
統計的機械翻訳とは
従来は、翻訳に必要な文法規則や変換規則を人手で作成して、これらの規則に基づく翻訳を実現する「ルールベース翻訳」と呼ばれる方式が一般的でした。ルールに適合すれば、高い精度で翻訳が可能である反面、ルールがない場合には、うまく翻訳できない問題があります。さらに、現在では、これらの規則が非常に複雑になっており、規則間の矛盾を起こさないようにルール修正することは非常にコストと時間のかかる作業になっています。
近年、ルールは作成せずに、翻訳対象となる言語対の文を対訳データとして自動学習させることで、確率的な翻訳のモデルを構築し、統計的に翻訳を実現する統計的機械翻訳が急速に技術発展しています。対訳データさえあれば、容易にさまざまな言語に対応することができます。また、特定の対訳言語データを選択することにより、文書や業務の種類にカスタマイズした翻訳システムが構築できます。
語順の壁の克服
言語は、その語順により、SVO型言語や、SOV型言語などに分類できます。英語はSVO型で、日本語はSOV型の代表的な言語です。型が同じ欧州各国語間の翻訳では、翻訳も容易であり、以前から統計的機械翻訳の精度的な優位性が認められていました。
一方、型をまたがる言語間の翻訳(たとえば、英語から日本語への翻訳)では、語順の違いへの対応ができておらず、ルールベース翻訳が優位な状況が続いていました。
語順を入れ替える技術開発により、SVO型の英語をいったん、SOV型の日本語風の英語に変換したうえで、日本語に翻訳するステップを踏むことで、ルールベース方式を超える翻訳精度を実現できるまでに至っており、NTCIR(エンティサイル)参考などの評価型ワークショップで、その優位性が示されています。
対訳データを集める
学習用の対訳データは一般的に、数10万~数100万程度のペアが必要と言われています。また、それ以上のデータがあれば、さらなる精度向上が見込めます。ただし、一度にそれだけの量の対訳データを収集することは、非常にコストがかかります。対訳データの収集では、クラウドソーシングとして不特定多数の人が過去の翻訳の過程で作成した対訳を収集し、活用するなどの手法も検討されています。近年のビッグデータの恩恵は機械翻訳技術にも及んでいます。
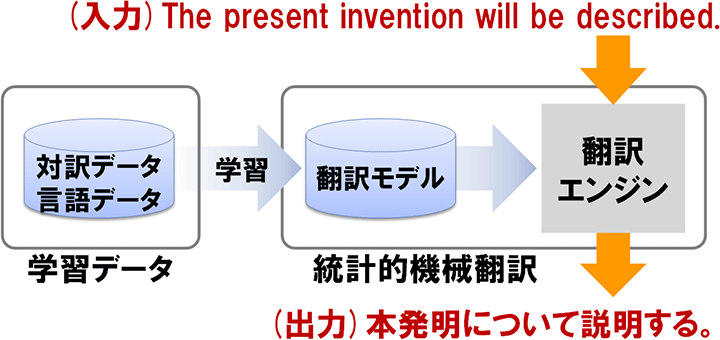
図:統計的機械翻訳の処理
参考文献
- 参考NTCIR(エンティサイル)(外部リンク)
NTCIR(NII Testbeds and Community for Information access Research)とは、機械翻訳などの情報アクセス技術の大規模な評価基盤を国内外の研究者が共有し、その共通基盤の上で研究を進め、検証、比較評価するプロジェクト。国立情報学研究所が主催。







