
1.パフォーマンストラブルがなくならない背景
CPUやメモリ、ディスク等のハードウェア性能は年々向上し続け、クラウドを活用しているシステムでは必要に応じてサーバー増強が容易にできる時代です。それにも関わらず、スローダウントラブル(性能問題)は発生し続けているのはなぜでしょうか。
背景には、従来に比べてシステムの複雑性が増す一方で、開発期間や工数は削減傾向にあり、開発期間中に十分リスクを除去しきれずにカットオーバを迎えるシステムが増えている現状があります。
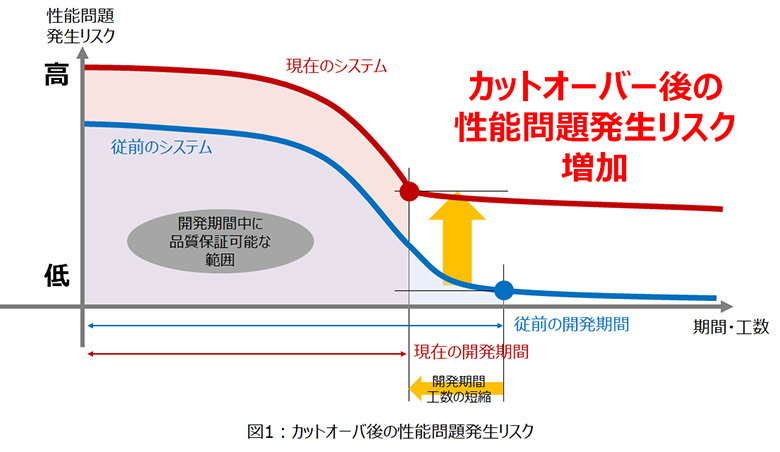
2.近年のパフォーマンストラブル傾向
2022年~2023年にかけてのパフォーマンストラブルの直接原因を見ると、半数はデータベースとなっており、この傾向に変化はありません。ネットワーク原因の多くはコロナ禍によるリモートワーク環境の問題であり、2023年には収束傾向が見られます。
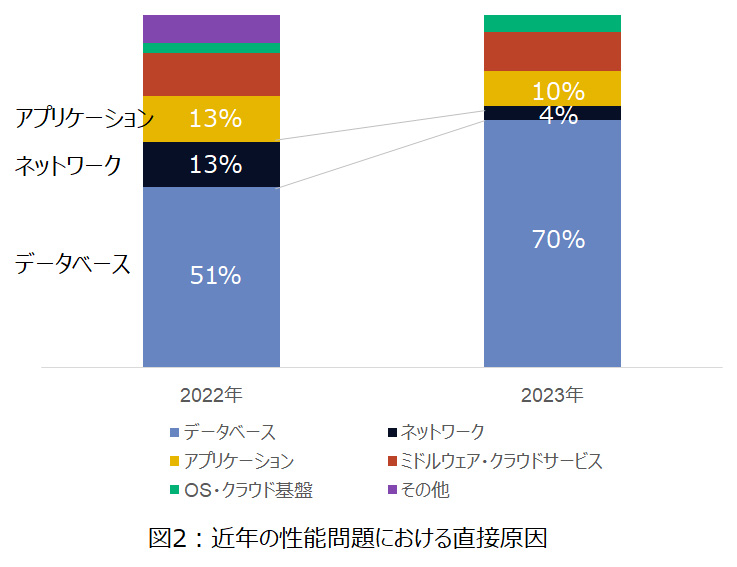
ここから、実際にあったスローダウン事例を紹介していきます。
3.パフォーマンストラブル事例
(1)想定外の「ユーザーデータサイズの分布」
ユーザーが編集したファイルをアップロードする機能を備えたシステムの事例です。
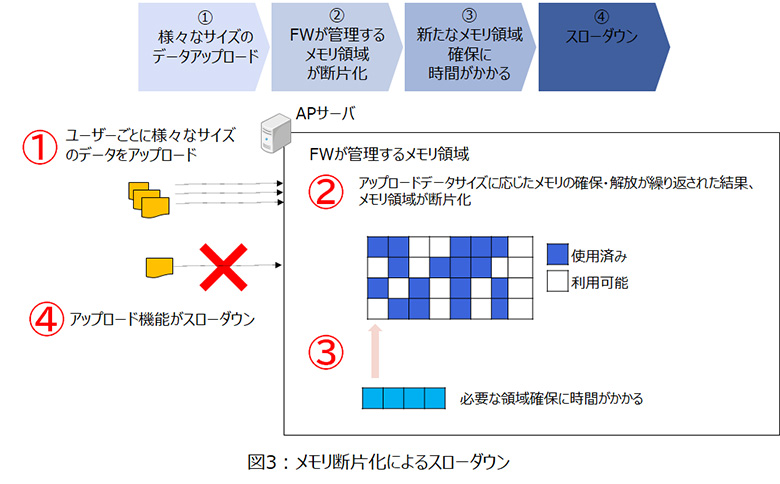
アプリケーションサーバー上のフレームワークでは、アップロードされたファイルのメモリ領域へ展開が行われ、処理が終了すると展開された領域を開放する処理となっていました。性能試験では問題なく処理できていたのですが、運用開始後、アップロード機能がスローダウンするトラブルが発生。
調査すると、アップロードされるデータサイズがユーザーによって異なるため、メモリ領域の確保と開放が繰り返されると利用可能領域が断片化し、必要な領域確保に時間を要していることが原因と判明しました。
(2)想定外の「リモートワーク急増」と「テレワーク様態の変化」
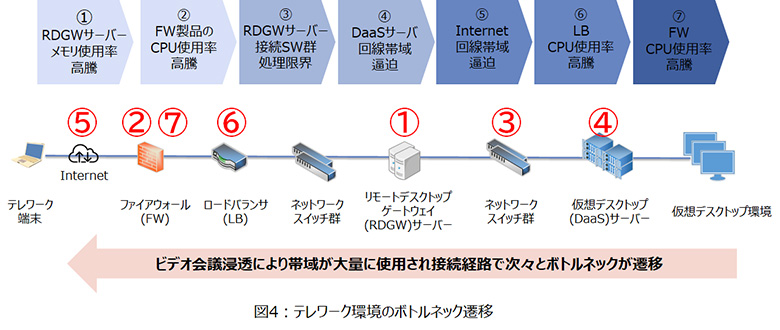
コロナ禍によりリモートワークユーザーが数週間のうちに7倍に急増した事例です。
トラブル発生当初に取り組んだのは、伝送経路上の各サーバーのCPUやメモリを中心としたボトルネック解消。
