
- 目次
1.データ活用の課題
データを利用した分析業務では、最初に分析で利用したいデータの情報をデータカタログで調べた上で、各種分析ツールを利用しながらデータ分析を行います。追加で分析に必要なデータがあれば、データエンジニアが対向システムからデータを取得した上で、必要なデータ加工を行い、データマート(※4)としてデータ分析者に提供を行います。この活動イメージを前提とした、データ活用の取り組み全体における課題は以下の通りです。個々の課題の詳細は次節にて説明します。
| 課題 | ||
| (1)データ活用観点 | (2)データ提供観点 | |
|---|---|---|
| (A)ディスカバリー | 分析に必要なデータが見つからない | - |
| (B)利便性 | ビジネスユーザーのツールの習熟度が低く、データ分析できる人が少ない | - |
| (C)アジリティ | - | ビジネス側が求めるスピード感で、データを提供できない |
| (D)品質 | - | データマート間で、同一ビジネス指標なのに数値が異なる |
(1)データ活用観点
(A)ディスカバリー:分析に必要なデータが見つからない データ分析の初期フェーズでは、データ分析に必要となるデータに関する知見が不足していることが多々あります。一般的な多くの分析者は、必要なデータに対応するテーブルやカラム名を把握していません。また、適切なデータをデータカタログから検索することが困難な場合も多く、これがデータ探索の障壁となります。このような状況では、多くの時間がデータ探索に費やされ、効果的な分析に集中しづらくなるのです。そのため、データ分析の効率を向上させるためには、必要なデータに迅速にアクセスできる体制が求められます。

図1:データ活用のカスタマージャーニーと離脱ポイント
(B)利便性:ビジネスユーザーのツールの習熟度が低く、データ分析できる人が少ない ビジネスユーザーにとって、データ分析の敷居が高いことは大きな課題です。多くのビジネスユーザーが、データ分析に必要なスキルや知識を十分に持っておらず、分析作業に対して心理的・技術的な負担を感じています。BIツール(※5)、SQL、Jupyter Notebookなどの分析ツールは、高度な機能を提供していますが、これらを効果的に活用するためには一定の習熟度が求められます。そのため、分析の敷居を下げるためには、ビジネスユーザーが自律的に、負荷の低い状態でデータ分析を行える環境の整備が求められます。

図2:ビジネスユーザーは分析ツールの習熟度が低い
(2)データ提供観点
(C)アジリティ:ビジネス側が求めるスピード感で、データを提供できない データの提供という観点では、ビジネス側が求めるスピード感でデータを提供することが難しいという課題があげられます。ひとつのデータマートの開発に設計・実装・テストと数週間を要することもあり、ビジネスおよびデータ活用側が求めているスピード感に合わないケースが多く見られます。データ提供のスピードを改善するためには、開発手法の見直しや自動化ツールの導入の検討が求められます。

図3:データマート開発から提供までの流れ
(D)品質:データマート間で、同一ビジネス指標なのに数値が異なる データエンジニアによるデータマートの提供スピードがデータ活用者の需要に追い付けない場合、データ活用者が自分たちで管理するBIツールなどの中で独自のデータマートを作ってしまうケースがあります。特に大規模な組織の場合は、データ活用者の部署が複数存在するため、KPIなどのビジネス指標をそれぞれ独自のロジックで算出してしまい、部署間で指標の数字がずれてしまうという課題が発生するのです。

図4:データマートの数値品質課題
大量のテキストデータで学習し、自然言語の生成や理解を行う高度なAIモデル
自然言語で書かれた質問や指示文をSQLクエリに自動変換する技術
データとデータ利用者の間に位置し、データの意味やビジネスロジックを抽象化してデータの利活用を促進する中間層
特定のビジネス部門やプロジェクトにおいて、用途、目的に応じて整形されたテーブルまたはビュー
データを分析・可視化し、ビジネスに活用するためのツール
2.課題ごとの解決方法
前章の課題に対する解決方法の概要は以下の通りです。詳細は次節にてご説明します。
| 課題 | 解決方法 | ||
|---|---|---|---|
| (1) データ活用観点 |
(2) データ提供観点 |
||
| (A)ディスカバリー | 分析で必要なデータが見つからない | - | LLMによるセマンティック検索(※6)を利用することで、テーブルやカラム名に依存せず、意図に基づいてデータ探索を実現 |
| (B)利便性 | ビジネスユーザーのツールの習熟度が低く、データ分析できる人が少ない | - | ツールに依存しない口語を用いた分析により、全てのビジネスユーザーによるデータ分析を実現(Text2SQL) |
| (C)アジリティ | - | ビジネス側が求めるスピード感で、データを提供できない | データマート開発に生成AIを利用することで、生産性を向上させ、ビジネス側が求めるスピード感でのデータ提供を実現 |
| (D)品質 | - | データマート間で、同一ビジネス指標なのに数値が異なる | データ活用において、セマンティックレイヤーを経由してビジネス指標を使用することで、データの統一性を確保 |

