
1.データサイエンスと、データサイエンスにおけるデータ保管の歴史(データウェアハウスからデータレイク)
データサイエンス(※1)の手段は、データ戦略(※2)、データ分析(※3)から始まり機械学習(AI)(※4)まで大きく広がってきました。そして、データサイエンスを支えるインフラストラクチャー=データインフラ(※5)、特にデータの保管場所(以下、データの保管場所=データストアとする)は非常に大きな進化してきています。
最も初期はRDBMS(※6)が利用されていました。RDBMSはトランザクション処理に適した構成である一方、データ分析に必要なデータ集計や大量スキャンに適した構成になっておらず、性能面の課題がありました。この課題を解決するものとしてDWH(※7)が登場し、現在でも幅広く利用されています。
その後、ストレージやCPUの低コスト化、分散処理技術の進化、データインフラのソリューションや扱うデータの種別が増加しました。具体的には、それまでの表形式データ等(RDBMS、CSV等)の構造化データから、センサーデータやログデータ等(XMLやJSON等)の準構造化データにまで広がりました。
そして、ディープラーニングを機とする第三次AIブーム(※8)により、データ活用の手段に機械学習も使われ始め、扱うデータの種別が音声や画像などの非構造化データまで拡大。ほぼ同時期のパブリッククラウドの普及に伴い、データインフラのソリューションとしてオブジェクトストレージ(※9)が普及します。
オブジェクトストレージは準構造化データや非構造化データをファイルとして扱う事ができ、かつ低コスト、実用上無制限のスケーラビリティという利点があります。これらの利点から、オブジェクトストレージはデータストアとして準構造化データ、非構造化データだけでなく構造化データをも保管するようになりました。これが事実上のデータレイク(※10)として活用され、さまざまな分析に用いられることになったのです。
また機械学習、特にディープラーニングでは、ログデータ等の準構造化データや画像等の非構造化データを大量に扱うユースケースが多い事から、データレイクとしてオブジェクトストレージを利用する方が好都合でした。
そのため、DWHが前提となるデータ可視化(BI)(※11)にはDWHを利用しつつ、機械学習(AI)のためにオブジェクトストレージも併用するアーキテクチャーが多く活用されてきました。
しかしこのアーキテクチャーには、長年利用する事による維持コスト・運用負荷の高止まりという課題がありました。具体的な課題をいくつか挙げます。
- あらゆるデータをデータレイクに入れてしまった結果、分析に必要なデータが簡単に見つからない(データレイクの沼化)
- データレイクにトランザクション処理がサポートされておらず、データ品質が低下する
- データ可視化(BI)のように高いレスポンスが求められるワークロードに、データレイクの性能が追いつかない
- データレイクをDWHへのデータとりこみの保管庫とする場合、データレイクとDWHでデータが2重持ちになってしまう
- 両システム間のデータ移動にETLが必要となり、開発コストが増加する
- テーブルとファイルのアクセス制御方式の違いによるデータガバナンスの不整合が生じる
これらの課題を解決するために出てきた概念が、「レイクハウス」です。
データ戦略、データ分析、データインフラ、データマネジメントの包含。データ活用とも言われる
事業戦略達成のため、データ分析による業務改革・高度化・最適化や新サービスの構想やシステム像を作成する事。また、構想の具体化やシステム実現を主導する事
データ可視化、数理最適化、機械学習等の包含
解きたい課題に関連するデータを機械学習のアルゴリズムにより学習し、推論モデルを作成する。未知データに対して推論モデルから予測する。近年はディープラーニングが機械学習として有名
データ分析や機械学習のもととなるデータストアや分析・学習を実行するためのインフラストラクチャーを設計運用する
Oracle Database, PostgreSQL, MySQL, SQL Server等のトランザクション処理を目的としたデータベース。関係データベースともいわれる。(ただし、近年ではDWH機能を持ち始めている)
Teradata, Oracle Exadata, Vertica, Amazon Redshift, Snowflake等の主にデータ分析に必要な集計、結合、大量スキャン等の処理に特化したデータベース
https://www.soumu.go.jp/johotsusintokei/whitepaper/ja/h28/html/nc142120.html
