
- 目次
AIが地球環境に与える影響
近年、AIの開発・活用の際に必要となる電力量の増加に起因する、CO2排出量が増加しています。自然言語処理で革新をもたらしたBERTの登場以降、AIモデルの大規模化により、自然言語処理、画像処理、音声処理といった分野で劇的な精度向上が実現し、AIは様々なビジネス変革に応用されています。しかし、大規模AIモデルでは、アルゴリズムの訓練や実際の活用のフェーズで多大な電力が必要となるのです。
たとえば、Applied Materials社のCEO Gary Dickerson氏は、現在のAIの採用率が進み、ハードウェアやソフトウェアに技術革新がない場合、データセンターにおける全世界の消費電力の割合は、2019年の2%から2025年には10%まで増加する、と推測しています(※1)。AIに起因する消費電力は今後ますます増加するとみられており、消費電力削減に向けた取り組みが必須です。
本稿では、AIの消費電力削減に向けた世の中の動向と、ソフトウェアによる消費電力削減のアプローチについて詳細を説明します。
https://observer.com/2019/08/artificial-intelligence-bitcoin-cloud-computing-climate-change/
AIによる消費電力の内訳
ディープラーニングを用いてAIモデルを開発し、活用するまでには、大きく「学習」と「推論」の2つのフェーズがあります。
- (1)「学習」フェーズとは、AIモデルの開発者が大量の学習データをモデルに読み込ませることで、目的となるAIタスク(機械翻訳や画像分類等)を実行できるようにモデルに教えるプロセスです。
この「学習」フェーズは、汎用的なモデルを開発する(ア)「事前学習」と、個別のタスクに最適化する(イ)「ファインチューニング」があります。たとえば、大規模言語モデル開発を含む自然言語処理の「学習」フェーズの例を説明します。
- (ア)「事前学習」では、大規模なデータセットを用いて汎用的な学習済みモデルを開発します。膨大なパラメーターの学習が必要となり、たとえばGoogleが提案したBERTは3.4億、OpenAIが提案したGPT-3は1750億ものパラメーターを備えたモデルとなっています。開発に必要な消費電力も膨大で、GPT-3の学習に要する電力は1,287MWh、CO2排出量552トンに相当すると言われています(※2)。ただし、「事前学習モデル」の開発は一部の企業や研究機関に限られ、一般のAI開発者はこの事前学習されたモデルを活用可能です。
- (イ)「ファインチューニング」では比較的少ないデータを用いて、開発された事前学習モデルを個別のタスクに最適化します。質問応答、文書要約、文書分類等の具体的なタスクを設定した上で、解きたいタスクのデータを数件~数万件程度用意して学習することで、モデルの精度を向上させます。「事前学習」と比べて消費電力は少なくなりますが、個別のAI開発プロジェクトごとに行う必要があり、実行される回数は多くなります。
- (2)「推論」フェーズとは、利用者がトレーニング済のモデルに新しいデータを入力して予測結果の出力を得るプロセスです。
一般に、「学習」フェーズと「推論」フェーズの1回あたりの消費電力は、「学習」フェーズの方が大きいです。モデルの精度を向上するためにデータ量やパラメーター数を増やすほど、「学習」フェーズの消費電力は大きくなっていきます。一方で、「学習」フェーズはモデルの開発者が1回または複数回行えば開発が完了するのに対し、「推論」フェーズはモデルでの予測のたびに実行されるので、用途によっては数万回から数億回以上も実行されることになります。
では、「学習」フェーズと「推論」フェーズではどちらの消費電力が大きいのでしょうか。
