

――ビッグデータがトレンドワードとして登場してから久しいですが、土橋さんはこの分野にどのように関わっているのでしょうか?
私はシステム基盤を専門にしていて、現在は大規模データ活用の基盤と方法の研究から、NTTデータの各部署と連携したシステム開発支援まで、幅広い業務を担当しています。最近では、ストリームデータ活用やAI・機械学習の応用という、近い将来あらゆるシステムに組み込まれる可能性が高い仕組みの研究開発と提案を行っています。
――大規模データの活用にはなにか特別な考え方やツールが必要なのでしょうか?
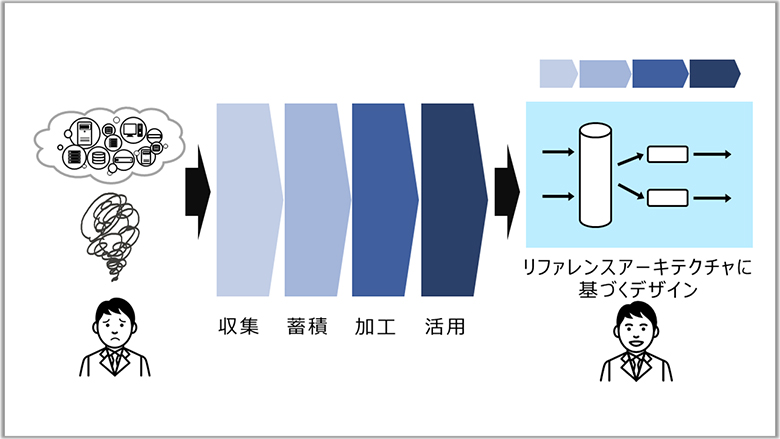
企業や組織で大規模なデータを取り扱おうとして「そもそもどこから手を付けていいのかわからない」状況に陥ってご相談を受けることがあります。
データをうまく活用しようと思ったとき、技術的な解が1つしかないというケースはほとんどありません。逆にいろいろな技術を使うことができ、選択肢があるからこそ悩むことになります。
そんな時に意識するのは、なぜその技術は生まれてきたのか、どういう経緯があり、どういう成り立ちで、どこまでできるのか、という観点です。
大規模データ活用基盤の知見を生かして、ミドルウェアや基盤の技術的背景や成り立ちを踏まえ、お客様の目的や要望にあわせてアーキテクトするのも私の役割です。技術の内部仕様の知識は、実はシステムのグランドデザイン検討にも有用なのです。
――大規模データ活用基盤を採用した事例にはどんなものがありますか?
例えば、Chatwork様はグループチャットやファイル共有,タスクマネジメント,ビデオ会議といったサービスを1つにまとめて提供するサービスを展開されています。旧来1つのDBMSですべてのデータを処理していたのですが、あるときは年率200%ほどの勢いでメッセージ数が増加し、遠くない未来に限界を迎える恐れがある状態でした。
チャットのサービス特有の負荷パターンへの対応、新しいサービスの追加開発のしやすさの実現を踏まえ、スケーラビリティと柔軟性を重視した分散処理を取り入れました。ゼロから作る部分だけではなく、技術的な親和性を考慮しながらメッセージングシステムApache KafkaとキーバリューストアHBaseを組み込み、ストリームデータの処理基盤を構成しました。
大きなポイントは、お客様の持つデータ自体の特性、量、増加の状況、処理の傾向などを吟味し、加えて今後のビジネスの動向や展望などを考慮してアーキテクチャーを描くことです。