しかし、テレワークが浸透し、ビデオ会議の使用頻度が高くなるにつれ、ボトルネックがネットワーク帯域や機器のCPUへと遷移していきました。
4.事例から見えてくる共通項
今回紹介したパフォーマンストラブルの事例には、2つの共通項があります。
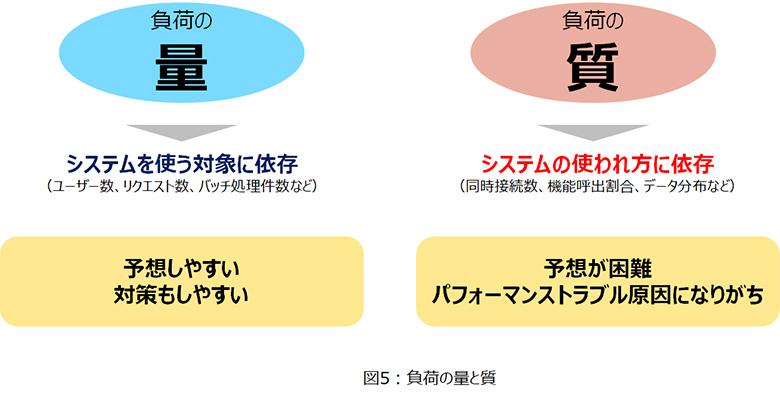
- 負荷の「量」(高負荷にシステムが耐えられなかった)
- 負荷の「質」(システムの使われ方が想定と異なっていた)
パフォーマンストラブル防止には、この負荷の「量」と「質」の両方に対策することが重要となります。
「量」に関しては、自動的にサーバースペックを変動させるオートスケール等、容易な対策が出てきていますが、「質」に関しては予想が難しいため、試験による検証もできないことが多く、近年のパフォーマンストラブルの原因となりがちです。
前述したように、システムの複雑性が増し、短期間での開発が求められるなか、負荷の「量」「質」の両方へどのように対応すれば性能品質が確保され、パフォーマンストラブルから開放されるのでしょうか。
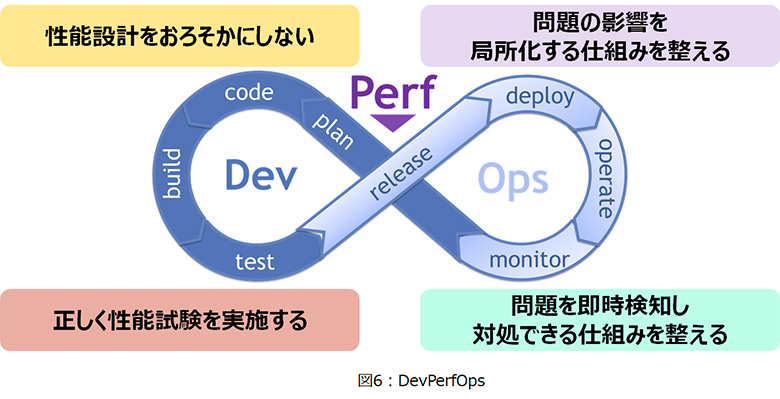
5.性能品質担保のポイント
私たちは、開発と運用の両面で性能品質を継続的に担保し続ける方法論として「DevPerfOps」という概念を提唱しています。そのポイントは4つです。
- (1)性能設計をおろそかにしない
- (2)正しく性能試験を実施する
- (3)問題の影響を局所化する仕組みを整える
- (4)問題を即時検知し対処できる仕組みを整える
(1)性能設計をおろそかにしない
ハードウェア資源を柔軟に追加できるクラウドを含め、いかなるプラットフォームにおいても性能設計は必須です。
性能要件を反映していく際に「量に対する設計」だけでなく、「質に対する設計」も欠かせません。
また、SaaS(※)を活用する場合、SaaS提供範囲は性能が保証されなかったり、性能試験ができないもサービスも多かったりするため、選定には注意が必要です。

(2)正しく性能試験を実施する
性能設計が目論見通りに機能していることを確認する性能試験では、運用状況を可能な限り模擬することが重要です。この模擬が正しくできていないと「性能試験では問題なかったのに、サービス開始後にパフォーマンスが発揮されない」事態に陥ります。
「クライアント」「データ」「マネージドサービス」「連携システム・サービス」という4つの領域をポイントに、正しい性能実験を実施することが重要です。