- Amazon Web Servicesを利用する顧客からは、機械学習サービスにかかるコストのうち90%は「推論」が占めるとの声があがっています。(※3)
- NVIDIA社のCEO Jensen Huang氏は、2019年に機械学習コストの80-90%は「推論」フェーズによるものであると推定しています。(※4)
- 自社で大規模なモデル開発を行うGoogleでも、2022年の報告で、自社で機械学習のために消費する電力のうち60%が「推論」、40%が「学習」に起因すると述べています。(※5)
- Facebookは、自社のサーバー経由のニューラルネットワークを使い、全世界のスマートフォン上で1日あたり200兆回の推論を実行していると報告しています。(※6)
以上のように、「推論」では1回あたりの消費電力は「学習」より小さいものの、実行回数が「学習」と比べて桁違いに大きくなるため、トータルの消費電力では、「推論」が「学習」よりも大きくなることがわかります。
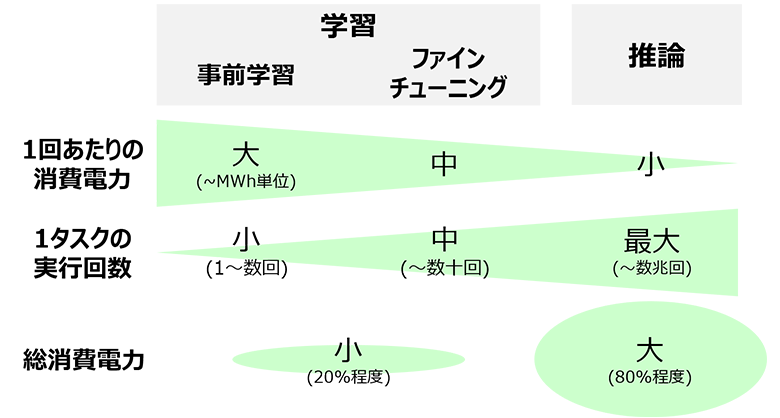
図1:AIフェーズごとの実行回数と消費電力の関係
David Patterson et al., Carbon Emissions and Large Neural Network Training
https://www.hpcwire.com/2019/03/19/aws-upgrades-its-gpu-backed-ai-inference-platform/
https://ai.googleblog.com/2022/02/good-news-about-carbon-footprint-of.html
AIの消費電力を削減する3つのアプローチ
AIの消費電力を削減するアプローチは以下の3つに大別されます。
(1)クラウド/データセンターによる削減
「学習」や「推論」における計算リソースが実際に消費される設備の消費電力の削減のことです。
たとえば、NTTデータで実証実験中のデータセンターの「液浸冷却システム」では、冷却に必要な消費電力を、従来型のデータセンターと比べて最大97%削減できることを確認しています(※7)。また、データセンターの室内環境の可視化システムによりサーバールームの過冷却を抑制することで、冷却エネルギーを約35%削減することにも成功しています(※8)。
(2)ハードウェアによる削減
「学習」や「推論」を実行するクラウドやデータセンターにおける個々のサーバーや、「推論」を実行する多数のエッジデバイスおよびそれらの内部のGPUやCPUといった、個別の機器・部品の電力利用最適化による削減のことです。AIモデルの特性や推論が実行されるデバイスの制約を踏まえ、最適なハードウェアを選択することで、省エネを実現できる可能性があります。また、各ハードウェアのメーカーも、ディープラーニングの「学習」「推論」に特化したデバイスの開発に取り組んでおり、同一の計算を実行するための消費電力は年々削減されています。
(3)ソフトウェアによる削減
AI開発者自身でのアルゴリズムの工夫等による消費電力の削減のことです。たとえば、AIモデル軽量化、エネルギー効率の良いAIプラットフォームの選択、データ分析に適したファイル形式の選択が挙げられます。次章で、AIモデル軽量化について詳細に説明します。
AIモデル軽量化による消費電力の削減
ソフトウェアによる「推論」時の消費電力を削減するためのモデル軽量化の代表的な実現方法には、次の3つがあります。
- (1)Pruning(枝刈り)
- (2)Distillation(蒸留)
- (3)Quantization(量子化)
