自動区分機。1965年に郵政省指導の下、東芝で区分機開発のプロジェクトが編成されて開発が進められた結果、67年にOCR(光学文字読取技術)を使った世界初の手書文字読取試作機(TR-2型)が完成した。
https://www.postalmuseum.jp/column/collection/post_27.html
国立研究開発法人 情報通信研究機構(NICT)の研究成果である音声認識、翻訳、音声合成技術を活用した、多言語音声翻訳スマホアプリ。
オーストリア出身のイギリスの哲学者(1889-1951)。言語哲学や分析哲学に強い影響を与えた。後期の著作『哲学探求』で提唱した「言語ゲーム」の概念でも知られる。
シンタックスがデータの「形式や構造」を指すのに対して、セマンティクスはデータの「意味」を指す。
情報工学者は、哲学や心理学に学べる
機械と人間の根本的な違い
新井 人工知能を「わかる」というところへ、いかに接地させるか。どれだけ遡って考えても、なかなか答えが出てこないです。最適化のような事柄はいいんですよ。「目標があって、これが正しい」というのが決まっている事柄は、勾配法(※1)などで目的まで持っていけますから。こういう最小原理みたいなものはいいんです。
でも、数値の最適化でないようなものに関しては、一体どうすればいいか。例えば「正義」の問題があります。テロや犯罪が起こった。そのときに誰が、どう行動すべきか。こうした正義の問題は、統計的に滅多にないことなので、「どうすべきか」という答えは、なかなかわかり辛いことだと思います。
長尾 そこは難しいところですね。ある種の「価値観」をコンピュータプログラムに入れたとしても、その価値観がオールマイティーなのかわかりません。客観的世界の話で済むのかどうか。人間の場合、厳密に言えば「客観的世界というのがない」わけなので。
新井 そうなんですよね。厳密に言うと客観的世界に人間は生きていない。
長尾 やっぱりそこのところが、ロボットというか、機械と人間で根本的に違うところです。
新井 「赤ちゃんみたいなロボットを作り、センシングができて、重力の環境下で、みんなが語りかけるような中で育ててみれば人間と同じになる」というご意見を持たれる方もいらっしゃいます。でも、それによって個体発生はシミュレートできるかもしれないけれど、系統発生(※2)はどう扱えばいいのかと私は問いたいです。
タンパク質からミトコンドリアになり、類人猿になって、ホモサピエンスになって、今日この高いビルを作った文明社会の中に私たちはいます。そこの「ずっと長い記憶、何世代、何億年、何十億年と掛かってきたこの記憶、埋め込まれている記憶」に関してどうしたらいいのかが全然わからないんですよね。

長尾 今後のロボットの世界でやるべきことは、人間が歴史的にずっと蓄積してきた文明のあらゆる情報をコンピュータの中に入れる方法を探り、それらをうまく利用する方法を考えることではないでしょうか。それを実現しないとどうにもならないところにまで来ているように思えるのです。
いわゆる国語辞典とか、百科事典のような単項目の辞書を作るだけではなく、項目ごとの相互関係性、言うなればシソーラスであるとか、「何と何との関係はどうなっているか」という関係性までを入れた全世界の知識というものを、いかにして構築していけるのか。そういう大問題にぶち当たっていると思うのです。それが人間の手ではなかなか記述できないから、自動的に作るしかないわけなんですが……。