フォルダーやディレクトリのように階層構造でなく、Amazon S3, Azure Data Lake Storage, Google Cloud Storage等のオブジェクトとメタデータでフラットな空間で管理される保存域。(ただし、階層構造を持つオブジェクトストレージも存在)拡張性に優れている
構造化データ、準構造化データ、非構造化データを保管するデータ保管の領域であり、ほとんどの場合オブジェクトストレージが採用される。データの状態も加工前状態や分析用に加工した状態等さまざまである事を是とする。DWHやRDBMSと異なりスキーマ(データの構造)を必ずしも定義しない
データを集計、統計処理したものを表・グラフ化し、ダッシュボードとして可視化する
2.レイクハウスの定義
これらの課題を解決するために、「レイクハウス」という概念が出現します。レイクハウスはDWHとデータレイクの強みをうまく補完した特徴をもっており、「データ可視化(BI)と機械学習を透過的に扱う」「構造化データ、準構造化データ、非構造化データの統合」「ACID(※12)への対応」といった特徴をもちます。
レイクハウスの特徴
- 単一、あるいは一貫したアーキテクチャーによるデータ可視化と機械学習の両立
- 複数ユースケースの統合(データ可視化(BI)、機械学習(AI))
- 非構造化データも一貫した操作で行える(DWH視点でデータレイク機能の取り入れ)(Amazon Redshift integration for Apache Spark等)
- 大量データを取り扱え、スケーラビリティも確保
- バッチとストリーミングの統合
- 構造化データ、準構造化データ、非構造化データの蓄積と利用
- ACIDトランザクションのサポート(ACIDによる厳格なデータ操作)
- ファイルとテーブルの両方に対応したアクセス制御によるガバナンスの向上(テーブルに対する行列レベルの細かなアクセス制御を含む)
- データの特性に応じたSchema On Write(※13) / Schema On Read(※14)の使い分け
- データの冗長性の排除、データ可視化(BI)、機械学習(AI)に適したストレージ選択によるコストの最適化(安価なオブジェクトストレージに、構造化データをオープンなファイル形式(CSV, Avro, parquet等)で保存し、そのままDWHのように利用可能)
上記特徴はそれぞれ、DWH、データレイクの特徴を継承したものです。
DWHの特徴(DWHの強みとなる機能のうち、レイクハウスに継承された機能)
- ACIDトランザクションのサポート(ACIDによる厳格なデータ操作)
- テーブルに対する行列レベルの細かなアクセス制御
- (分析ユースケースによるが)構造化データの分析においては、DWHはデータレイク(オブジェクトストレージ)よりも高速な処理をできる事が多い
- Schema On Write
データレイク(オブジェクトストレージ)の特徴(データレイクの強みとなる機能のうち、レイクハウスに継承された機能)
- 準構造化データや非構造化データまで扱える(準構造化データや非構造化データの幅広いデータをPython等のプログラム言語から自由に加工・分析に用いる事ができる)
- 構造化データをオープンなファイル形式(CSV, Avro, parquet等)で保存できる
- Schema On Read
- DWHに比べて、データレイク(オブジェクトストレージ)は単価が低いため、コストを低減できる
なお、レイクハウスの定義は一意ではなく、企業や研究者から提唱されている内容に少しずつ揺らぎがあるのも事実です。参考までに、代表的な定義を紹介します。
表:レイクハウスの各方面での定義
| 企業や研究者 | レイクハウスの定義 |
|---|---|
| ベンダー1(Amazon Web Service) | Lake Houseのアプローチは、データレイクとデータウェアハウスを統合するだけでなく、データレイク、データウェアハウス、その他すべての専用サービスを一貫した全体に接続する(※15) |
| ベンダー2(Databricks) | データレイクハウスとは、データレイクの柔軟性、経済性、スケーラビリティとデータウェアハウスのデータ管理やACIDトランザクションの機能を取り入れたオープンで新たなデータ管理アーキテクチャーで、あらゆるデータにおけるビジネスインテリジェンス(BI)と機械学習(ML)を可能にします(※16) |
| 調査機関(Gartnar) | データウェアハウスとデータ・レイクのアーキテクチャーおよび機能を統合し、単⼀プラットフォーム(通常はクラウド)に展開する統合型のデータ・アーキテクチャーである。これにより、アーキテクチャーの冗⻑性を削減できる(※17) |
| 研究者(Bill Inmon) | データレイクの信頼性と品質の確保 ガバナンスとセキュリティ制御 性能の最適化(※18) |
