
RAIDのデータが消滅する?
ハードディスクの容量は1990年代の2GBから近年は3TBまで、20年で3桁大きくなりました。一方で読み取り時のシークタイムは10msから3msに改善されたに過ぎません。入出力インターフェースもSCSIの20MB/秒から、SAS/eSATAやFCの500MB~1GB/秒へ1~2桁しか伸びていません。ディスクの回転数は4000rpmから15000rpmになった程度で、あまり変化がありません。総合すると、1台の大容量ディスクの中身全体にアクセスするための時間は、20年間で50~500倍長くなっていることがわかります。これは、RAIDのリビルド(RAIDを構成している複数のディスクのうち1台が壊れた場合に交換復旧する作業)に必要な時間がそれだけ長くなることを意味しており、「RAIDのリビルド中に別のディスクが壊れてデータが失われる」リスクが無視できなくなってきます。また、超大容量ストレージを実装する場合、コストと消費電力を減らすため、遅くて大容量のディスクを大量に使わざるを得なくなるため、通常に比べリスクが飛躍的に高まります。(表)では、PBクラスの超大容量ストレージにおけるリスクを定量的に評価していますが、構成によっては安心できない状況になっています。
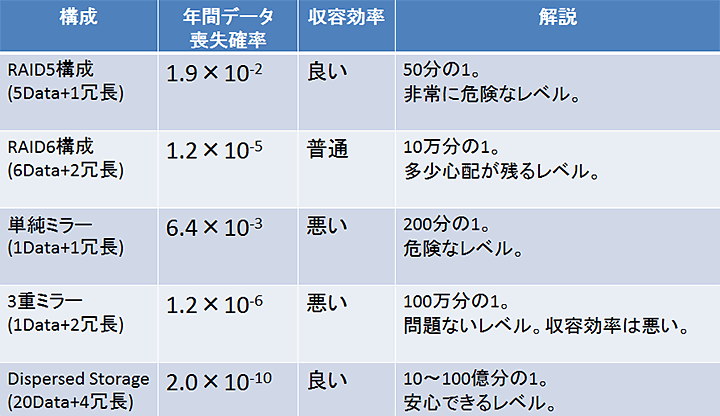
表:1PB(1000TB)の超大容量ストレージにおける年間データ喪失リスク試算
計算条件と補足
- ディスク故障率は5%/年、データの部分破壊(bit rot等)は考慮しない。
- ディスク容量は1個あたり1TB、リビルド速度は25MB/secとした。
リスクを減らす技術
リビルド中のリスクを減らす策は様々あります。例えば以下のような技術の活用です。
- 1.3重以上のミラー
2重でダメなら3重、3重で心配なら4重と、単純に複製を増やす方式です。容量効率は1/nになっていきますが、3重ミラーとすると、(表)のRAID6の数倍の信頼性を期待できるため、要件によっては十分でしょう。狭義のRAIDではありませんが、Openstack Swift参考やHadoopはデフォルト設定でデータを3重に格納して保護しています。
- 2.ワイドストライピング
データを細分化し、RAIDを構成する多数のディスクに冗長化して収容する方式です。並列化により高速化を図ると共に、ドライブごとではなくセクタ毎に障害検出/退避をする、など、きめの細かい制御を行ってアクセスを最適化しており、リビルドも高速に実施できます。最近のRAIDの多くが採用していますが、ディスクが多重で故障した場合への耐性には限界があります。また、リビルド中の性能に影響があるため、要件毎に必要な信頼性と性能を満たすか、個別に精査することが必要でしょう。
- 3.Dispersed storage
通信の世界で昔から使われてきた「誤り訂正符号」をストレージに応用した方式です。任意のディスク数に対して任意の冗長度を設定できるため、設計次第で極めて高い信頼性を得ることができます。例えば15台のディスクの中の任意の5台が故障してもデータが読み取れる構成も実現可能です。この方式はデータの入出力が符号化/復号化になるため計算量が通常より大きくなりますが、ハードウェアの計算能力が高速化しているため、現在は問題ではなくなりました。また、多数のディスクを並列に動作できるため、低速大容量HDDを活用した低価格、低消費電力、高信頼性、高スループットのストレージという、最近のクラウド、ビッグデータの時代の要件にマッチした仕様を実現することができます。数百TB~PB以上の大容量ストレージとして、実用が増えています。
要件に応じて最適な方式を選択することが大切だと考えています。
