1.データ活用基盤を取り巻く要件や環境の変化
IoT機器の増加やストレージ技術の発達に伴い、企業が抱えるデータは年々巨大化しています。これらの大量データを取り扱うためには、並列分散処理技術が有効であり、Digital Transformation(以下DX)を支える技術として注目されています。
Hadoop/Sparkは大規模データ処理を実現するオープンソースの基盤ソフトウエアであり、企業のデータ活用を支える並列分散処理技術です。Hadoop/Sparkを用いると、RDBMSでは対応できなかった数十・数百テラバイトからペタバイトクラスの大量データの蓄積および処理が可能となります。Hadoop/Sparkは将来的なデータの規模に応じて柔軟に拡張しやすいという特長を持ちます。
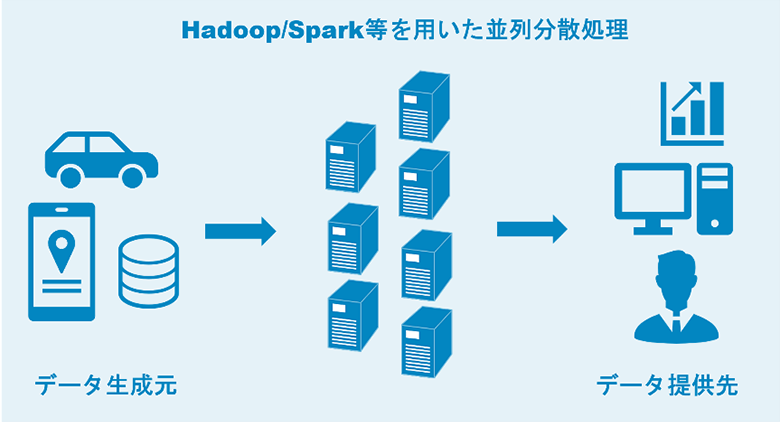
図1:Hadoop/Spark等を用いた並列分散処理
多くの企業は、将来の事業規模を見通すことが難しく、データ活用基盤の構築や運用に課題を抱えています。そのため、小規模から始めて事業の拡大に合わせ、徐々に大規模にしていける拡張性や、特定のベンダーや製品に依存することなく長期的にシステムを改善し続けられることが必要とされています。
たとえば、データ活用基盤の初期導入時には、データの規模や業務量、ユースケース等の予測・要件定義が難しいという課題があります。Hadoop/Sparkを用いたデータ活用基盤を導入することで、PoCからスモールスタートして実際の運用を行いながら徐々に要件を明確化しつつ、データ規模や業務量に応じて柔軟にシステムを拡張でき、データ活用基盤の導入コストの最適化や手戻りの防止につながります。
また、長期に渡るシステム運用において、データ活用基盤の環境に制約があると、将来的に新たな業務要件が発生した場合に既存環境では対応できないことがあります。また、特定ベンダーにロックインすると、データ活用基盤のコスト(ライセンス費用、サポート費用等)のコントロールが難しくなるケースがあります。このような場合に、Hadoop/Sparkといったオープンソース技術をデータ活用基盤として採用することで、特定のベンダーや製品に依存せず長期的に安定した基盤を得ることができます。
しかし、オープンソースソフトウエアを導入する際には、複数のソフトウエア間のバージョンの整合性や適切な組み合わせの調査・確認が必要です。オープンソースのHadoopディストリビューションであるApache Bigtopは、Hadoop、Sparkなどデータ基盤を構成する関連ソフトウエアをパッケージとして公開しており、これらのソフトウエアのバージョンの整合性や組み合わせについて、Apache Bigtopの開発コミュニティにて事前に確認しています。
図2:Apache Bigtopの活用
2.Apache Bigtopとは
Apache Bigtop(以下Bigtop)は、非営利団体であるApache Software Foundationによって開発されている、オープンソースのHadoop/Sparkディストリビューション(※)です。Bigtopを利用することで、以下のようなメリットが得られます。
(1)様々な環境上で長期的に安定した運用が可能
オンプレミス環境のみ、あるいはオンプレミスとクラウドのハイブリッド環境や、さまざまなクラウド環境での運用を希望する場合に、特定のベンダーや製品に依存せずに利用することができます。同じベンダーや製品を利用し続けるといった制約がないため、将来に向けた移行や継続性の観点においてコストやリスクをコントロールしやすく、長期的に安定した運用ができます。
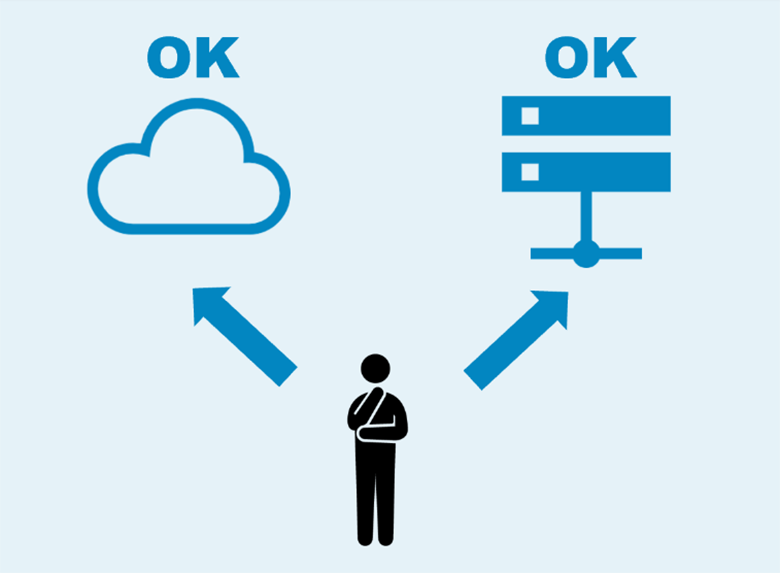
図3:Apache Bigtopでオンプレミス・クラウドのハイブリッド環境でも利用可能