新井 自動的に作られたものが、なぜ正しいかがわからないというのも難しいところですよね。
求められる新しい数学モデル
新井 現在の第三次AIブームと言われている現象に対し、私は不安に思うところがあります。それは、数学で提供できている言語が、今のところは論理と統計と確率しかないということです。ホモトピー(※3)というまだ使えていない分野はあるのでもう少し可能性はあるかとは思うのですが、具体的に今すぐに使えるものはその辺りまでなので。
第二次AIブームまでで「論理」は使い尽くしました。そのとき積み残したものを第三次AIブームでこれから「統計と確率」「ビッグデータ」でやり尽くすでしょう。そこでさらに積み残したものは、数学がもう一歩前進して、新しい「言語」を提供しない限り、打ち手がなくなってしまうのではないかと不安です。
長尾 今後は強力な数学モデルがないと人工知能は発展していかないですよね。そこが大問題です。
新井 第二次AIブームのとき、第五世代コンピュータが失敗したのは大変残念でしたが、あの時は長尾先生がいらしたので、すでに90年代に向けて統計と確率という「芽」が出ていました。
今回の第三次AIブームの後にも、必ず課題が残ります。その課題に対して「意味」の解釈がないと乗り越えられないとしたとき、今の数学にして差し上げられることが極めて限定的ではないか、というのが率直な気持ちです。
長尾 世界中の知識というのが何百万かあるとして、その知識というのは相互関係で結び付いているわけです。さらにその相互関係の枝にも何百種類かあって、そういう世界で知識というものが壮大で複雑なネットワーク世界を構成しています。
そういうものの全部は人間一人の頭の中には入らないけれども、人間はそれらをうまく使って質問応答をするとか、判断をするとかしている。そういった複雑な、意味を担うブランチを持った立体構造みたいなものを数学的にマニピュレーションできるような、そういう数学理論は生まれないのでしょうか。トポロジー(※4)だと単純化され過ぎてしまうかもしれませんが。
新井 今のお話から想像することが2つあります。1つ目は現実的な話ですが、それだけ大きなネットワーク構造を計算しようと思うと、ものすごくエネルギーが掛かるはずですよね。しかし、脳はエネルギーを使わずになぜそれができているのか。仮にその数理モデルを作ったとしても、それが正しい数理モデルと言えるのかというのがまず1点。
長尾 うん、うん。
新井 2つ目は、その複雑なネットワーク構造の計算を、脳がそれほどエネルギーを掛けずに行うことができる要因は、ホモトピー系ではないかと思うところがあります。きっと先生も感じていらっしゃったと思うのですが、完全一致なものは怖くないのです。「似ているとは何か」という数量モデルが一番怖い、というか難しい。多義的ですし。
例えば、子どもが絵本でキリンを見て、その後、動物園に行って初めて本物のキリンを見たときに「あ、キリンだ!」と言えるのは、本当に不思議なことです。それをネットワークで数理モデルにするにはどうすればいいのかが今はわからない。
