
Deep Learning技術導入の難しさ
近年のDeep Learning技術の成功には目を見張るものがあります。しかし、通常の「教師あり学習」技術によるDeep Learningには、他の手法に比べて極めて大量の予測材料と予測対象のペアが必要になり、導入への大きな障壁になります。
例えば、眼底の画像から白内障の進行度を予測するDeep Learningモデルを作成することを考えます。このようなモデルを作成する際に必要なデータは、眼底の画像(予測材料)と対象の患者の白内障の進行度(予測対象)のペアになります。眼底の画像は専用の機器を利用すれば取得することができますが、白内障の進行度は、専門医が注意深く画像を観察し判断する必要があります。場合によっては追加検査が必要になるでしょう。
このように、特に予測対象の方の収集にコストがかかりやすく、現場のデータにはペアがそろわず予測材料のみ蓄積されているものも多々存在します。
このような予測材料のみのデータからも、学習を行うことのできる技術に「半教師あり学習」があります。
半教師あり学習とDeep Learning
半教師あり学習とは、ペアのデータに加えて、予測対象が存在しない予測材料のみのデータからも学習を行うことで、予測モデルの精度を向上させる手法の総称です。
Deep Neural Networkは、複数の層が積み重なったNeural Networkであり、各層で入力を変換し、最終的な変換結果を基に予測を行いますが、Deep Learningにおける半教師あり学習技術の多くが、予測対象の存在しないデータを用いて、各層における「よい」変換方法をうまく学習させることを目指しています。
例えばLadder Networkと呼ばれる手法は、「変換後の値から入力を再構築できるもの」を「よい」変換とする考え方を取り入れています。変換後の値から入力が再構築できるということは、入力データが持つ情報を効率的に抽出できたといえるからです。
さらに、各層で入力の値と再構築された値を比べ、それぞれ誤差が小さくなるようにパラメータを調整していけば、予測対象データが存在しなくても「よい」変換を学習することができます。
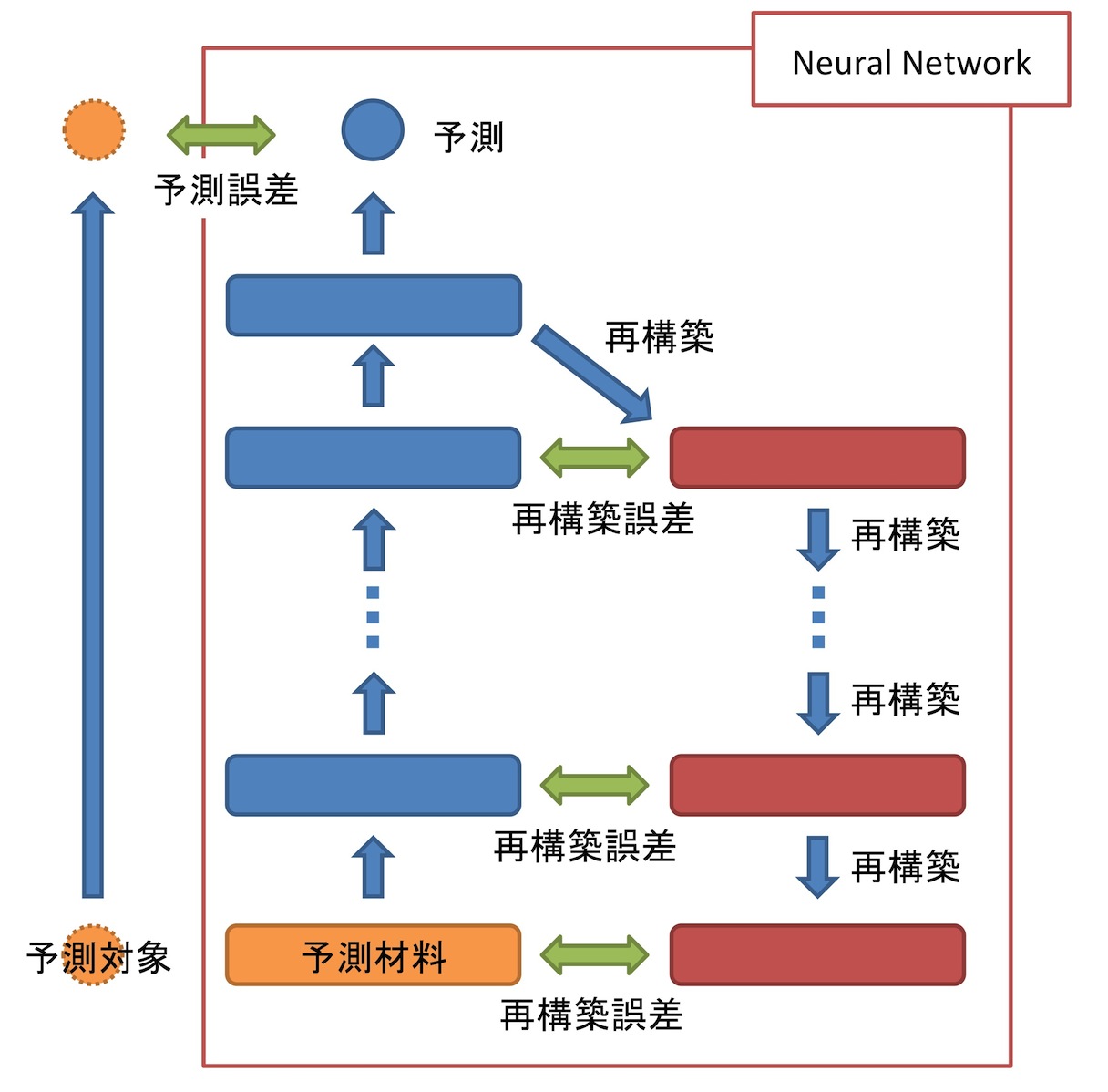
図1:予測誤差と再構築誤差を用いたDeep Learningモデルの学習
一方、予測対象が存在するデータに関しては、予測誤差も同時に小さくするようにパラメータを更新します。(図1)Neural Networkの各層で「変換後の値から入力を再構築できる」ようにするには、入力の細かな情報も抽出する必要がありますが、細かすぎる情報はこの予測誤差を小さくするにはむしろノイズになってしまいます。
しかし、いくつもの層が重なったDeepなモデルを用いることで、これらのバランスをとることができます。つまり、浅い層では細かな情報を抽出し、深い層になるにつれて予測に関連する情報のみ抽出するようにする、という役割分担を持たせることができるのです。このようにして学習させたモデルは、予測対象が存在するデータのみ使用した場合に比べて、格段に良い精度を持つことが報告されています(※1)。
Ladder NetworkのほかにもDeepなNeural Networkの構造をうまく利用したさまざまな半教師あり学習の手法が提案されています。半教師あり学習技術で学習データ整備の手間が少なくなることで、Deep Learning導入の障壁はどんどん小さくなり、Deep Leaningアプリケーションの裾野はさらに広がっていくでしょう。
- ※1 Semi-Supervised Learning with Ladder Networks
https://arxiv.org/pdf/1507.02672.pdf(外部リンク)
