
- 目次
Think Big Act Small !!
この言葉を初めて聞いたのは、2005年頃にSOA(Service Oriented Architecture)を勉強していた時です。アプリケーションの再利用性を高めサービス化していく際に、ビッグバンアプローチではなく、小規模の導入を行い、サービスをつなげることで成功体験を得て、最終的には業務プロセス全体に適用していこうとするものです。昨今は、マイクロサービスアーキテクチャという形で、その思想は受け継がれています。現在ではデータ活用プラットフォームの構築において、まさに「Think Big Act Small」と似た方針を掲げ、小さな成功体験を重ねつつ大量のデータや多くのユーザがデータ活用を行うことができるものを作ることを目指すプロジェクトが非常に増えています。
Data&Intelligence領域における新語・流行語
データ活用を進めるにあたり、AIやそのツールのみでの実現を期待してしまうかもしれませんが、プラットフォームやデータ整備がなければ、データの活用は期待しているような進み方をしません。プラットフォームやデータ整備を行ってきた先駆者の多くも、小さく始めて大きくすることに成功しており、その先駆者からのフィードバックなどから新しい流行がうまれつつあります。そこで、昨年あたりから取り上げられるようになった新語を振り返りつつ、Data&Intelligence領域において、2023年さらに流行語になると考えられる用語を3つあげてみました。
- モダンデータスタック(Modern Data Stack)
- データファブリック(Data Fabric)
- データメッシュ(Data Mesh)
このような用語が流行すると考える背景として、データ活用領域とクラウドサービスは親和性が高く、積極的にクラウドサービスを利用するプロジェクトが増えていることがあります。データ活用領域におけるクラウドサービスの利用は、まさに小さく始めて大きくしていくことが比較的容易な領域です。クラウドサービス上でのデータ分析プラットフォームは急速に増えていますが、残念ながら
- 採用したソリューション自体に、実は拡張性があまりなかった(スケールアップ可能だが現実的でない)
- ライセンスが不足していて、新規サーバが容易に構築できないため求めていたアジリティが出ない
- 大量のデータを一元的に管理・運用することが非常に大変な状況となっている
- 管理するサーバが多くて、障害やバージョンアップなどを含めた運用負荷が高い
というようなことも発生しています。
このような課題が海外の先進的な事例では数多く発生しており、それを解決する手段や考え方、さらには組織体制や文化として、上記のような流行が生まれました。
モダンデータスタック(Modern Data Stack)
モダンデータスタックとは、ELTデータパイプライン、データウェハウスやデータレイクさらにはビジネスインテリジェンスといったクラウドサービスベースのデータ分析プラットフォームで使用されるツール群のことです。この言葉を最初に発信したのは、ELTソリューションを提供しているFivetran社だと言われています(※1)。そのブログの中で、モダンデータスタックと従来のデータスタックとの最大の違いは、モダンデータスタックにおけるデータはクラウドでホストされ、ユーザによる技術的な設定がほとんど必要ないことで、メリットは時間、コスト、労力を節約できるとことだと記載されています。データアナリスト、データサイエンティスト、データエンジニアがより価値の高い分析やデータサイエンス・プロジェクトに専念することを目指すものであり、我々も常に最前線で同じことを感じ、同じことを目標としているため、非常にわかりやすいコンセプトだと感じました。
こうした潮流に乗って、グローバルで実績を作ったいくつかのソリューションも日本進出を果たしてきています。上記のFivetran社も、2022年11月にデータプロセスセンターをGCP Tokyoリージョンに開設したことを発表しました(※2)。おそらく、2023年もこの流れは続き、いくつかのソリューションが日本上陸を果たすのではないでしょうか。
