
ビッグデータ活用のメリット
2010年代のITにおける大きなトレンドの1つとして、ビッグデータの活用に対する期待が、「社会」「企業」「個人」の各観点で大きくなっています。
- 「社会」
限られたリソースを最適に配分することで、社会全体を効率的に運営していく必要がある。
- 「企業」
経営状況の見通しが難しい現状において、あらゆる環境変化に対して即時に対応していく必要がある。
- 「個人」
ユーザの行動に沿った、気の利いたサービスを適切なタイミングで提供していく必要がある。
こうした状況の下、早い段階でビッグデータ活用に取り組んだ企業は、的確な状況把握と迅速な意思決定が可能となり、経営メリットや競争優位性を顕在化させています。
ビッグデータ活用のための基盤技術モデル
データベース構成
ビッグデータを活用する前提として、様々なデータ(膨大な量・粒度・鮮度)に対応可能なデータベース構成が必要となります。従来の情報システムはRDBMSを中心に構築されてきましたが、最近ではNoSQLの利用も増えています。RDBMSはアドホックな集計、NoSQLはバッチをベースとした集計と、それぞれ異なる特性を持つため、ビッグデータ時代では両者を目的や用途に応じて選択/組み合わせたデータベース構成が求められます。(表)
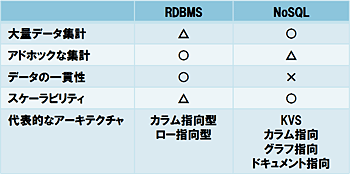
表:RDBMSとNoSQLの特性
データ処理方式
ビッグデータの処理方式は、リアルタイムに発生するデータと蓄積されたデータで大きく分けられます。さらに、蓄積されたデータでは蓄積状況に応じて最適な処理方式が存在します。例えば、リアルタイムのデータ処理はCEPで行い、数時間前までの時系列データ処理はインメモリデータベースやKVSの層で行い、数日~数ヶ月前のデータ処理はDWHアプライアンスの層で行い、それ以上時間を遡るデータ処理はHadoopで行う、といった方式選択が考えられます。
ハイブリッドモデル
上記のような背景を考慮し、NTTデータでは、レイテンシとデータ構造、量に応じたビッグデータ処理のハイブリッドモデルを提唱しています。(図)
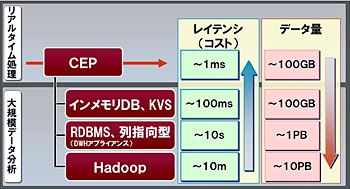
図:大規模リアルタイムデータ分析基盤モデルの概要
基盤技術ごとに扱えるデータ量、レイテンシが異なる。
情報システムで取り扱う処理の内容やデータの構造に応じて、各層のアーキテクチャを柔軟に組み合わせることで、ビッグデータ活用に最適なパフォーマンスを発揮できます。このハイブリッドモデルを軸として、事象を先読みしてサービスを提供する「プロアクティブ型BI」の高度化を狙っていきます。
- CEP:Complex Event Processing(複合イベント処理)
- KVS:Key-Value Store
参考文献
- 2011年7月14日ニュースリリース