長尾 まったくおっしゃる通りで、「似ている」というのは、脳のニューラルネットワークにおける基本的な機能ではないかと思っているんですよ。類似性ということを基本に置いて、すべての人間における頭の働きを説明できる可能性があるのではないか。完全一致や論理的推論などよりも、類似性を見出せることこそ人間の頭脳の根本的な働きではないかと思います。私は死ぬまでに『類似性とは何か』という本を書きたいです。

新井 ぜひ読みたいです。私自身も「忘れる」と「似ている」、この2つが脳で重要なことのような気がしています。真面目に本気でプロジェクトをやった人は、絶対に「“似ている問題”というのが本質だ」ということに気付いているはずです。
数学をやっていないか、プロジェクトを不真面目にやっている人は、「数理モデルで『似ている』というのは処理できます、ベクトルで測ればいいんですよ」などど安易におっしゃるんですね。でも“似ている問題”というのはプロジェクトをやったり数学をやったりすると必ず最後に戻ってくる一番大きな問題です。
長尾 数学でもそうですか。
新井 構造が同じという話です。数学で構造が同じというのは、ホモトピーとか、アイソモルフィック(※5)のような形で処理したり、分類したりしますよね。でも、人間はそのずっと前に「分類しよう」と思う時点があるわけです。「それが形になる『前に』なぜそう思えるのか」がわからない。
長尾 その“似てさ加減”には、言葉の表現の“似てさ加減”とか、『AI vs. 教科書が読めない子どもたち』にもありますが、猫とか犬の“似てさ加減”とか、いろんなものがある。それらを個別で考えると、多分40~50くらいの“似てさ加減”の基準があれば、かなりいろいろな現象が説明できるのではないかと以前から考えていました。それをコンピュータの世界に何とかぶち込めないか、と大それたことを空想しています。
新井 長尾先生と話していて、はっとするのは、「40~50」という具体的な数字がパッと出てくるところですね。それほど根拠があっておっしゃったわけではなく「人の持つ“似てさ加減”はこのくらいの数ではないか」という直観に基づくものだと思います。そこが長尾先生のお人柄としてすごくユニークです。普通、40~50などと思い切って言えないところだと思います。
長尾 言葉における“似てさ”と、画像における“似てさ”では少し尺度が違いますが、そうした違うドメインにおける“似てさ加減”を考えていくと、数十程度でいろいろな現象や社会の解釈はできるのではないかということです。
その“似てさ加減”の根本にあるものとは何かは、さらに考えなければいけないと思っているところです。でも、なかなかそこまでは考える力がありません。それが数学の世界でモデルとして作られると非常に面白いし、強力なものになるでしょうね、きっと。
機械の方だけ見ていてはいけない
新井 先ほど、先生から「東ロボを5年で1回凍結したのは大変残念」とおっしゃっていただきましたが、実は「人間が犯すエラーを分析しないと、この先には進めないだろう」と思ったのです。今までAIがベンチマーキングをするとき、教師データは常に「正しい」と思ってベンチマーキングしてきましたよね。でも、教師データは本当に正しいのか。「人間がこんなにエラーを起こすのはなぜだろう」と思ったのです。
