
データレイクの課題 分断、統合、また分断
この20年以上、データに関わる業界では、「データがサイロ化している、統合しなければならない」と言われ続けてきました。システムや業務ごとのサイロ化を解消し、データを統合すれば新たなインサイトが生まれ、価値を創出できるという言説です。実際、データのサイロ化の課題感は非常に浸透しており、それを解消するための技術や体制を取り入れる企業は多くなっています。
テクノロジーの観点では、ビッグデータを蓄積できるデータレイクの出現が大きなブレイクスルーになりました。また、データレイクをデータスワンプ(沼)にしないために、蓄積されたデータの意味をきちんと理解し、それを利用する人に適切に案内する「データスチュワード」と呼ばれる役割も登場し、先進的な企業においてはデータマネジメントを行う実行部隊として体制が作られています。
これらの技術や体制により、データレイクに多様なデータソースからのデータをため込み、それを多様なユーザが利用する、N:1:Nのデータ基盤が作られてきました。このアーキテクチャは、業務部門ごとにバラバラにデータが生成・利用される、いわゆるサイロ化による分断を解消し、企業内のデータを統合するという意味で大きなメリットがあります。
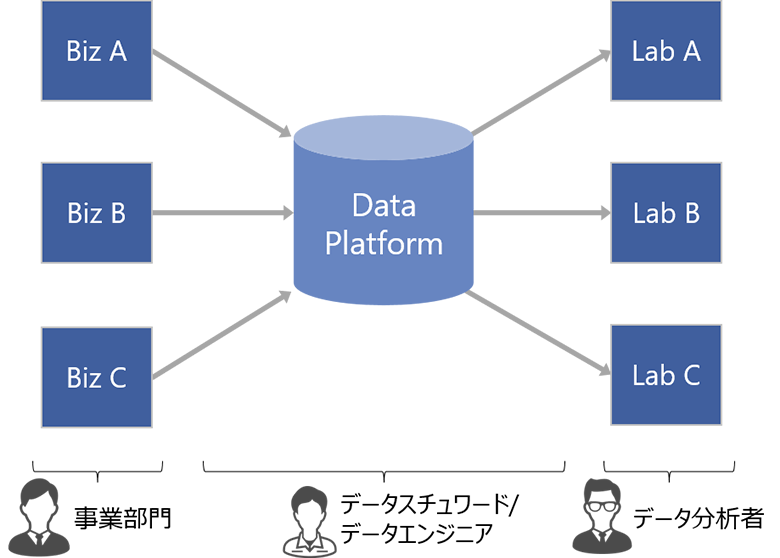
図1:一般的なデータレイクアーキテクチャ
しかし現実には、この中央集権的とも言えるアーキテクチャは本来目指したかった本質的な統合になかなか繋がらず、むしろ別の分断をも引き起こしてしまっています。それは、データ基盤の管理者とユーザの分断、そして業務データと分析データの分断です。
データ基盤の管理者は、社内で唯一データレイクに直接アクセスすることができます。社内のすべてのデータに精通してユーザに適切にデータを届けることができなければなりませんし、その巨大なデータ基盤を取りまわすために、Hadoop/Spark等の分散処理技術を使いこなす必要があります。つまりデータスチュワードとしての役割とデータエンジニアとしての役割をそれぞれ高度に発揮することが求められます。それほど万能な人、組織、体制を整えることは当然ですが非常に難しく、データ基盤はなかなか本来の価値を発揮できません。
「データ管理知識体系ガイド(DMBOK)第一版」によれば、本来「データスチュワード」という役割は、ビジネス部門の実質的なリーダーが就任すべきものでした。そうでなければ、データの価値を発見し、データに説明責任を持つことなどできないからです。しかし現実には、統合され中央集権化されたデータ基盤においては、ビジネスリーダーが不在のままデータ整備が行われてしまうことがよくあります。すると、管理者が必死に整備したにも関わらず、今一つ使われないデータレイクが出来上がります。ユーザは結局、自分達の理解できる範囲のデータしか扱えません。
これが、業務データと分析データの分断も引き起こしてしまいます。業務システムから遠く離れた中央集権型データ基盤に、様々な加工を経て集められたデータからインサイトを得たとして、ユーザがそれを業務に活かすためにはどうすれば良いでしょうか。個別業務にインサイトを取り込むにはデータ管理の専門家の検討が必要不可欠ですが、それは中央集権化されたデータレイクやデータ管理者の役割ではなく、ユーザは途方に暮れることになります。
