「Spark 構築・運用ソリューション」の提供開始 ~オープンソースの並列分散処理による機械学習やストリーム処理など多様な処理ニーズの実現~
2015年10月19日
株式会社NTTデータ
株式会社NTTデータは2015年10月19日から「Spark構築・運用ソリューション」の提供を開始します。NTTデータは業務バッチ処理にとどまらず、ストリーム処理や機械学習処理等においても、並列分散処理をスムーズに導入できるようApache Sparkによる大規模環境での検証や商用環境への導入を推進してきました。今回、Apache Sparkコミッタ(主要開発者)を擁するNTTデータがこれまでに培ってきたApache Sparkの知見を生かし、「Spark構築・運用ソリューション」として、製造業分野をはじめとするお客さまへ広くサービス提供していきます。
背景
Apache Sparkは従来Apache Hadoopが得意としてきた大量データに対する高速なバッチ処理の実現に加え、機械学習処理・グラフ処理・ストリーム処理を同一のプラットフォームで実現できる新たなオープンソースの並列分散処理基盤として注目を集めています。NTTデータではお客さまからの要望に応える形で、大規模な環境でApache Sparkの動作検証を行ってきた注1ほか、商用環境への導入を進めてきました。
また、NTTデータは2014年からApache Sparkコミュニティーの中で運用性機能の改善を中心として、開発面での貢献を行ってきました。この活動が認められて2015年6月に、当社社員である猿田 浩輔が日本人で初めてApache Sparkのコミッタ(主要開発者)に就任しました。(写真)注2

写真:Apache Sparkコミッタ(主要開発者)に就任した基盤システム事業本部 主任 猿田 浩輔
NTTデータでは2010年より、「Hadoop構築・運用ソリューション」を提供しています。このサービスを通じてHadoopを中心としたオープンソースの並列分散処理基盤の導入コンサルティング・Hadoopクラスタ構築・サポートサービスの提供を行い、多くのお客さまがHadoopを安心して利用できるシステムを提供してきました。これに加えApache Sparkへの取り組みの実績をもとに培ってきた知見をソリューションとして整備し、「Spark構築・運用ソリューション」としてお客さまのApache Sparkの活用を支援します。
業務への適用例として取り扱うデータには、自動車から収集されるプローブ情報、重機・電機機器・航空機・船舶等に取り付けられたセンサーから生成されるデータ、ネットワーク基地局および交換機などから生成されるデータ、モバイルアプリから生成されるデータ、Web上のユーザーのアクセスログの処理などが挙げられます。絶え間なく生成されるこれらのデータを効率的に処理するのにApache Sparkは適しています。たとえば自動車業界や電機業界といった製造業をはじめとして、広い分野での活用を想定しています。
概要(特長)
NTTデータはお客さまのデータ活用シーンに応じて適切なApache Spark クラスタの構築を行います。Apache Sparkの導入において、Apache Spark自身が持つ機能を活用するだけでなく、運用システムとの連携やデータをやりとりする外接システムと連携を実現します。またデータをストリームで受け止めて低レイテンシーで異常値を検出する機能や時系列データを並列分散処理で効率的に扱うための知見をお客さまに提供します。またApache SparkをApache Hadoopと併用して運用し、メッセージングシステムであるApache Kafkaとの接続を行うことで、増大する負荷に耐えうるスケーラブルで柔軟なシステム構成をインテグレーションすることが可能です。(図)
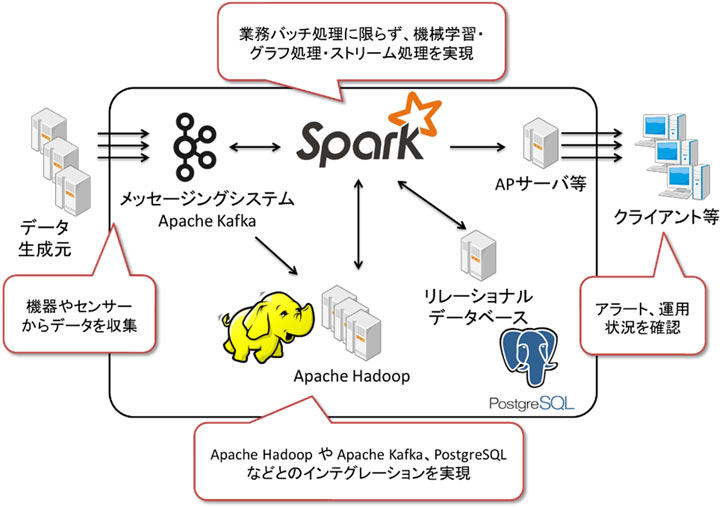
図:Apache Sparkと各種プロダクトを組み合わせた場合のインテグレーション例
NTTデータはApache Sparkの構築・運用だけでなく、導入検討時のコンサルティングも行います。お客さまのデータ処理要求に応じてアーキテクチャ検討を行い、Apache Sparkをどのように活用することでビジネスメリットが最大化できるかをご理解いただいた上で、Apache Sparkの導入を進めることができます。
NTTデータではApache Sparkを用いてシステムを構築・運用時に発生する各種問い合わせに対し、Sparkの専門技術者がサポートサービスとして回答を行います。Apache Sparkのソースコードを変更する権限を持つ技術者を有することにより、万が一運用時にクリティカルな問題が生じた場合でも、最終的な解決まで対応することができます。また、導入後の運用が長期間にわたっても責任を持ってサポートサービスを提供することが可能です。
今後について
ターゲットとする適用領域として、特に製造業分野における活用をめざしていきます。Apache HadoopやApache Sparkをはじめとするオープンソースの並列分散処理に精通した技術者約50名の要員をさらに拡大し、並列分散処理の導入をさまざまな業界・分野で進められるよう体制を整備していきます。NTTデータは、Apache Sparkの開発を担う企業としてとしてApache Sparkコミュニティーを先導し、Apache Sparkの高度化および品質向上を進め、さらに安心して便利に使えるものとなるように貢献してまいります。NTTデータでは今後3年間でApache Spark関連のビジネスで100億円の売り上げを目指します。
参考
現在、NTTデータとともにApache Sparkの導入を進めている、株式会社IHIの取り組みを、2015年10月19日の「NTTデータ Hadoopエンタープライズソリューションセミナー 2015 Autumn」にて発表します。
「NTTデータ Hadoopエンタープライズソリューションセミナー 2015 Autumn」開催概要
- 日時:2015年10月19日 10:00~17:30
- 場所:東京コンファレンスセンター・品川
(東京都港区港南1-9-36 アレア品川 3F-5F) - 参加方法:Webより申し込み
注釈
- 注1これまでの取り組みとして、CPU 4000 コア以上の大規模なクラスタ環境でのSparkの検証結果を、Spark Summit 2014およびHadoop Conference Japan 2014にて公開しています。
- 注2全世界でApache Sparkの開発に関与している約690名のうち、コミッタは41名に限られています。2015年10月19日現在、日本人で唯一のApache Sparkコミッタです。
- 文中の商品名、会社名、団体名は、各社の商標または登録商標です。
本件に関するお問い合わせ先
製品・サービスに関するお問い合わせ先
株式会社NTTデータ
基盤システム事業本部
システム方式技術事業部
OSSプロフェッショナルサービス
下垣、濱野、土橋
TEL:050-5546-2496