そこで「リーディングスキルテスト」を独自に開発して始めました。このテストによって、1〜2文程度の短い文章を人に見せたとき、意外に人が「読めていない」という事実がわかりました。「人はどういったエラーを起こすか」「どれくらいの能力の人はどういうエラーを起こすか」ということの方をまず解明しないと、人工知能の研究を前に進められないと確信したんです。
長尾 なるほどね。
新井 例えば「Alexは男性にも女性にも使われる名前で、女性の名Alexandraの愛称でもあるが、男性の名Alexanderの愛称でもある。Alexandraの愛称は○○である」という短文をテストで出しました。この○○に当てはまるのは「Alex」と決まっているのに、「女性」と答えた回答者が半分ほどいたという結果になりました。つまり、構文解析ができないという人が半分もいる。
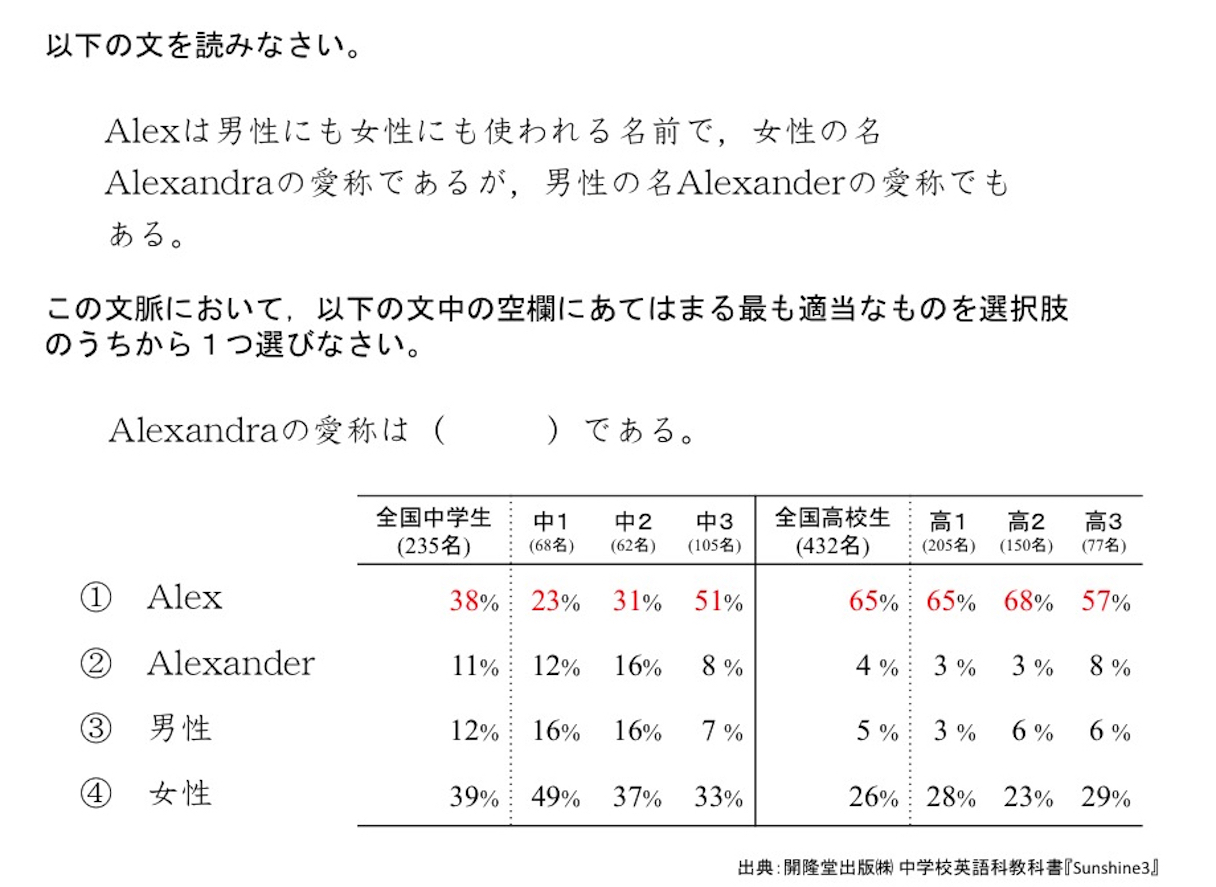
今のAIなら、この問題は構文解析で間違いなく解けると思うのですが「なぜ人は半分も間違えるのだろう」と思ったのですね。「こんな短い文を構文解析できないのに、なぜ『読めている』と本人は思い、人と話せているのか」と。単に「読めないからダメだ」と言いたいのではなくて、この人たちがそれなりに支障なく社会生活を送れている。「このように人間というものはエラーを起こすのに、なんとレジリエント(※6)に生きているのだろう」と。
長尾 それは非常に不思議なことです。
新井 人間のエラーの方を見ず、工学的にAIだけを研究する方法論もあったと思います。ですが、私は「人間のモデルを作るのであれば、人間のエラーを一度しっかり見てみよう」と思いました。
それが『AI vs.教科書が読めない子どもたち』という本の後半に書いたことです。人と機械が協調する社会を作るうえでも、また「機械とは何か」「人間とは何か」を極めていくうえでも、機械の方だけを見ていては……。
長尾 ダメですよね。心理学的に人間の心の動きというか、その時々の心の動き、あるいは対話をしていたときの意図。そういうものがどういう状態にあるからトンチンカンな答えを出すとか、もしくは正しい答えを出すとか、対話が成り立っているとかがあります。
人間の心の動きと、大脳皮質における論理的推論の結果で反応するというのは、実はものすごく複雑に絡んでいる。そういうところの解釈をもっとうまくやらないと結果が出て来ないと思うのです。
新井 脳科学として非侵襲な形で光トポ(※7)とかMRIとかで取る方法もありますが、それだけだと観察としても、測定としても、おそらくは足りません。文のほうを自然言語処理的に分析したらわかるかというと、それでも足りない。問題文の表層的な特徴量からリーディングスキルテストの問題の難易度を予測しようとしたのですが当たらない。なぜか全員が解ける問題がある一方で、半分の人しか解けない問題もあって、その差が生じる理由は何なのかが、よくわからなかったりするのです。
そういうエラーをまず観測する、それが一つの重要な方法だと自分では思っています。リーディングスキルテストというのは、読解力テストとして社会還元もするのですけれど、実は「人間を観察する高度な装置でもある」と捉えているのです。
長尾 なるほど、そうでしょうね。そこのところが一番キーポイントだと思いますよ。
情報科学者は何をすべきか?