データレイクによる新たな分断により、分析が促進しない、分析をしてもそれを業務に活かすことができない、という事態が発生してしまっているのが、これまでのデータ基盤の実情と言えます。この課題を乗り越えなければ、単なる分析を超え、本質的に自社の業務を変革させるデータ活用を行うことはできません。
そこで、今世界中で注目を浴びているデータマネジメントの手法であり、アーキテクチャの指針でもあるのが「データメッシュ」という考え方です。
新たなデータマネジメントのかたち データメッシュ
データメッシュはZhamak Dehghani氏が2019年に提唱した考え方で、これまでのデータ基盤に課題を感じていた多くの先進的な企業から非常に注目を集めています。
データメッシュの大きな特徴は、「非中央集権型」であるということです。ドメイン(この場合は「事業領域」のような意味合い)ごとにデータ管理の責務を持ち、データ基盤はその流通のためのハブのような役割を担います。各ドメイン同士が網の目のように相互にデータをやり取りすることから、データメッシュと呼ばれます。
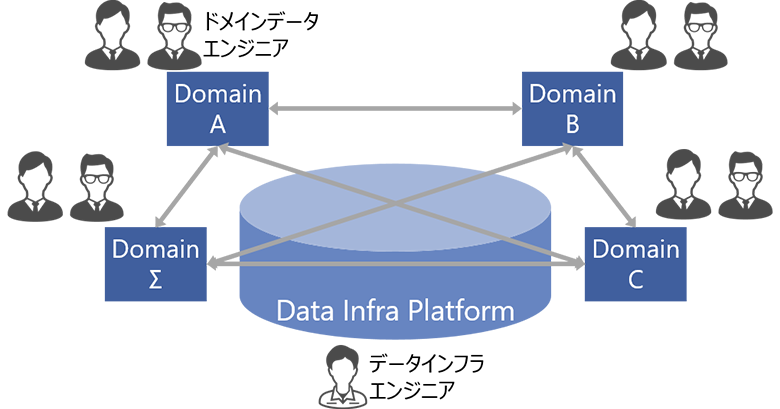
図2:データメッシュアーキテクチャ
データ統合の難しさを実際に感じた人にとって、この考え方は理解できると思いますが、もとのサイロ化されたデータとは何が違うのでしょうか。Zhamak Dehghani氏が提唱したデータメッシュに関する4つの原則を紹介します。
表:データメッシュ4原則
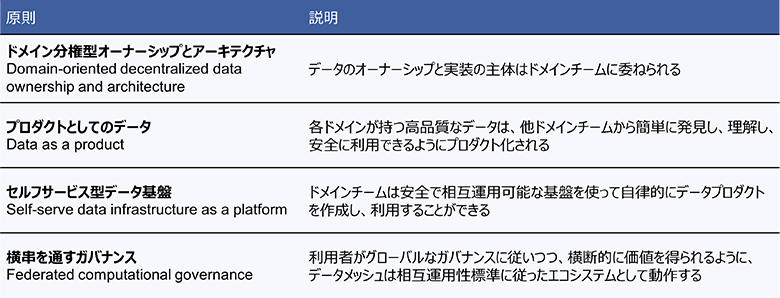
1つ目と2つ目の原則で説明されているように、データメッシュでは、ドメインから生み出されるデータはドメインに管理責任があります。そして品質が担保され、説明が付与され、再利用可能となったデータを「データプロダクト」と呼びます。データプロダクトは他のドメインでも容易に利用することができるのが特徴です。
また、3つ目と4つ目の原則にあるように、ドメイン側にデータの主導権が移ったとしても、それを流通させるための相互運用性を担保したデータ基盤の提供や、横串を通すガバナンスは必要不可欠です。引き続き中央のデータ基盤の管理者は、ドメイン側のデータ管理者を支援し、サイロ化を防ぐための様々な努力が必要です。しかしそれは、全社のデータを一元的に管理するデータスチュワードの役割を負うことではなくなります。
データメッシュによって生まれる価値と課題
データメッシュアーキテクチャが実装されれば、ドメインと中央、業務と分析の分断がなくなり、分析結果をもとに業務を行うことをドメイン側(事業部門側)主体で行うための準備が整います。ドメインが主体となって整備したデータプロダクトを流通させることで、闇鍋のようなデータレイクにやみくもにデータを蓄積するのではなく、説明責任が果たされたデータを、スケーラビリティをもってマネジメントできるようになります。