忘れていけないのは、こうした潮流を作ったのはクラウド技術(仮想化やオブジェクトストレージ)、AWSのRedShiftや、GoogleのBigQueryといったクラウド型DWHのサービス提供、そのあとに続いたSnowflakeやDataBricksといったAWS/Azure/GCPで動作する新しいソリューションであり、それらがデータストアの領域の世界を進化させたということです。このテクノロジの進化が、周囲のデータ収集レイヤや、BIやAI/ML領域に広がり、今後データマネジメント領域で、それほど重要でなかった機能が改めて見直されて、データオブザーバビリティのような新しいソリューションが出てくることも想像されます。更に、データストアのレイヤを取り囲むように、技術革新や新たなソリューションが今後も次々と出てくることが期待できる非常に面白い領域だと感じています。
新しいソリューションは使ってみないとわからないところも多いため、Act Smallしやすい技術スタックがまさに今求められて、モダンデータスタックはそういった技術スタックで構成されています。
~ 次世代のデータコミュニティ ~
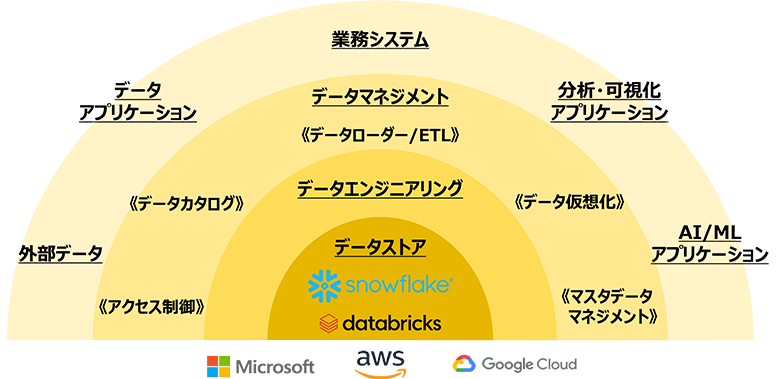
データファブリック(Data Fabric)
データファブリックとは、異なるデータソース間でデータの統合や共有を可能にする新たなデータ管理設計です。Gartnerが「2022年に注目すべきデータ分析に関する12のトレンド(※3)」でも紹介した通り、メタデータを傾聴し、学習し、動作し、人やシステムに対してフラグを立て、アクションを推奨することで、最終的には組織内のデータの信頼性向上と利用の効率化を実現させ、設計、展開、運用などさまざまなデータ管理作業を削減することを目標としています。また、「データファブリックは、複数のプラットフォームやビジネス・ユーザーをまたぐ形で存在するデータを統合し、高い柔軟性とレジリエンスを持たせたもの」と言っている通り、柔軟で再利用可能な拡張されたデータ管理を達成するための新しいデータ管理デザインです。
あらゆるユーザがあらゆるデータを簡単かつタイムリーに組合せ、あらゆるビジネスで利活用可能にする理想的な状態を目指しており、Think Bigという観点においては1つの大きな方向性となます。
その一歩目として、データカタログ、プリパレーションツール、データ仮想化技術を採用することがよく検討され、何から導入するとよいかと聞かれることもあります。それぞれを誰に・何のために優先的に導入し、導入後の世界は本当にデータ管理作業を削減できるのか?目的を達成するのか?価値があるのか?とお客様と議論すると同時に、背後にあるアーキテクチャが、モダンデータスタックで語られているような、クラウドネイティブなアーキテクチャであるのかなどを適時確認しながら導入検討を実施しています。
さらに、データファブリックの目指す最終的なアーキテクチャは、メタデータを自動収集・充足させ、AI技術を利用して、データ管理に対する知見とレコメンドを得て、データ管理を自動化するような世界を目指しています。上記のようなツール導入後もデータファブリックが目指す世界になかなかは到達できていないのが現状であるため、これからの技術やテクノロジの進化、新しいソリューションや既存のソリューションのさらなる進化にも期待しています。
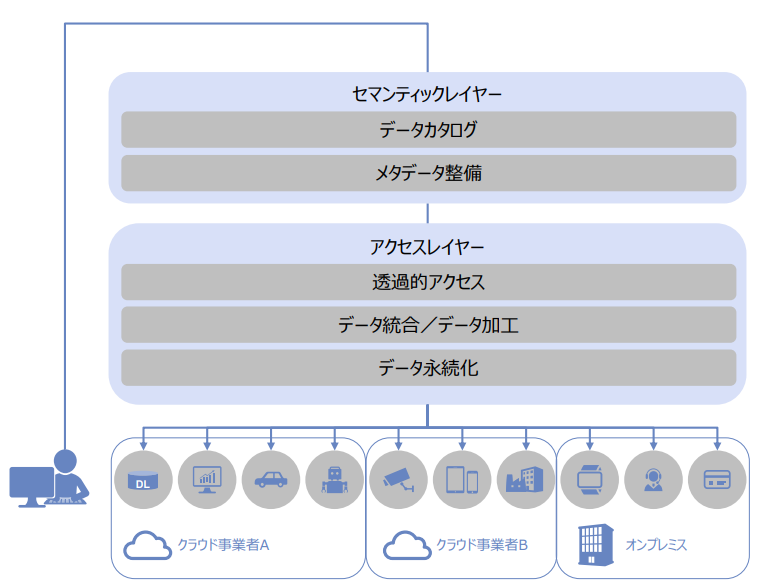
データメッシュ(Data Mesh)
データメッシュとは、非中央集権型のアーキテクチャです。データメッシュに関しては、2022年11月2日公開の「非中央集権型データマネジメント データメッシュとは(※4)」という記事をご参照ください。そちらでは、文化や組織や体制を含めた中央集権的とも言えるアーキテクチャが、逆にアジリティやビジネス的な価値を十分発揮できなくなっていることへの1つの対処方法を示しています。
