
まだまだ進んでいないAIの導入
日々多くのAI事例が発表され、新聞で記事を見ない日はないほどだ。目覚ましい事例が数多く発表されている一方で、実際のところはどの業界でも期待されているほど導入が進んでいないのが現実ではないだろうか。実際、JUAS(日本情報システム・ユーザー協会)が実施した最新の調査(※)によると、AIを導入済みの企業は12.6%にとどまる。試験導入中・導入準備中を合わせた全体でも3割弱程度しか導入が進んでいないのが現状だ。
AI導入に積極的ではない理由は、維持コストの高さや維持の手間、データの準備が困難、導入後の学習や精度向上が困難、AI人材の不足など多岐にわたる。この傾向は特定の業界・業務に限ったことではない。
また、実際にAIを導入しようとしたときにも課題は多く、最終的に実用に至るプロジェクトは少ない。ボトルネックとして、(1)「使いどころが見つからない」(2)「効果の見積もりが曖昧」(3)「データ・情報を十分に用意できない」(4)「精度が期待レベルに達しない」といった4つの点が挙げられる。
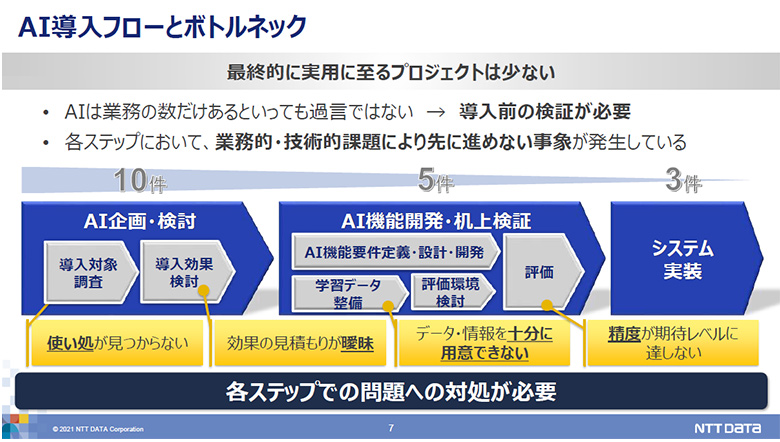
図1:AI導入フローとボトルネック
業務視点での解決が求められる問題
(1)「使いどころが見つからない」、(2)「効果の見積もりが曖昧」といった問題は業務視点での解決が必要だ。
AI技術の全体像を見渡すと、大きく「認識・推定系」「予測・制御系」「生成・対話系」「設計・デザイン系」「分析・要約系」に分類できる(図1)。AI技術には多様なものがあること、事例やアプリケーションレベルではなく、もう一つ下の技術で捉えていただくことが、業務での使い処を見いだす上で肝要である。実際に業務に携わっている立場でこのAI技術の分類を見てみることは、AI活用により実現したいことの導出に有用だ。
AIは業務の効率化やサービスの高度化をもたらす技術としてみなされているが、過剰な期待と幻滅につながることも往々にして生じている。どれくらいの精度であればいいのか、どれくらいの効率化につながればいいのか、現状の業務・サービスに照らし合わせて冷静に見極めることが重要である。
たとえば「認識・推定系」の領域では、紙資料や音声の書き起こしといったデータエントリーなどのように、人の代わりに作業・補助することが期待される。なかなか精度100%というわけにはいかないのが現実であるが、人の作業にでも生じる誤り率との比較、AIでの精度が十分でない処理対象を人による作業に回した場合でも得られる全体的な作業時間減など、業務上の課題に基づいて、効果測定のための評価軸や、AI適用が有用となる目標値を適切に設定することが求められる。AIにはさまざまな効能があるが、業務や業務で行っている施策と照らし合わせて、実際に設定すべき指標や目標値を適切に定めていく必要がある。
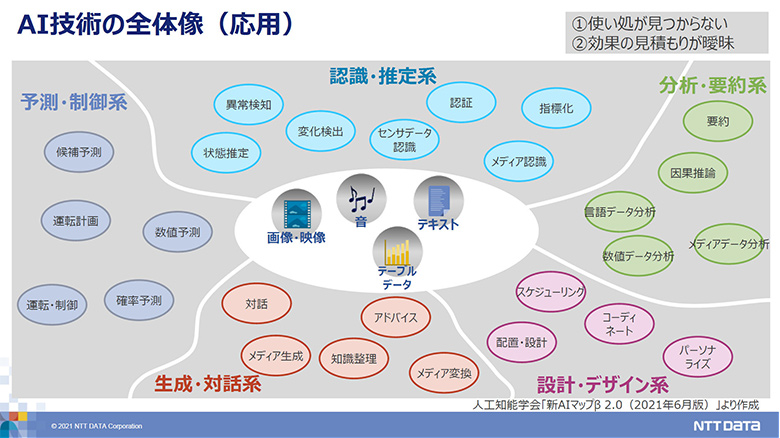
図2:AI技術の全体像
技術視点での解決が求められる問題
次に、(3)「データ・情報を十分に用意できない」問題だ。これは技術視点での解決が求められる。先にも述べたとおり、AI導入で学習に必要となるデータ・情報を十分に用意できないという悩みをよく聞かれる。そうした課題の解決には、「学習に必要なデータ(画像)を自動生成する(CG、GAN)」「データを秘匿しながら集約する(秘密分散学習)」「データを作成しながら学習する(強化学習)」「データから形式知化する(オントロジー半自動生成)」といった技術的アプローチが有効であり、積極的な活用が望まれる。