どのモデル軽量化の方法も、電力削減とモデルの予測精度はトレードオフの関係にあります。モデルを軽量化すると「推論」時の計算量が少なくなり消費電力は減りますが、モデルが覚えている単語の数や文法ルールの理解度を落とすことに相当するので、精度が悪くなってしまうのです。NTTデータでは、できるだけ精度を落とさずに電力削減効果を最大化するため、これらの手法を組み合わせてアルゴリズムやパラメーターを最適化する手法を開発しています。
- (1)Pruning(枝刈り)は、モデルから重要度の低い重みを削除することです。
モデル軽量化のアプローチとして、重み行列の行と列を削除する「Matrix Pruning」と、レイヤそのものをモデルから除去する「Layer Removal」の2通りがあります。
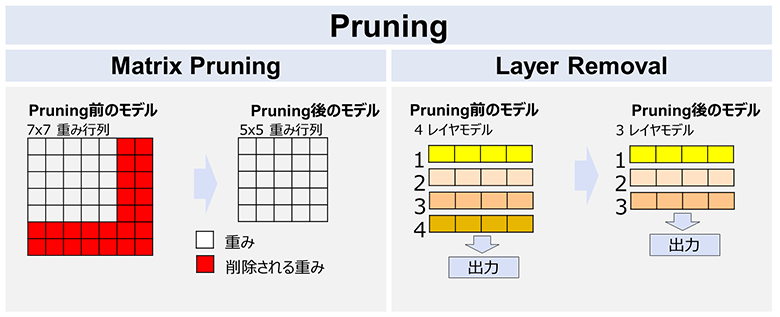
図2:Pruning(枝刈り)手法のイメージ
- (2)Distillation(蒸留)は、モデル圧縮の最も一般的な手法の1つです。すでに訓練された大きい「教師」モデルの出力結果を小さい「生徒」モデルに学習させて、できるだけ「教師」モデルと同じ出力を出せるように訓練することを指します。たとえば、小規模な言語モデルとして広く使用されているDistillBERTや、エッジデバイス・モバイル機器で使用できるほど小さいTinyBERT・MobileBERTが挙げられます。
- (3)Quantization(量子化)は、前の2つの手法と異なり、モデルの構造を変更するのではなく、重みのビット数を減らすことで計算を近似する手法です。モデルの精度はほとんど変わりませんが、モデルに必要なメモリは大幅に削減されます。しかし、これらの計算はほとんどのGPUでサポートされていないため、主にエッジデバイスやモバイル機器上での推論への適用が期待されます。
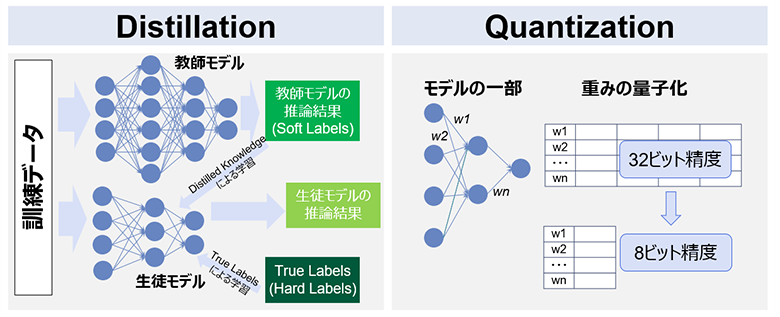
図3:Distillation(蒸留)とQuantization(量子化)のイメージ
それぞれの手法には利点・欠点がありますが、適切に組み合わせることで、様々な要件に対応可能な、持続可能でグリーンなAIモデルを実現できる可能性があります。
一方で、近年のAIに関する技術進化のスピードは早く、BERT以降、事前学習された大規模AIモデルが続々と登場しているため、その消費電力削減を実現する技術も特定のモデルに特化するのではなく、様々なAIモデルにタイムリーに対応できる汎用性が求められます。NTTデータでは現在、精度・消費電力(CO2排出量)・GPUでの利用可否といった観点から最適な手法の組み合わせを検証することで、特定のAIモデルに限定せずに、任意のAIモデルに対して推論時の消費電力削減を可能とする汎用的な軽量化手法の確立を目指しています。
次の章で、NTTデータが検証中の手法について、詳細を見ていきます。
NTTデータのモデル軽量化と今後の展望
一般に、Distillation(蒸留)の一例であるTinyBERTなどの軽量化済みの事前学習モデルは、精度と消費電力のバランスは良いですが、大規模なデータが必要であり構築までに時間がかかることや、BERT以外の異なる種類の言語モデルに対応できないことが課題です。
前章で紹介したモデル軽量化の3つの手法は一般的なものですが、これらの組み合わせによる最適化は各AI開発者のノウハウに委ねられています。NTTデータでは、これまでに自然言語処理の分野で培ってきた知見を活用し、最適な軽量化手法の組み合わせを実現することを目指しています。
このNTTデータが検証している手法ではBERTだけでなく、T5やGPT-3ベースのOPTといったあらゆるモデルに対し、1回限りの調整で軽量化モデルを構築できることが利点になります。
