
現在のテスト自動化プロセス
JUnit参考1のような標準的なテストスクリプトや、Jenkins参考2等のCIサーバーの普及により、近年ではモジュール単体のテストでは、テストを手動で実行させることは少なく、JUnitなどのスクリプトで自動実行することが標準的となりつつあります。CIサーバーを導入して回帰試験の自動化を行うようなシステム開発であれば、以下のようなプロセスでテストが実施されます。
- 1.テスト項目の作成
- 2.テストデータの作成
- 3.テストスクリプトの作成(JUnitコーディング)
- 4.スクリプトの実行
- 注eclipse-plugin/CIサーバー
(3)の中でテスト実行と結果確認は一緒に行われる
このように、JUnitのようなテストスクリプトとJenkinsのようなCIサーバーで回帰テストの自動化ツールを用いることで、テスト工程を自動化、高速化する事が標準的になってきてはいるものの、テスト項目を考えたり、テスト対象モジュールを駆動させるためのインプット情報であるテストデータを考えたり、それらを自動化するためのテストスクリプトをコーディングする作業は、変わらず手作業で行われているのが現状です。
従来のテスト技法とテスト自動化ツール
テストの作業を効率化する技術には様々なものがあります。一般的に知られている手法としては、テストケースの組み合わせ抽出技法の「直交表」「All-pair法」「境界値テスト」「同値分割」などがあります。また、テストケースやテストスクリプトを自動で生成するためのテスト手法として「モデルベーステスト参考3」があります。このようなテスト技法や自動化ツールを利用したとしても、現実的に実行可能なテストスクリプトの作成までを全自動で実施してくれるテスト自動化ツールはありませんでした。一方、近年Symolic Execution参考4と呼ばれる技術が注目を集めています(JPF参考5、JCUTE参考6、KLEE参考7、CREST参考8など)。
これまでのテスト技法やモデルベース技法は、単にテストを効率化するための考え方や枠組みを用意するに留まり、テストデータを作成するのは常に人間の作業でしたが、Symbolic Executionでは、どのようなテストデータを用意すれば対象のテストコードを実行可能かという問題を、具体的な計算により解決してくれます。テスト対象のコードをツール内部で抽象化し、制約充足問題(CSP)参考9を解くことにより、実行ルートの導通可能なテストデータを計算します。多くの実装ツールでは、テストデータの算出とともに、そのテストデータを含んだテスト実行可能なテストスクリプトも同時に生成します。この技術を応用すると、カバレッジテストに限定されますが、テストプロセスとして必要な(1)~(3)の作業のほぼ全てを自動化することが出来ます。しかしながら、そのようなテストの自動化を実現するには様々な問題が存在します。
Symbolic Executionの課題
Symbolic Executionの技術は研究分野では実績があるものの、実際のシステム開発の現場で広く利用されるまでには至っていません。その一つの理由として、解析性能の問題があります。テストする対象のプログラムが数値だけを扱うような単純なプログラムの場合は、テストデータを算出することは容易ですが、現実のソフトウェアプログラムは以下のような要因で非常に複雑な構成になっており、Symbolic Executionが適用できない場合が多いためです。
- i.テストデータの型は文字列、配列、Collection型、JavaBeansのような複雑で巨大な構成をしている。
- ii.IFや抽象クラスのようにプログラム自体が複雑な構造体を構成している。
- iii.DIのようにプログラム上の情報以外から、インスタンスや振る舞いを制御するプログラムが用いられることも多く、プログラム解析だけから正確なテストデータを算出できない。
- iV.大規模なソフトウェア開発では、人もベンダーも場所もモジュールも分散して開発されるため、テスト対象のモジュールは常に未完成の状態であり、テストを実行するにはモックやスタブの実装が不可欠である。そのためテスト対象コードだけではテストが実行出来ない。
近年ではDynamic Symbolic ExecutionやConcolic Execution参考10のようなアプローチも有りますが、i~iVが問題となることは共通しています。
NTTデータのSymbolic Executionを利用した単体テスト自動化ツール
NTTデータでは、テストデータが自動生成できないテスト対象の複雑性の問題を独自の手法で克服することで、100%ではないもののある程度の確率でテスト対象コードからテストデータ、テストスクリプトを完全に自動生成できる解析エンジン(GOYA参考11)を開発しました。そしてこの技術をNTTデータの単体試験自動化ツール(TERASOLUNA RACTES for UT参考12)に組み込むことで、全く新しい単体テスト自動化ツールを作成し社内に展開しはじめています。
このテスト自動化ツールは、テスト対象のソースコードに対して構造の解析を行い、自律的にテストデータの作成からJUnitのコーディングまでを全自動で行います。StringデータやJavaBeansのような構造体を持ったテスト対象でも、独自の手法で構造解析を行うことで、ある程度のカバレッジが抽出可能なJUnitコードを生成可能です。また、DIコンテナを利用した試験対象コードや外部参照をしているコードであっても解析が可能です。
テスト対象コードからテストデータを抽出しているため、完全なテストデータを作成できている訳ではないですが、導通可能なテストコードをテストデータ込みで完全に自動生成できるため、JUnitコードの生産性向上に寄与します。
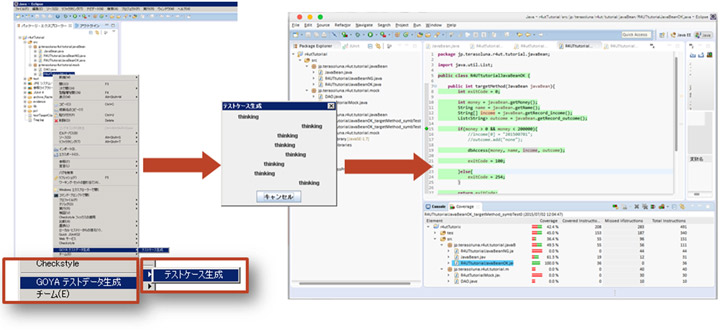
図:テスト対象コードからツールが自律的にテストデータとJUnitコードを作成可能
今後は更に解析性能を向上させるとともに、インプット情報を設計書やインターネット上のドキュメント情報にまで広げることで、カバレッジレベルの自動テストからさらに業務的な意味も含んだテストの自動化を目指しています。
参考文献
- 参考1Junit(外部リンク)
- 参考2Jenkins(外部リンク)
- 参考3Model-based testing(Wikipedia)(外部リンク)
- 参考4Symbolic execution(Wikipedia)(外部リンク)
- 参考5JPF(外部リンク)
- 参考6JCUTE(外部リンク)
- 参考7KLEE(外部リンク)
- 参考8CREST(外部リンク)
- 参考9Constraint programming(Wikipedia)(外部リンク)
- CHOCO(外部リンク)
- 参考10Concolic testing(Wikipedia)(外部リンク)
- Sen, Koushik; Darko Marinov; Gul Agha (2005). CUTE: a concolic unit testing engine for C
- 参考11複雑なデータ構造を持つコードに対してSymblicExecutionを行うNTTDATAの解析エンジンツール
- 参考12TERASOLUNA RACTES for UT(外部リンク)



