
- 目次
JAバンクのシステムアーキテクチャ中長期戦略
JA、信農連、農林中金から構成され、実質的に一つの金融機関として機能するJAバンク。全国に民間最大級の店舗網を有し、国内第3位の個人貯金シェアを誇ります。その中で農林中央金庫は、JAバンクの全国機関として、全国552のJAの一体的な金融事業運営および健全性確保に向けた指導に取り組んでいます。
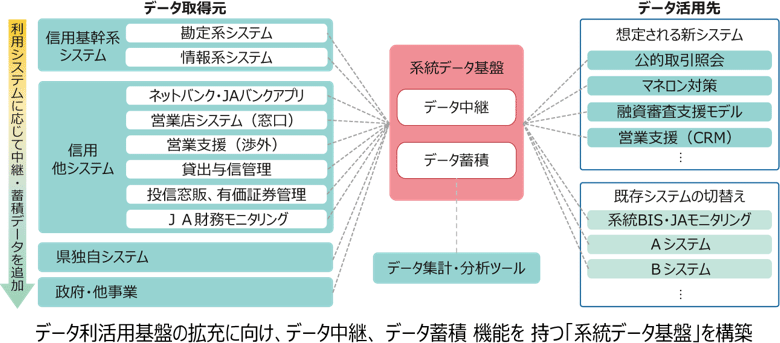
JAバンクのシステムアーキテクチャ中長期戦略において、データ利活用基盤の拡充は重要な取組課題の1つです。中でも、利用者のデータを管理する元帳的な機能を有する業務システム(基幹系)は、オープンシステム化やクラウド化によりコスト抑制を図ろうとしています。さらにはデータ蓄積・分析のためのデータ利活用基盤の構築により、データの連携・蓄積、二次活用ニーズに対応しやすくしました。それらにより迅速なフロントチャネルのサービス拡充を可能とする、新たなシステムアーキテクチャの構築をめざしています。
以下、農林中央金庫の柴崎氏と農中情報システムの菊池氏に、本プロジェクトの経緯から構築したシステム、そしてその効果について解説いただきました。
「系統データ基盤」導入の経緯
JAバンクの大規模データを収集、集積、加工してグループで活用する「系統データ基盤」導入の経緯について、農林中央金庫 IT統括部 IT戦略班 部長代理の柴崎光郎氏は次のように話します。「ポイントは、今後増加が予想されるデータ二次活用や蓄積・分析ニーズにいかに応えていくか。これらニーズに応えられる基盤をあらかじめ構築しておきたい。そのためにはデータを蓄積、集計、分析する機能が必要だと判断し、農中情報システムに相談を持ち掛けました。」
農林中央金庫のシステム開発を担う農中情報システムは、前述の方針をもとに、システムの全体を下図のように概念整理しました。
上流であるデータ取得元の勘定系と情報系からデータを集め、蓄積し、加工して活用先に提供していきます。この中で同社は、Snowflakeの活用方法を企画段階から検討したといいます。
農中情報システム JASTEM開発二部 データ基盤班の菊池 幸司氏は、「Snowflakeの機能を使って、データ加工と活用は当然として、運用機能、特にセキュリティについても、要件を満たせることを確認しました」と語りました。
さらに今回、同社が取り組んだのが、開発および保守への関与度合いを高めることでした。「これまで同社は、要件定義工程に大きく偏っており、設計以降の製造試験や保守の工程に対してはあまり関与できていませんでした。そのため本プロジェクトを通じて、関与割合を高めたいと考えていました」(菊池氏)
そこで同社は、特に保守についての役割を担うことを目標としました。人員も限られる中でその目標を実現するためには、保守において多くを占めるデータベースの管理負荷を、大幅に削減する必要がありました。
Snowflakeの選定理由
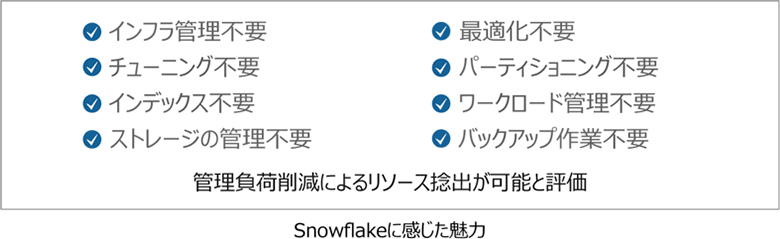
そこでSnowflakeが登場します。菊池氏はSnowflakeの選定理由を、次のように語ります。「製品の選定段階で魅力と感じたところは、インフラ管理が不要、最適化が不要、チューニングも不要といったさまざまなメリットが享受できることでした。データベース管理負荷が大幅に削減できれば、捻出したリソースで目標が実現できると考えました」
「系統データ基盤」のアーキテクチャ全体像