また、データメッシュは変化の激しい時代に合った、アジャイルなデータ基盤のアプローチとも言えます。データメッシュは最初から完全体で始める必要はなく、その魅力を高めつつ徐々に参加者を増やしていくことができます。また、データプロダクトがある程度流通している状態からは、新しい業務領域を即座に立ち上げる、そしてその業務領域から新たなデータプロダクトが生まれる、ということが可能な営みでもあります。
こうした利点の一方で、実現には数多くの課題も存在することもまた事実です。
何より大きな課題は、ドメイン側が推進力をもってデータ活用を推進するという枠組みそのものです。これまでの日本におけるデータ活用は、デジタル専任の部署を設けるなど、一部の部門が事業部門の協力を得ながら積極的に進めるものであって、既存の事業部門がデータ活用の取り組みを主体的に進めることはなかなかできていなかったと言えます。しかしこの方法では、PoCまではできたとしても、実際の業務に取り入れる段階では大きな壁ができてしまうことがすでに知られてきています。
また、ドメイン側がデータ活用に乗り出したとして、自らが生み出したデータをデータプロダクトとして他ドメインに流通させるための動機付けも難しい課題です。協力体制を生み出しやすいルール作りや、各組織のKPIの設定等のインセンティブを経営レベルで設計していく必要があります。
組織の課題に比べれば大きくありませんが、技術的な課題も存在します。
SnowflakeやDatabricksは、そのスケーラビリティやデータ共有の機能を活かして、自らをセルフサービス型のデータ基盤として利用したデータメッシュを実現するアイデアを発表しています。実現可能性が高く、魅力的な案ではありますが、全てのドメインで単一の製品をデータストアとして使うことが現実的でないことも現時点では事実です。複数の製品にまたがるメッシュを実現させる場合は、データ仮想化の技術やPub/Sub方式のストリーミングサービスを利用することも必要になってきます。
また、データプロダクトを流通させるためには、各ドメインが自らの説明責任を果たすためのデータカタログの整備が必須ですが、従来のデータカタログ製品をこのデータプロダクトの考え方に適合させて利用することは簡単ではありません。
「現場」主導のデータ活用への挑戦
データメッシュ実現への課題はどれも大きく、容易に解決できるものではありません。しかし、非中央集権型のデータマネジメントは、データ分析を超えた次のステップ、データを中心とした業務の変革に乗り出すために挑戦しなければならないものではないかと筆者は考えています。
各事業部門がデータ活用の技術力を持ち、自らデータ活用を行っていくための組織作りや意識の変革は非常に難しいです。しかし、それができなければ、いつまでも分析止まり、PoC止まりのデータ活用に終わってしまうこともまた事実であります。これからは、データ活用支援組織などの形で、主体を事業部門に置きつつ、どのようにそれを補助・教育していくかという体制を作っていくことが必要になってきます。
そうして一つずつ課題を解決し、事業部門が主体となった非中央集権型のデータマネジメント体制とデータ基盤を作っていくことができれば、ビジネスの「現場」がデータ活用の主導権を握る、一段上のデータの民主化が達成され、これからの時代のデータ活用において大きな成功を掴むことができるのではないでしょうか。