(2)小規模導入から始められる
導入や利用には、ソフトウエアライセンス費用は必要ありません。小規模導入から始め、実運用では大規模に導入していくことが可能です。
図4:Apache Bigtopで小規模から始め、実運用では大規模に導入できる
(3)トラブルの原因をより詳細に把握し、適切な対応が可能
オープンソースのため、ソースコードが開示されています。そのため、誰でもソフトウエアの内部構造を見ることができ、高度な技術力があればトラブルの原因を究明・解決することが可能です。
図5:ソースコードが開示されているため、誰でもソフトウエアの内部構造を見ることができる
Bigtopは上記のようなメリットを有する一方で、オープンソースソフトウエアであるため、開発元による公式な商用サポートが提供されていません。そのため実際にデータ活用基盤として導入するにあたって必要となる実運用上の活用ノウハウや設計・開発・運用のベストプラクティスを自ら獲得しなければならない、という課題があります。
NTTデータが提供するBigtopソリューションサービスは、Bigtopを用いて構築されたデータ活用基盤に対してコンサルディングから運用時のサポートまでカバーすることで、長期の安定運用を可能とし、上記の課題に対応します。
複数の相互運用可能なソフトウエアを、配布・導入が容易になるようパッケージ化したもの。
3.Bigtopソリューションサービスの特長
NTTデータでは、2008年から並列分散処理技術のApache Hadoopへの取り組みを開始し、Apache Spark、Apache Kafka等、構築・運用ソリューションの範囲を拡張してきました。そして、2022年3月より、Hadoop/Spark構築・運用ソリューションにBigtopを採用し、長期安定運用を可能とするBigtopソリューションサービスの提供を開始します。NTTデータが提供するBigtopソリューションは、コンサルティングから運用までをトータルに支援し、お客さまのデータ活用に関する技術課題を解決します。これにより、お客さまは高品質で長期の安定運用を可能とするデータ活用基盤を、迅速に導入することが可能となります。
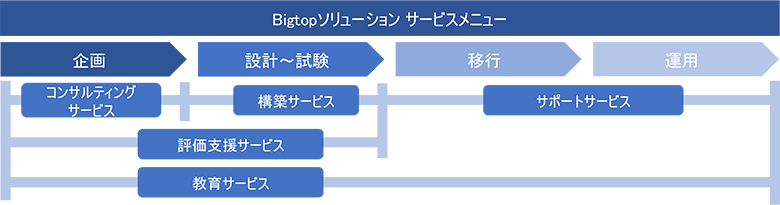
図6:Bigtopソリューションサービス概要
4.Bigtopソリューションで実現できること
Bigtopソリューションでは、必要な設計のポイントや手順等をまとめており、NTTDがこれまで支援してきたHadoop/Spark導入案件のノウハウを詰め込んでいます。
Bigtopソリューションでは、迅速なデータ活用基盤導入を可能にする構築自動化ツールを提供しています。大量のサーバを利用するHadoop基盤では構築にもコストがかかりますが、自動化ツールを利用することでHadoop基盤を容易に構築することが可能です。当社がこれまで構築してきたノウハウが詰め込まれており、ドキュメントと合わせて安定した運用に耐えうる基盤を構築することができます。
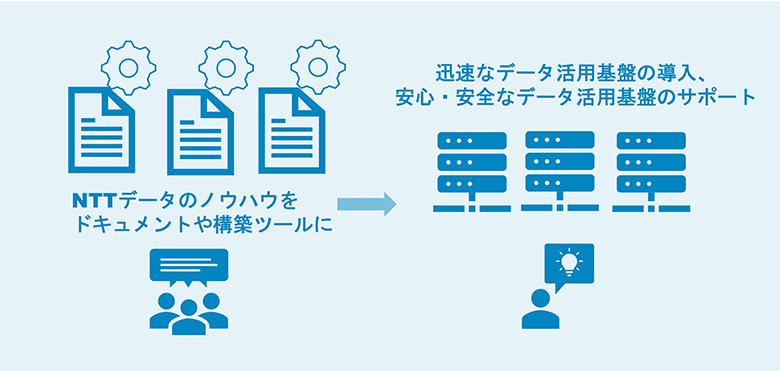
図7:Bigtopソリューションによる迅速なデータ活用基盤の設計・構築
5.まとめ
DXを推進していくには、データ活用基盤を導入するだけではなく、安定した運用を実現し、長期的にシステムを改善し続けられることが重要です。データ活用基盤のソフトウエアとしてオープンソースであるBigtopを選択することで、長期的な安定運用のメリットが得られます。データ活用の重要性が高まっているなか、NTTデータが提供するBigtopソリューションは、早期のデータ活用基盤の導入と安心・安全な長期的な基盤運用の実現により、企業のデータ活用の推進をサポートしていきます。