前述の概念を前提に、JAバンクの「系統データ基盤」アーキテクチャは、データの取得元と活用先をつなぐハブの中心にSnowflakeを据える構成を策定しました。
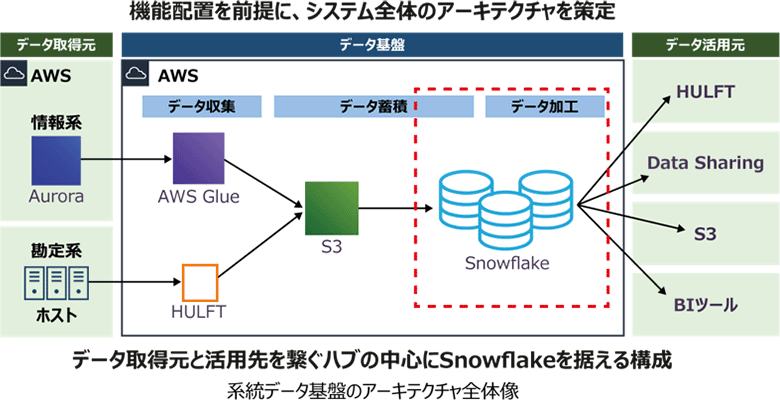
データ取得元である情報系はAurora、勘定系はホストに対し、それぞれAWS GlueとHULFTを使ってS3にデータを格納しています。S3に格納したファイルのうち、必要なテーブルを必要な期間だけ、Snowflakeにロードして活用先に提供していきます。
Snowflake導入効果
本システムでは、47都道府県分のデータをすべて同一のスキーマに格納し、共通したオブジェクトで構築しました。その上でSnowflakeの機能である行アクセスやマスキングポリシーで、データの独立が図られています。その理由は、各JAバンクの県単位ごとにデータを独立させるという、JAバンクのルールによるものです。
「従来のシステムでは、47都道府県をすべて別スキーマとしてDBを構築していました。そのため環境構築やテストは47都道府県分すべて行わないとならず、相応の負荷がかかっていました。それに対し新システムでは47都道府県分のデータをすべて同じスキーマに格納して、Snowflakeの機能でデータを分離しています。マスキングポリシーはデータ可視化範囲を調整する部分に使っていますが、これにより効率的な構成が実現しました。これまでは全国のデータを一貫して見たい場合、47個のスキーマを参照しなければなりませんでしたが、新システムでは一つ参照すれば全体のデータが見えます。利便性も大きく向上しました」(菊池氏)
稼働から約9ヶ月が経ちます。現時点での成果を、菊池氏はこう語ります。「管理負荷は大幅に削減できました。稼働からインフラ面での手当は実際何もしてない、というのが正直なところです。加えて、既存処理に影響することなくワークロードを構築でき、設計の自由度がかなり高まりました。性能面については、とにかく速い。実際使った感覚ですが、たとえば全国の取引データは相当数のレコード数字になるのですが、単純な問い合わせであれば秒単位でレスポンスが返ってきます。複数テーブルを結合する、条件をいろいろ組み込んだりしても10分かからない。ストレスを感じることなく利用可能と感じています」
ここからは、本プロジェクトでNTTデータが支援した内容を、NTTデータ第二金融事業本部JAバンク事業部の佐藤駿の講演に基づいて解説します。NTTデータは、農林中央金庫の「系統データ基盤」構築に対する全面的な支援と、農中情報システムに対する開発・保守領域拡充へのサポートを全面的に行ないました。
要件定義に有効な、羅針盤としてのリファレンスアーキテクチャ
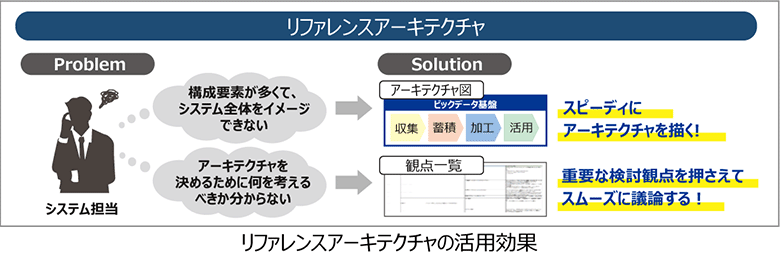
ビッグデータ活用基盤の要件定義では構成要素が多く、迷子になりがちです。そのためシステム全体がイメージできない、誰がどういうデータを使うのかなどの策定が難しい、といったことがよく起こります。
そこで有効なのが、NTTデータが提供する「リファレンスアーキテクチャ」です。具体的にはデータ蓄積基盤を4つの要素に分け、収集、蓄積、加工、活用のそれぞれに対しての確認事項が網羅的に一覧化されたものです。リファレンスアーキテクチャを活用することで、確認項目を抜け漏れなく確認、検討範囲のすり合わせおよび、実装方式を決定していくことが可能になります。
Snowflake導入における検討ポイント
続いて、Snowflake適用における検討ポイントについて解説します。
