
Alluxioとは
Alluxio(旧名Tachyon)参考1はカリフォルニア大学バークレー校が新たに開発したインメモリー型のストレージシステムです。ビックデータ処理基盤の開発で世界をリードするバークレー校は他にもApache Spark参考2やApache Mesos参考3を開発したことで有名です。AlluxioはHadoopやSparkなどのデータ処理フレームワークとHDFS(Hadoop Distributed File System)参考4のような下層ストレージシステムの間でデータをキャッシュすることで処理を高速化します。コミュニティは200人以上のコントリビューターと50の企業により支えられています。百度(Baidu)が既に導入を進めており、30倍の処理性能向上につながったとの記事参考5もあります。
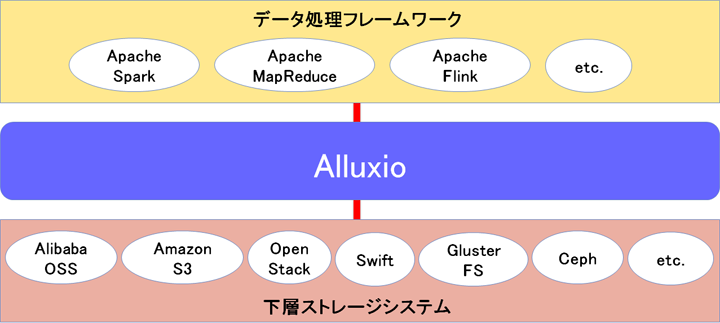
図:Alluxioのインターフェース
Alluxioのインターフェースや機能
AlluxioはSparkやMapReduceを使用可能なHadoop互換APIを保持しているため、既存システムに追加インストールするだけでシステムのパフォーマンス向上を実現できます。図に示すようにAlluxioは多数の互換APIを保持しており、他にもJava Fileクラス(java.io.File)やHadoop Compatible FSインターフェースなどのプログラムインターフェースにも対応しています。
Alluxioにはストレージを階層化する機能も実装されています。インメモリーストレージとハードディスクやSSDなどの記憶装置を階層構造にして、メモリー利用サイズや参照頻度に応じて自動的に適切な記憶装置に情報を配置することが可能です(現在は3階層まで対応)。リネージュと呼ばれる機能にも対応しており、耐障害性を犠牲にすることなく高い読み書きのスループットを確保することもできます。リネージュの基本的な考え方は、「データが無くなった場合、それを作ったジョブを再実行してデータを再構築すればよい」になります(ただし、本機能はまだアルファ版のようです)。リネージュ機能は、全自動で実行されるわけではなく、いくつかの制約があるため、使用時は注意が必要です。耐障害モードで動作させるには、設定情報の保守や分散同期化などを実現するZooKeeper参考6の導入が必要になります。
Alluxioが高速に動作するパターン
Alluxioは近年注目されているハイブリッドクラウドで効果を発揮します。データはオンプレミス環境に蓄積したいが、月に一回しか実行されないデータ処理はパブリッククラウドで実行したい、といった要件においてAlluxioは力を発揮します(Alluxioがパブリッククラウド側でデータをキャッシュすることで高速化に貢献する)。Alluxioは単に問い合わせをキャッシュするだけではく、クエリーを分析して次に使用するデータをプリフェッチ(事前読み込み)する機能も持っているようです。
SparkもAlluxioと同様にメモリーにデータをキャッシュしますが、Alluxioはデータ処理フレームワークではなくストレージ層側に位置するため、複数のデータ処理フレームワークを動かした場合でも効率よくデータをキャッシュできます。例えばSparkで前処理をして最後にHadoopで処理をするような場合、Alluxioを導入していれば、Hadoopはキャッシュの恩恵を受けて高速に動作できます。逆に一般的な日次統計処理であれば、数倍の高速化に留まるようです。処理内容によってはまったく高速化されない場合もあるでしょう。Alluxioは決して万能ではありませんが、うまく使えばシステムのパフォーマンスを大きく引き上げてくれると期待できます。