新井 こういうことを言ってわかっていただけるのは、長尾先生くらいしかいません。誰もなかなか意図を理解してくれないんですね(笑)。表面的な言葉の解釈とか、あるいは機械翻訳などはディープラーニングで学習させればさせるほど精密にするとはできますが、言語はそれだけではないですから。
長尾 言語は感情も表現するし、相手が言ったことに対するレスポンスも担っています。その仕方も、その人のその時におけるメンタリティーとかいろんなことによって違う。
そういうトータルな頭脳の働き、つまり「理知的な部分」と「意味の部分」がある。意味の部分になってくると、頭の中だけじゃなくて、その時の周囲状況にも拠ります。その意味を支えているところに、やはり心というか、その人の頭脳のもっと深層的なもの、さらにその時のメンタリティー、テンデンシーというものがある。
理知的な部分、意味の部分、心の部分。この3つの層がうまくかみ合って動いている、そういうモデルをもってくる必要があるのではないかと思っています。だけど、これはなかなか難しい。
新井 ええ、難しいです。哲学としてモデルを考えることは可能かもしれないのですが、数理モデルとして作るというのがなかなか難しいんですね。
長尾 哲学として考えた場合、フッサール(※8)の現象学でも、まだ頭脳の上の方、論理的構造の部分から「意味」の世界にちょっと入ったくらいのところにある心の動き、心とか魂と言われているようなものが頭脳全体を大所高所から支配しているというモデルは構築されていません。そういうものをうまく検討する必要があると思います。
新井 今の若い人というのは、もうTensorFlow(※9)のような便利なツールが最初からあって「それでPythonでこう書けば、こうディープラーニングできます」という環境がありますので、フッサールとかラッセルとか誰も知らないんですよ。
長尾 いちいち考えなくてもいいですからね。
新井 ええ。でも、本当はデカルトから始まる話なので、デカルトの『方法序説』とホッブスの『リバイアサン』は読んでもらいたいです。そこから、ずーっと同じことを何周にも渡ってやっているのですから。
長尾 私はもう実験とか、コンピュータをいじってプログラムするということはできなくなっているので、情報科学の分野の人にどのように貢献できるかを考えています。そこでプラトンやアリストテレス以来の西洋哲学の辿ってきた道を見てみると、その中に情報科学的な事柄に携わる人がちゃんと知っていなければいけないことが結構、含まれているんですね。
情報科学をやる人に対して「過去の人類の知能の蓄積として、哲学の世界ではこういうことが論じられてきた。そのあるところは情報科学の課題だとこの辺りに当たるのではないか」と、そういう勉強を皆さんにしてもらいたいな、と思っています。
科学技術の発展は独自に連綿と流れてきたことは事実ですが、それに類する思想的なことは、哲学の人たちも同時によく考えてきているわけです。あるいは心理学です。それらを踏まえ、工学者が「何をやらなければならないか」をもっと考える必要があるんじゃないかと思うんですね。
新井 素晴らしい結びのお言葉をいただきました。今日は本当にありがとうございました。

多変数関数の極大または極小点を求めるのに、関数の等値線に直角な方向に変数を変化させていく方法。地図上の等高線に直角な最も急勾配な方向を辿れば最短距離で山頂に到達することから「勾配法」と名付けられた。
個体発生(個々の動物の発生過程)の対義語で、その動物の進化の過程を意味する表現。ともにドイツの生物学者であり哲学者の、エルンスト・ヘッケル(1834-1919)が提唱した。
組合せおよび代数的トポロジー(後述)における重要で基本的な概念。正確ではないがわかりやすく言えば、例えば「ドーナツとマグカップは形が同じ」とする見方や考え方のこと。
位相幾何学。正確ではないがわかりやすく言えば、点と線と面を考察対象とするが長さや面積は考察対象には含めない幾何学。
数学における同型写像であることを指す形容詞。
立ち直りの早い、快活な、弾力性を持って溌剌としている様。
光トポグラフィの略、近赤外線を利用して脳内の血流変化を測定する装置。
オーストリアの哲学者、数学者(1859-1938)。数学基礎論の研究者として出発、その後は哲学に専攻を変更。「現象学」を提唱したことで知られる。
Googleが開発しオープンソースで公開している、機械学習に用いるためのソフトウェアライブラリ。