3つのトレンドの共通点
最近、海外でのカンファレンスなどで様々な公開事例を見る中でも、モダンデータスタック、データファブリック、データメッシュの3つのキーワードはたびたび見かけるようになっています。具体的な製品ではなく概念であることもあり、実現レベルや内容には差があるものの、大きなトレンドにはなっているようです。
クラウドサービスの利用に伴い、この数年で1人当たりが管理しなければいけないサーバの台数が、数十倍~数百倍になっています。データマネジメント界隈でも同じことが今まさに起きています。クラウドサービス上でデータ活用プラットフォームを構築してデータ活用を急速に進めているプロジェクトでは、1人当たりで管理するデータ量は、数年前の数百倍、もしかすると数千倍になっています。
そういった現場にいるすべての人がもっとデータ管理において楽をしたいと思っています。むしろ、楽をしないととてもではないですが運用が回らず、ビジネスに迷惑をかけてしまうという状況です。運用が回らないとデータ活用側にも歯止めがかかり、全体としてブレーキがかかっていきます。そうならないために、様々な技術・テクノロジでデータマネジメントを多方面から支援できる世界が、今後ますます求められます。データマネジメント・データ・プラットフォーム、さらにはその上のデータアプリケーションを含めたデータドリブン経営を支えるプラットフォーム全体において、将来ボトルネックになるものは何なのか、組織・体制・データ・システムなどの各種アーキテクチャを考えながら、これからのデータ活用を支えていくのが、NTTデータの役目の1つだと考えています。
忘れてはいけない、最終的な価値提供
データ活用プラットフォーム導入の意義は感じていても、定量的な具体的なメリットやROIに関する説明ができず検討が進まなかったり、当初想定通りにいかずにプロジェクトの見直しを検討されたりということが最近増えてきているように感じます。
経験と勘に頼った業務運用から、データを中心とした業務への変革のためには、効果をしっかり出すことは非常に重要です。まずは定量的・定性的な効果が高い業務での適用を検討して、将来を見据えた必要最低限のプラットフォームで一定の効果を出すのが良いでしょう。そこから徐々に必要な機能を追加しながら、出来るだけ運用負荷が上がらない工夫をしておき、プラットフォーム側が利用者(データ活用者)に価値を提供していくことが、最終的なユーザ価値提供につながります。短期目線でコスト・構築容易性・目先の楽さを重視しすぎると、将来運用が大変になったりコストが想定以上になるなど、データ活用の広がりを阻害する要因となる可能性もあります。クラウドらしい(使った分だけしか課金されない、など)ソリューションの選択は、非常に良い選択に違いありません。また、移行やバージョンアップ等、価値を生みづらい作業はできるだけ避けたいので、従来よりもさらにたくさんの観点でソリューションを選択することが必要となっています。
冒頭、少しだけSOAの話に触れましたが、当時「SOA導入を目的とせず、課題が何かを考え、その課題を解決する方法の1つがSOAであれば導入することを検討すべき」と、常に発信していました。今回ご紹介した3つの考え方も、それを導入すればゴールという定義がない曖昧な概念です。SOA同様、導入を目的にするのではなく、解決すべき課題や最終的な価値や狙いを定め、運用しやすいデータ活用環境を使ってビジネス価値を出していくべきだと思っています。
これからデータ活用は、さらにミッションクリティカルな領域の業務となってきます。そのため、新たな課題が生まれたり、より高いSLAが求められるようになったりします。多種多様な課題を一つずつ解決しながらデータ分析プラットフォームやそれを利用する組織・さらにはデータ活用文化を作っていくことができれば、アジリティを具備した利用者満足度が高いデータの民主化が達成され、これからの時代のデータ活用において大きな成功を掴むことができるのではないでしょうか。