――ストリームデータ活用とは、どんな仕組みなのでしょうか?
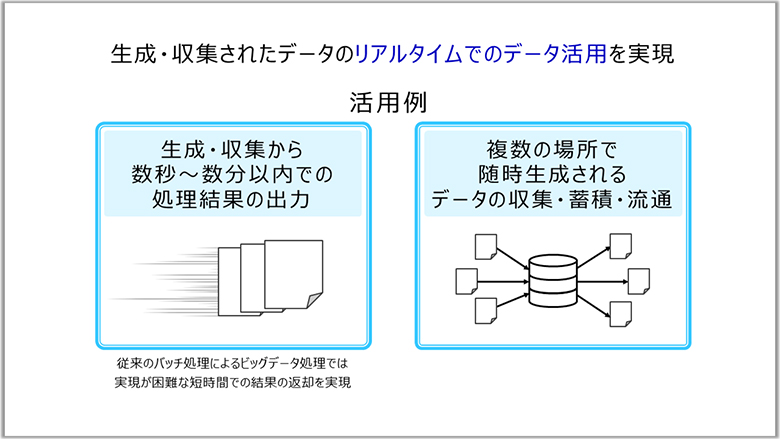
大量のデータをリアルタイムに近い時間で処理する仕組みです。時々刻々と生まれるたくさんのデータをほぼリアルタイムに活用することができます。
例えばチャットの仕組みでは、人が使っていて違和感のない範囲のリアルタイム性が必要であり、ストリームデータ活用の仕組みがそれを可能にしています。多くのサービスから時々刻々と発生するログを取り込んでユーザーにアクションを起こす仕組みなどにも適しています。
また、データ分析においては、例えば1時間から数時間単位で行っていた分析に加え、分から十分単位に間隔を短くして活用する場合に効果的です。
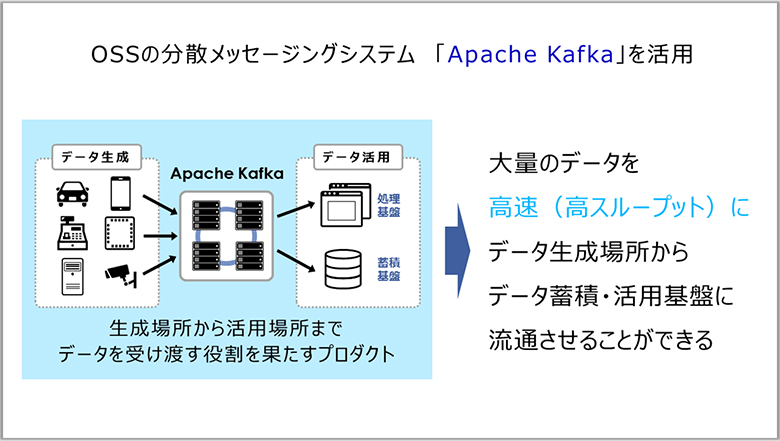
いずれのケースにおいても、情報源から発生するデータ規模が大きくなると、ひとつの計算機で扱うのが難しく、計算機を並べて協調させて処理する必要があります。この仕組みをゼロから作るのは大変ですが、私たちは大規模データを高速(高スループット)で流通させ処理できる、Apache Kafkaという技術を用いて、ストリームデータ活用を実現しています。
――ストリームデータ活用でなければ実現できない理由は何なのでしょうか?
ビジネス上要求される「リアルタイムに近い時間間隔」で大規模なデータを処理するのは簡単ではなく、それに適した仕組みが必要だからです。
先ほどはチャットの仕組みの例を出しましたが、他にも例えば、多数のセンサー、ユーザー、設備やシステム、サービスなどの散らばったデータソースを、相互に一対一でつなごうとすると多数と多数をつなぐメッシュ状態になる課題が挙げられます。
Apache Kafkaでは多対多の接続を中継するハブとなる技術を入れることで、つなぐ相手や量が増えても対応できる仕組みを作ります。
これはシステムやサービスを拡張するときにたいへん有用で、取り扱うデータの規模が大きくなったり、新しい機能を追加したりする場合でも、多くの手間をかけてシステムを作り直す必要がなくなります。新しい機能やサービスの誕生をより後押しすることができるようになるのです。