データのトランザクション処理の信頼性を保証するために求められる性質。不可分性(atomicity)、一貫性(consistency)、独立性(isolation)、永続性(durability)の頭文字をつなげてACIDと呼ばれます
テーブルの定義(スキーマ)を事前に定義した上でテーブル作成、データを書き込むため、データとスキーマの整合が保証される事
テーブルの定義(スキーマ)は別途メタデータとして保持し、データを読み取るときにデータとスキーマの整合を確認する事
参照先:https://aws.amazon.com/jp/blogs/big-data/build-a-lake-house-architecture-on-aws/
データ・レイクハウスとは何か ,2022
Bill Inmon. Building the Data Lakehouse.,Technics Publications ,2021
3.レイクハウスのアーキテクチャーパターン
レイクハウスのアーキテクチャー(構成)は、下記のような構成パターンが存在します。厳密には、構成パターン1のみがレイクハウスアーキテクチャーです。しかし構造化データ、準構造化データに対してレイクハウスアーキテクチャーの特徴を実装し、非構造化データのみオブジェクトストレージを利用するアーキテクチャーやソリューションも存在します。そのため、パターン2も広義のレイクハウスアーキテクチャーとして説明します。
3-1.構成パターン1 オブジェクトストレージ単一型(狭義のレイクハウス)
オブジェクトストレージを、単一のデータストアとして利用する構成です。構造データのデータ分析については、ACID特性をサポートするデータフォーマット(Iceberg, Delta Lake, Apache Hudi等)に変換して保持する事が特徴です。
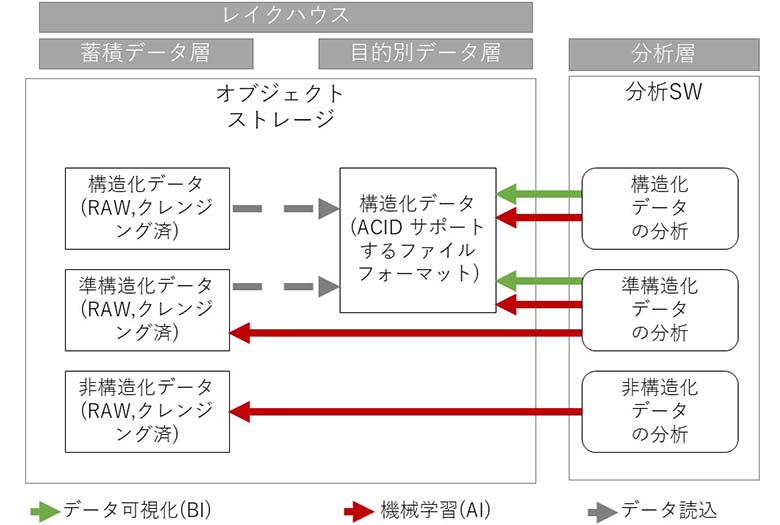
図1:オブジェクトストレージ単一型(狭義のレイクハウス)
- 特徴:構造化データや準構造化データは、RAWあるいはクレンジング済みデータに加工し、ACID機能を持つオープンなファイルフォーマット形式にしてオブジェクトストレージに保存。非構造化データはオブジェクトストレージに保存。これらのファイルに対してPython等のプログラムやソリューションからデータ分析を実行
- メリット:単一のデータ・アーキテクチャーであり、データの冗長性が極めて少ない
- デメリット:ACID機能を持つオープンなファイルフォーマット(Iceberg, Delta Lake, Apache Hudi等)やSpark等分散処理の専門知識を要することが多い
3-2.構成パターン2 オブジェクトストレージとDWH併用型(広義のレイクハウス)
オブジェクトストレージとDWHを組み合わせた形です。今までもあった形ですが、DWHへ機械学習の処理ができる点が異なります。
また多くのクラウドプラットフォームやDWH製品は、データ取り込みの自動化や外部呼び出しにより、容易なデータ取り込みやデータ重複の防止が可能になっており、以下デメリットに挙げる課題も減りつつあります。
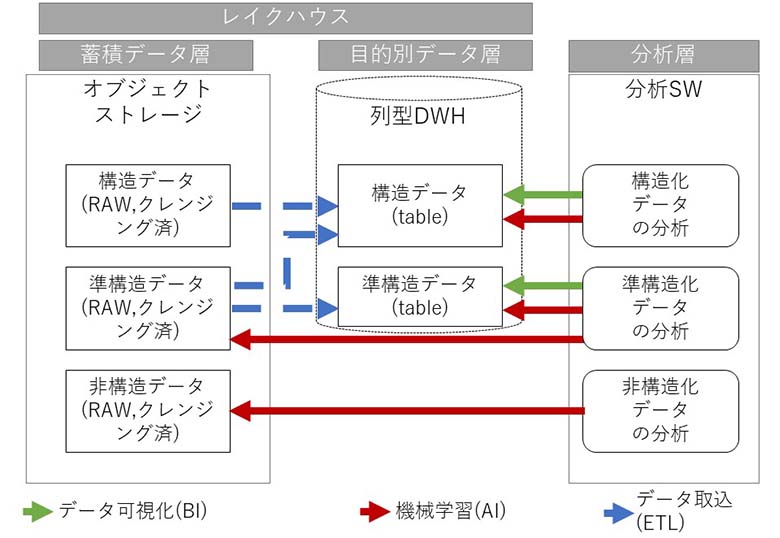
図2:オブジェクトストレージとDWH併用型(広義のレイクハウス)
- 特徴:構造化データや準構造化データはオブジェクトストレージに保管し、RAWデータあるいはクレンジング済みデータに加工したデータをDWHに保管。非構造化データはオブジェクトストレージに保存。これらのファイルに対してPython等のプログラムやソリューションからデータ分析を実行
- メリット:構造化データや準構造化データへのデータ分析や機械学習にDWHを利用する事ができ、運用面と性能を両立できる
- デメリット:単一のデータ・アーキテクチャーでない。データ重複の発生、データ取り込みの処理が発生。データストアのコストが完全に最適化されているとは言い難い
4.まとめ
レイクハウスはDWHとデータレイクの強みを補完しあう概念です。実際の導入においては、レイクハウスのアーキテクチャーの強みを維持しつつ課題解決に合わせた形(多くの場合ではスケーラビリティの確保、ガバナンスと利便性の両立、コストの最適化)で柔軟に拡張できるように設計する事が大切です。
NTTデータは、データサイエンスのグランドデザインから構築運用までの一気通貫支援はもちろん、小規模から大規模への対応、こなれた技術から最新技術まで幅広い形で 支援します。
NTTデータのデータ活用サービス
https://www.nttdata.com/jp/ja/services/data-and-intelligence/