(3)問題の影響を局所化する仕組みを整える
どれほど精緻な性能設計・性能試験を実施しても全ての問題へ対処できないリスクは残ります。そのため、万一どこかにボトルネックが発生しても、システム全体・ユーザー全体への影響を極小化し、システムの全滅を防ぎ、お客様のビジネスを守ることが非常に重要です。下記は、小さな問題がシステムダウンに至るトラブルの引き金とならないために欠かせない仕組みの一例です。
- システムの過負荷を防ぐ「流量制御」
- データベースを健全な状態に維持する「DBメンテナンス」
- 連携システムも含めた「異常検知」

(4)問題を即時検知し対処できる仕組みを整える
(1)「性能設計」(2)「性能試験」(3)「影響局所化」を施してもなお、トラブルが発生してしまった場合は、迅速に検知し、対処することが重要です。
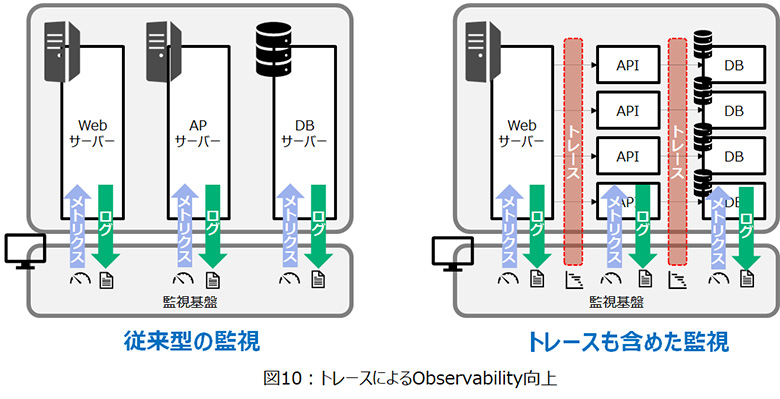
マイクロサービスアーキテクチャ(MSA)に代表されるように、近年ではシステムの構成要素が複雑化しているため、従来のメトリクス監視、ログ監視だけでは原因箇所や影響範囲を短時間で特定することが困難なケースが多くなっています。そのため、Observability(可観測性)の向上のための仕組みとしてAPM(Application Performance Management)に代表される製品の導入も重要です。システム内で発生した処理の一連の流れ(トレース)も合わせて、システムの状態を可視化することが問題へのスピーディな対処を実現するポイントとなります。
システムのスローダウンを起こさないために、私たちは開発工程から運用工程において、上記の4つのポイントを繰り返し適用することが必要不可欠であると考えています。
最後に、本稿をご覧いただき、スローダウン対策に興味を持たれた方は、当社のプロフェッショナルサービス「まかせいのう」へぜひお問い合わせください。
Software as a Service。サービス提供者が管理するサーバー上に構築されたソフトウェアを、利用者がインターネットを通じてアクセスして利用するサービス形態。








「まかせいのう」の詳細はこちら:
https://www.nttdata.com/jp/ja/lineup/macaseinou/
あわせて読みたい: