
- 目次
レイクハウスフェデレーションで社内データ活用を効率化
IT部門にお勤めの皆さん、社内で以下のようなお悩みを抱えていませんか?
- (1)社内にある複数のデータソースのアクセス権限設定をする際に、アクセス制御方式が多種多様であるため、設定に多くのコストがかかる
- (2)データ利用者からデータが欲しいといわれるが、各組織に散逸しているため、スピーディーに対応できない
- (3)テーブルやカラムが元の外部データソースにどう由来するかを追跡する際に、過去のクエリーをその都度参照する必要があり、多くのコストがかかる
- (4)上位層から、複数のデータソースを用いたデータ活用施策の実施を要求されているが、多大な初期コストが懸念される
それらのお悩み、レイクハウスフェデレーションというDatabricksの新機能であれば、以下のように解決できるかもしれません。
- (1)Databricksに接続されたすべての外部データソースに対して、統一的な権限設定ができる
- (2)テーブルやデータ、カラムを全データソースにわたって横断的にDatabricks上で検索できる
- (3)データがどのデータソースから来てどのように加工されたのかといったデータ来歴を、Databricks上で容易に確認できる
- (4)複数のデータソースを組み合わせたデータ活用を、データ移行を伴わずスピーディーに実施できる
Databricksがレイクハウスフェデレーションを生み出した背景
Databricksとは、大規模データの収集・蓄積から、データの分析・可視化さらには、機械学習や開発支援を一気通貫で提供するクラウドベースの統合分析プラットフォームです。
代表的な機能である「レイクハウス」は、データウェアハウス(DWH)とデータレイクの両方の機能を持ち合わせたものです。そのため、レイクハウス上で、様々なデータを一箇所に集約し管理することができます。
しかし、複数データソースに存在するデータを加工し、一箇所に移動させる必要があり、金銭的・時間的コストがかかります。
この課題を解決するための技術がデータ仮想化です。
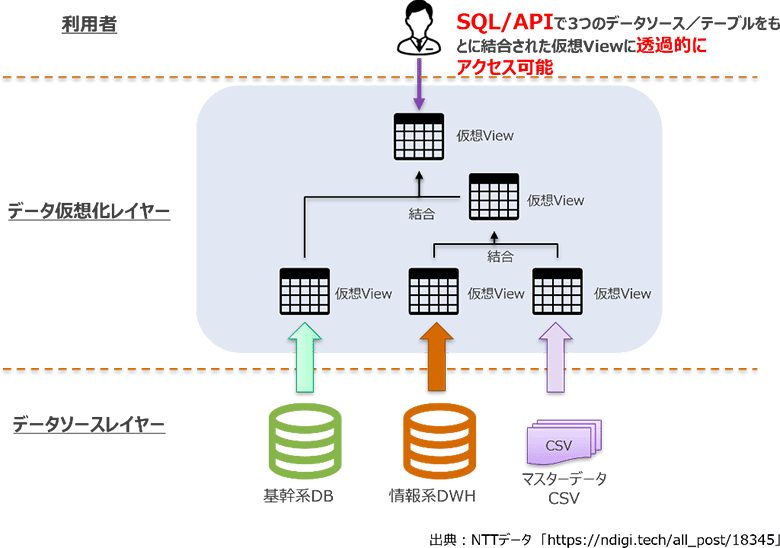
図1:データ仮想化技術のイメージ
データ仮想化とは、複数のデータソースに存在するデータを、1つのデータ仮想化レイヤー上で論理的に統合する技術です。データウェアハウスのように、データを予め一箇所に蓄積・統合させることなく、オンデマンドでデータを提供することができます。
データ仮想化による主なメリットは以下の3つです。
- (1)リーズナブルかつ軽量にデータ活用が可能
- (2)サイロ化されたデータをリアルタイムで連携できる
- (3)一元的にデータガバナンスを実施できる
データ仮想化技術の詳細はこちら:
データを蓄積せずにデータ活用を推進? ~ロジカルデータファブリックを活用するデータ活用推進アプローチのすすめ~
Databricks上でデータ仮想化技術を実現した機能が、レイクハウスフェデレーションです。
レイクハウスフェデレーションとは、複数データソースに存在しているデータをDatabricks上で一元的に管理できる機能です。複数データソース内のデータをデータレイクやデータウェアハウスに移動せずとも、簡単にデータ検索やクエリー実行、ガバナンスをDatabricksから実施できます。
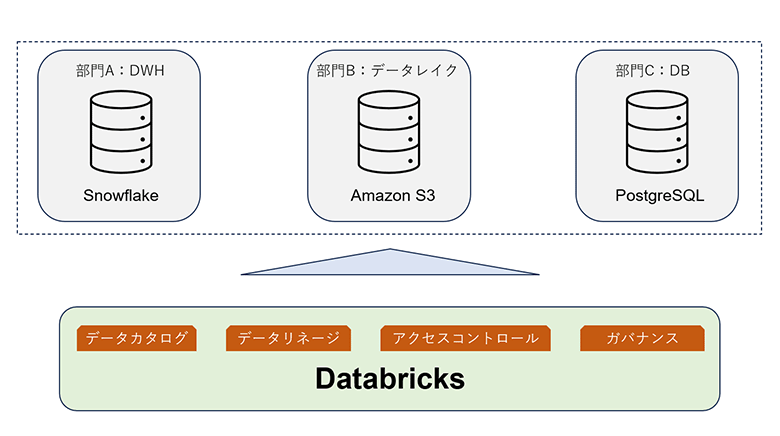
図2:レイクハウスフェデレーション概念図
次章でレイクハウスフェデレーションの機能の詳細を見ていきます。
レイクハウスフェデレーションの4つの特長
レイクハウスフェデレーションでの機能の特長は4つあります。それぞれ説明していきます。
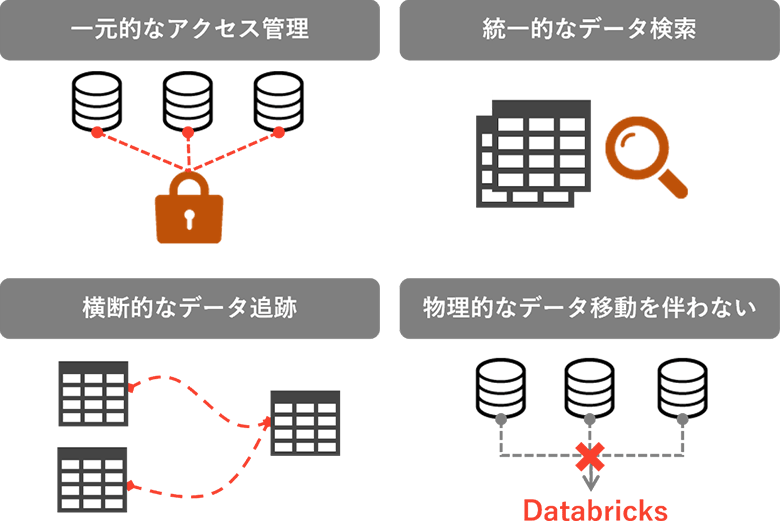
図3:レイクハウスフェデレーションの4つの特長
一元的なアクセス管理
複数データソースを管理する際に、アクセスコントロールやガバナンスの観点がしばしば課題となります。「社内にデータソースが多く存在し、個々のアクセスコントロールの設定が面倒だ」というお悩みを抱えてはいらっしゃらないでしょうか?
レイクハウスフェデレーションでは、Databricksに接続されたすべての外部データソースに対して、Databricksのデータガバナンスソリューション「Unity Catalog」を適用可能です。Unity Catalog は接続したデータソースに対して統一的な権限設定を可能とします。これにより、データソースごとにアクセス制限や権限の設定を行う必要がなくなり、データガバナンスの管理が大幅に単純化されるのです。また、カラムマスキングやレコードレベルの閲覧制御の機能によって、きめ細やかなアクセスコントロールが実現できます。
統一的なデータ検索
様々な事情からデータ基盤(DB・DWH・データレイクなど)が社内に複数存在する場合、データに関する調査のコストや難易度は高くなります。各データ基盤にどのようなデータが格納されているのか、また格納されているデータの詳細情報がどういったものかを知りたいといった状況は数多くあります。その際、各データ基盤上にアカウントを作成し確認する、各基盤管理者に問い合わせるなど、多くの時間・コストが必要です。
レイクハウスフェデレーションでは、Unity Catalogのデータカタログ機能を、接続した外部データソース全体に拡張できます。これにより、テーブルはもちろん各メタデータにいたるまでDatabricks上で統一的に確認が可能です。テーブルやデータ、カラムを全データソースにわたって横断的に検索でき、また各データに対するメタデータを参照することもできます。本機能によって、データのサイロ化を解消することができます。
横断的なデータ追跡
業務要件の制約から、外部データソースからSQLでDatabricksにテーブルを読み込んだ上で、データ加工・分析・機械学習を行うケースが多くあります。その際、使用するテーブルやカラムが、元の外部ソースにおいてどのテーブル・カラムだったかを判定すること(データリネージ)は容易ではありません。データ読み込み時に使用した実際のクエリーを確認して記載を追う手間がかかるからです。また、接続する外部データソースの数が増加するにしたがって、データリネージはより煩雑になります。
レイクハウスフェデレーションでは、Unity Catalog上で可視化されたリネージグラフを確認できます。このため、作成されたデータがどのデータソースから来てどのように加工されたのかといったデータ来歴の調査コストや、データ変更時の影響確認にかかるコストが大幅に削減されます。
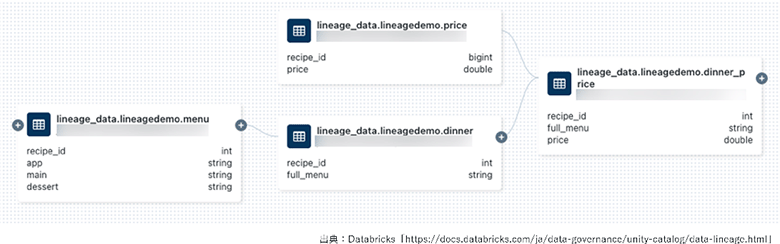
図4:リネージグラフ
物理的なデータ実体の移動を伴わない
社内の各データソースに分散したデータを活用するとき、「初期コストが高すぎるために実施が困難だ」というお悩みはしばしば聞かれます。複数のデータソースを組み合わせたデータ分析の効果を検証したい場合、データソースを統合させることに時間的・金銭的コストがかかるためスピード感のある検証の実現が難しいのです。
レイクハウスフェデレーションでは、複数データソースの統合において外部ソースのデータの実態は外部ソースに保持され、物理的なデータの移動を伴いません。したがって、データ移行を伴わずスピーディーにPoCを実施し、取り組み要否を判断することができます。また、セキュリティポリシー上の理由でデータをDatabricksに取り込むことが望ましくない場合においても、データの移動を伴わないレイクハウスフェデレーションのメリットを享受することができます。
他のデータ仮想化製品との比較
データ仮想化技術を活用したデータプラットフォームサービスは、他にもいくつかあります。ここからは、レイクハウスフェデレーションと他のデータ仮想化製品を、複数の観点から比較します。
表1:レイクハウスフェデレーションと他のデータ仮想化製品の比較
| レイクハウスフェデレーション | 他のデータ仮想化製品(一例) | |
| 料金 | 〇 DBU当たりの課金方式 | △ 年間契約 |
| データ活用 | 〇 Databricks内で活用可能 | △ 他ツール等の導入が必要 |
| データソース | △ 2023年11月時点で7種類 | 〇 より多くのものに対応 |
| 大規模処理への移行 | 〇 容易 | △ 煩雑 |
料金
他のデータ仮想化製品の中には、年間契約による課金方式を採用しているものもあります。一方で、Databricksは使用した「DBU(Databricks ユニット)」当たりの課金方式を採用しています。DBUとは、Databricksレイクハウスの処理能力を規格化した単位であり、ワークロードが消費するDBUの数は、使用するコンピューティングリソースや処理するデータ量などの処理指標によって決まります。そのため短期間の利用や、利用期間が予測できないようなケースでは経済的な選択肢であるといえます。
データ活用
レイクハウスフェデレーションによって収集されたデータは、Databricksの機能により容易かつ迅速に活用することができます。Databricksは、データの収集・蓄積から機械学習モデル開発や運用を一気通貫で行うことができる統合プラットフォームです。ゆえに他のツールの導入をすることなく、同一プラットフォーム上でデータ活用できるというメリットがあります。
データソース
レイクハウスフェデレーションでサポートされているデータソースは2023年11月時点では7種類(MySQL, PostgreSQL, Redshift, Snowflake, Microsoft SQL Server, Azure Synapse, Databricks)です。他のデータ仮想化製品の中には、以上のデータソースに加えてAmazon AthenaやOracle Database等といったように幅広く対応しているものがあります。
大規模処理への移行
一般的に、データ仮想化製品はDWHに比べてデータ処理速度が遅くなります。これは、データ仮想化では都度ビューの加工や結合処理が必要となるためです。そのため、データ仮想化製品をPoC段階では使用していたものの、データが大規模になるにつれ性能が求められ、新たにDWHを構築することがあります。Databricksであれば、レイクハウスフェデレーションで仮想化を実施しつつ、DWHも内部で構築できることから、PoCからの移行が容易であるといえます。
以上4つの観点での比較から、大規模データへの移行や機械学習モデル開発を見据えつつ、PoCで小規模データを利用したいケースでは、レイクハウスフェデレーションを特にお勧めします。
おわりに
NTT DATAはDatabricks社とパートナー契約を締結しています。加えて、複数の事例を通してDatabricks環境構築のノウハウを蓄積しています。レイクハウスフェデレーションに少しでも興味がありましたら、お気軽にお問合せください。
レイクハウスフェデレーションの具体的な利用方法についてはこちら:
https://docs.databricks.com/ja/query-federation/index.html
あわせて読みたい:








「レイクハウス」とDWH、データレイクの違いについてはこちら:
https://www.nttdata.com/jp/ja/data-insight/2023/0620/