――ストリームデータ活用がより求められる業界やフィットするサービスはどんなものでしょうか?
ストリームデータ活用は、潜在的にはあらゆるシステムにつながっていくと考えています。
例えば、金融業での不正検知、製造業での生産データ取り込み、サービス業での顧客データ取り込みなどはもちろん、従来は数時間ごとに行っていたデータ処理をもっと早くしたいといった要望は業界業種を問わず多数あり、ユースケースが増えてきています。
「リアルタイムに大量に流れてくるデータを取り込み、短時間で分析したい」
「時々刻々と発生するお客様の行動データをできるだけ旬なうちにビジネスに活用したい」
「大規模な流入があるWebサービスのログを有効活用したい」
と言ったご要望は、どのような業界でも起こりえます。
特にデータ分析の立場からはデータの鮮度が高ければ高いほど、機会創出の可能性が広がりますから、データの取り込みが素早くスムーズになるほど、とても喜ばれます。
また、ストリームデータ分析を素早く適切に行うためには、AIや機械学習を効率的に使うことも重要になってきます。
――AI・機械学習によるデータ分析の一般化については、どのように考えていますか?
基盤観点でいうと、今後は、あらゆるシステムにAI・機械学習の技術が組み込まれる可能性が高まっていくと考えています。一方でエンタープライズにおける実装段階で悩まれる方も多く、相談をいただくことが多くなってきました。特に私は基盤技術の知見をいかし、企業におけるデータ活用の一環として、AI・機械学習を応用するケースに向けた技術支援にも携わっています。
また私はひとつの技術だけで成功するケースはないと思っています。成功している例には、優れたデータ分析者とデータエンジニアが存在し、技術連携も含めてうまく協調できているケースが多いのではないでしょうか。
体制やプロジェクト特性に合わせ、優れた使い手が適切な技術を使いこなせるように工夫することがとても大切なことです。

――お客様への広がりを考えると課題となっていることは何でしょうか?
ストリームデータ活用やそれを支える大規模データ活用基盤は日本国内でも商用適用が進みつつあり、かなり広がりが出てきています。一方、AI・機械学習を含むデータ活用も本番適用を目論むケースが増えていると感じます。しかし、変化の激しい技術領域であるため、現実的にはその前の段階、データ分析のワークフローはどうあるべきかというところで、まだ標準が存在せず、考え方が定まらずに迷う方が多いのではないでしょうか。
NTTデータは要素技術に加え、さまざまなお客様がストリームデータ活用、AI・機械学習を含むデータ活用を自然に取り込めるようなアーキテクチャー、考え方、推進方法を合わせてお届けするための研究・技術開発、オファリング開発を続けています。
この活動は個社の活動に閉じません。例えば、私は日本ソフトウェア科学会の機械学習工学研究会ワーキンググループの幹事になり、日本、海外を問わず、機械学習を本番適用していくときの知見を世の中全体で高め、広めていく活動も実施しています。
――Innovation Conferenceはどういったポイントにフォーカスする予定ですか?来場者へメッセージをお願いします。
私たちは実際にビジネスを考えている方と議論することを重視します。ビジネスの専門家と技術の専門家が互いに向き合い、新しいビジネスプランと新しい技術を付け合わせ、たくさん試行錯誤する機会を持つことが最初の一歩として大切です。
その後の本格的な活用段階で、ご説明した大規模データ活用基盤、ストリームデータ活用、AI・機械学習によるデータ分析などが生きてきます。
また技術はあくまで手段です。そして、手段は置いておけば何かを出してくれるものではなく、どう使うのかは人に委ねられています。
その際、技術自体に関する知識があると、上手な使い方を考えることができます。
どのようにその技術が成り立っているのか。どこで使われるのか。なぜ、その技術が登場してきたのか。こうした技術背景に興味を持っていただけると、日頃取り組まれているビジネスに技術をうまく組み込み、継続的に成長させていく糧になります。本講演では、そういった知見の一端をデータ活用基盤の視点で紐解くお話をしたいと思っています。

ビッグデータ、ストリームデータ活用、AI・機械学習に関する講演情報
NTT DATA Innovation Conference 2020
Accelerating Digital~デジタルで創る未来~
日時:2020年1月24日(金曜日)10:00~18:30(受付開始 9:30)
会場:ANAインターコンチネンタルホテル東京 地下1階
15:55~16:35
ビッグデータ活用基盤のエッセンス
――ストリームデータ活用とAI・機械学習を支える仕組み
NTTデータ
技術革新統括本部 システム技術本部 生産技術部
インテグレーション技術センタ 課長
土橋 昌
お申し込みはこちら:https://www.nttdata-conf.jp/
Apache Kafkaによる大規模データ処理基盤の構築・運用を支援
~センサー情報や位置情報などをリアルタイムに活用するシステムの構築を容易に~