NTTデータが検証中の手法で、実際に推論をした精度と、その推論に要するCO2の結果を示します。この検証では、推論に要する消費電力からCO2の相対排出量を換算して評価を行っています。それぞれの手法の効果を検証するため、軽量化前のモデルでの精度・CO2排出量を1とした場合の相対精度(%accuracy)と、相対排出量(%emission)を比較しました。学習は自然言語処理で2値分類の検証に広く用いられるIMDbデータセット用いて行い、推論はすべてNVIDIA A40 GPU上で行いました。
上記で紹介した手法のうち、まず一般的なDistillation(蒸留)の検証結果と、NTTデータが検証中の手法の検証結果との比較を示します。
「BERT」は通常のBERTをファインチューニングした結果を表します。軽量化はしていません。
「TinyBERT」は、前述した一般的なDistillation(蒸留)の軽量化モデルの1つです。
「Layer Removal」、「Matrix Pruning」、「Combination(Layer RemovalとMatrix Pruningの複合)」の3つは、NTTデータが検証中の手法を表しています。なお、これら3つはすべてそれぞれのPruning(枝刈り)でモデルサイズを軽量化した上で、Distillation(蒸留)による訓練を行っています。
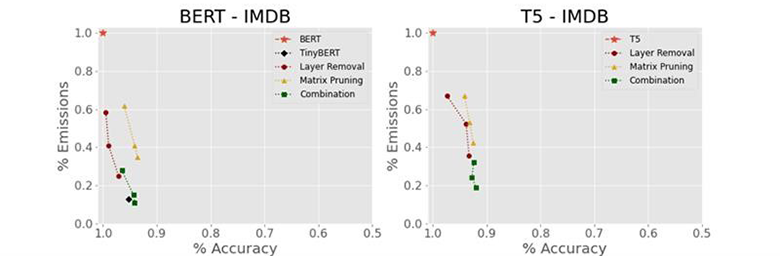
図4:IMDbデータセットにおけるBERTとT5の相対精度と相対CO2排出量
図4はBERTとT5での検証結果です。
左側のBERTでの検証では、「Layer removal」は相対精度を約97%に維持しながら相対排出量を約25%まで削減できています。「Combination」では、相対精度を約94%に維持しながら相対排出量を約11%まで削減できています。このように、1回限りの調整でありながら、構築に大規模な時間とデータを要するTinyBERTとほぼ同等の精度と排出量を実現できることが確認できます。
これらの手法はT5へも適用可能です。右側のT5での検証結果からは、BERTと同様の傾向が見られ、「Layer Removal」では相対精度約93%で相対排出量を約35%まで削減、「Combination」では相対精度約92%で相対排出量を約19%まで削減することができました。
また、IMDbと同様に自然言語処理で広く用いられる、GLUEデータセットにおいても、本手法の一定の効果を確認しています。GLUEはIMDbと比べてやや難易度の高い、回帰や分類などの9タスクからなり、本検証では一定以上の学習データ量が含まれる5タスクを対象に実施しています。BERTでの検証を行った結果、5タスクの平均で、相対精度約93%を維持しながら相対排出量を約14%まで削減できています(TinyBERTでは相対精度約96%、相対排出量約13%)。
上記の検証はGPUを用いた推論に対して行いました。推論にCPUを用いる場合はQuantization(量子化)を適用することができ、精度を維持したまま、排出量をさらに半分程度まで削減可能であることを確認しています。
このように、精度とCO2排出量のトレードオフはモデルの種類とデータセットに依存しますが、同一の手法で、任意のモデルに対して、精度の大部分を維持したまま排出量削減ができる可能性を確認できています。
今後、手法の適切な組合せによるCO2排出量削減と精度の最適化や、BERTやT5以外の言語モデルや画像・音声・マルチモーダルモデルへの適用、効果検証を進めていきます。
ソフトウェアの作りからのCO2削減アプロ―チ
今回ご紹介したように、ソフトウェアの観点からCO2削減へのアプローチは様々あります。こうした手法をまとめ標準化する団体として非営利団体のGSF(Green Software Foundation)があり、NTTデータも加盟し、脱炭素に向けた取組を強化しています(※9)。私たちは環境に優しいAIを開発することで、今後もAIによるイノベーションとサステナブルな社会の実現を推進していきます。