Snowflake導入における検討ポイント(1)製品比較
さまざまなDWH(データウェアハウス)との比較を実施し、性能、拡張性、運用性、柔軟性において、いずれもSnowflakeが高い水準で要件に応えられることが確認されました。
Snowflakeの主な優位点
- 性能:独自アーキテクチャで高速な分散処理が可能(デフォルトで特に設定しなくとも非常に高速)
- 拡張性:ワークロード独立で処理可能、既存の業務に影響を与えずに性能試験や新しい機能追加が可能
- 運用性:自動サスペンドでコストを無駄遣いしない、バージョンアップ時の停止がない、ダウンタイムゼロでのスケールアップ/アウトが可能
Snowflake導入における検討ポイント(2)セキュリティ要件の確認
本件は金融機関におけるプロジェクトであり、セキュリティ要件は厳しいものでしたが、Snowflakeは以下の4機能で、要件を満たしました。
- 1.PrivateLink:Snowflakeは閉域接続が可能。
- 2.IP Whitelisting:IPアドレス制限も可能。
この1.2.によって、不正アクセス防止要件を実現。加えて、 - 3.Tri-Secret Secure:Snowflakeが提供する暗号Keyは、顧客側が用意するKeyも組み合わせた暗号化を実施できる。
- 4.Query Log:監査対応として、すべての操作ログが記録可能。
その他、細かな点もすべて農林中央金庫とNTTデータのセキュリティ基準を照らし合わせ、セキュリティ要件を満たすことが確認されました。
Snowflake導入における検討ポイント(3)性能要件の確認(PoCの実施)
さらに、机上では把握し切れない性能要件については実機によるPoC(概念実証)を実施しました。収集したデータをS3がロードする処理および、それを加工する処理、BIツールが参照する処理について、性能要件を満たせるかの確認を行ないました。
結果としてはSnowflakeの高速な分散処理、ウェアハウスの分離による性能確認および試験の簡略化、さらにはマイクロパーティションによる性能担保が確認され、すべての性能要件を満たすことが確認されました。
Snowflake導入(構築・試験)時の振り返りまとめ
Snowflake導入(構築・試験)時の振り返りをまとめると、以下のようになります。

本プロジェクト総括と今後の展開
柴崎氏と菊池氏は本プロジェクトの総括および、今後の展開についてこう語ります。
「系統データ基盤はまだ運用開始から1年経っておらず、JAバンク全体の蓄積中のデータは一部のみです。今後、全国のJAバンク、さらにそれぞれ県単位で持っているデータも含めて一通り集め、そこから新たな価値を生み出せるデータ基盤として拡大していきたいです」(菊池氏)
「我々がSnowflakeを採用したときはまだ金融業界での採用事例が少なく不安もありましたが、1年弱順調に稼働しており、導入して良かったと思っています。まだ系統データ基盤はまだ十分に活用できていないのが実情です。これから新たな追加データやデータ利用ニーズも生まれ、データを活用するシステムも拡大が予想されますので、Snowflakeを徹底的に活用していきたいと考えています」(柴崎氏)

NTTデータのSnowflakeに関するサービス詳細はこちら:
https://www.nttdata.com/jp/ja/lineup/snowflake/
あわせて読みたい:
—9,200万人の会員データ活用における課題と新データ基盤—