ここでは、データを作成しながら学習する、強化学習の事例を紹介する。NTTファシリティーズ様と共同開発したアクティブダンパーの制御技術に関するAIだ。地震における建物の制御に広く使われるダンパーをより適切かつ効率的に制御することで、建物の揺れを制御する。
本事例では「AlphaGo」でも使われた深層強化学習の技術を採用することで、従来よりも大幅に建物の揺れを低減することに成功している。
この事例では、机上での振動応答シミュレーションと深層強化学習を組み合わせた仕組みが用いられている。深層強化学習は、振動応答シミュレーションの機械に試行錯誤をさせながら、より良い効果を示した際に報酬を与えることを繰り返し学習するモデルが採用されている。リアルな世界をバーチャルで再現することで十分な学習が可能となる。
最後に、(4)「精度が期待レベルに達しない」ケースを紐解いていきたい。対応の定石としては、学習データの見直し・追加、モデルの再検討、カテゴリーごとのモデル構築のほか、革新的技術の活用、人による多角的な視点による判定をAIで実現するマルチモーダルAIといったアプローチが考えられる。
革新的技術の活用として、自然言語処理を例にすると2018年10月にGoogleが発表した自然言語処理向けの事前学習手法であり汎用言語モデルの「BERT」が挙げられる。BERTは、事前学習として、教師なしで学習、双方向で単語の関係性を考慮することができ、少量の学習データの追加や、転移学習により、情報抽出や検索などさまざまな応用が可能になっている。
NTTデータではBERTをさらに発展させ、金融ドメインに特化したBERTである「金融版BERT」を開発している。同BERTは、日本語モデルとして最大サイズのコーパスで学習したNTT版BERT(NTTメディアインテリジェンス研究所開発)に法令等金融文書関連コーパスを追加学習し、金融用語や文脈理解に優れたモデルとしている。これにより、コールセンタ応対分析、緊急関連文書の要約、マニュアル等からの情報抽出への活用が期待されている。
精度としても、単語予測や、一種証券外務員資格試験(正誤・穴埋め)で検証したところ、金融版に特化していないBERTに比べて良好な結果が得られている。
マルチモーダルAIの適用例に、類似商標検索が挙げられる。商標などの画像の検索においては、縦横比が変わっていたり、図形などの他要素と結合していたりするものでも、従来の画像解析技術で対応できてきた。しかし、例えば同じく鳥を表す画像であっても、写実的なものとデフォルメされたものなど抽象度が異なる(デフォルメされた)場合は類似商標として検索できないという問題があった。これに対し、人が類似と判定する際には画像と商標に付与された図形分類情報等のテキスト情報を踏まえているというやり方に即して、画像とテキスト情報を組み合わせた形(マルチモーダル)で学習するアプローチをとることで精度向上につながった。これ以外にも、人による推定や判断に倣ったマルチモーダルAIとしては、画像と音声、動画とテキストなど、さまざまな組み合わせが有効になるケースが多々あると考えられる。
本稿ではAI導入に向けた各ステップにおいて生じている問題に対して、業務視点、技術視点それぞれでの解決方法を示した。参考になれば幸いである。
本記事は、2021年1月28日、29日に開催されたNTT DATA Innovation Conference 2021での講演をもとに構成しています。