図5:各解決方法の全体概要
(1)データ活用観点
(A)ディスカバリー:LLMによるセマンティック検索の実現 LLMを用いたセマンティック検索により、テーブルやカラム名に依存せずにデータを発見できるようになります。従来は、データの専門知識がないと必要なデータを見つけるのが困難でした。しかし、セマンティック検索を使用することで、自然言語を用いて直感的にデータにアクセスできます。例えば、「2024年の売上データを格納しているテーブル」や「顧客の購入履歴のテーブル」という自然言語の問い合わせに対しても、適切なデータセットを迅速に見つけられます。この結果、探索時間が大幅に短縮されます。LLMを利用したセマンティック検索は、迅速かつ効果的なデータ探索を実現し、データ分析の効率を大幅に向上させます。

図6:セマンティック検索を使ったデータディスカバリー
(B)利便性:LLM×口語による分析SQLの自動生成 SQLやBIツールの習熟度が低いユーザーでも、自然言語からSQLを自動生成することで、データ分析を行えるようになります。また、事前に主キーや外部キーなどのテーブル間の参照関係や、ドメイン知識などのメタデータを定義することで、SQLの生成精度を高めることができるのもポイントです。例えば、ユーザーが複数のテーブルを結合するようなクエリを要求した場合でも、事前に定義したメタデータに基づいて正確なSQLクエリが生成されます。この仕組みにより、データに不慣れなビジネスユーザーも容易にデータ分析に取り組むことができ、組織全体のデータ活用が促進されます。
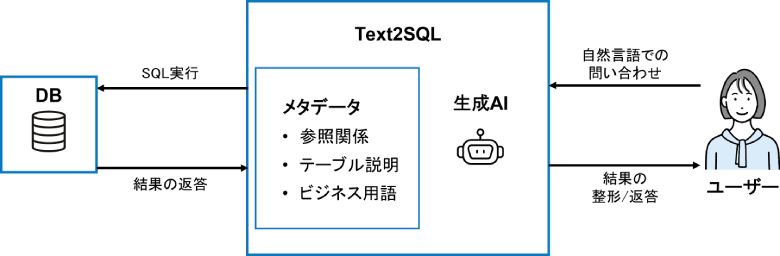
図7:Text2SQLによる自然言語を使ったアドホック分析
(2)データ提供観点
(C)アジリティ:生成AIをデータマート開発で利用することで生産性向上 生成AIの利用によってデータマート開発の生産性が向上します。具体的には企業固有のドメイン情報を生成AIに取り込み、データカタログからRAG(※7)を作成します。これにより、迅速かつ正確なデータ提供が可能になります。例えば、製造フェーズでは、生成AIが詳細設計書とRAGを用いて必要なデータを特定し、その情報からSQLコードを自動生成します。テストフェーズでは、同様の方法で試験データの作成とテストコードの生成を行います。生成時には、カラムのサンプル値やテストコードの生成例をFew-Shot(※8)を用いて提供することで精度を高めます。このように、生成AIの活用によりデータ提供のスピードと正確性が向上し、ビジネスの要求に迅速に対応できる体制を整えることが可能となります。

図8:生成AI×設計書×Text2SQLによる、コードの自動生成
(D)品質:セマンティックレイヤーによるビジネス指標定義の一元化 ビジネス指標をセマンティックレイヤーで一元管理することで、ビジネス指標のずれを防ぎます。特に、意思決定で利用されるBIレポートの算出元となるデータマートを対象に、集計指標の定義を一元管理します。また、メジャー(※9)とディメンション(※10)を選ぶような形で分析が行えるため、データ活用側は複雑な結合や集計仕様を理解する必要がなくなります。例えば、セールスとマーケティングの部門が使用するデータマートで、一貫した売上の集計指標を使用することで、両部門が同じデータに基づいて意思決定を行えるようになります。さらに、セマンティックレイヤーの情報をLLMに渡すことで、SQL自動生成の精度も高められます。このようにビジネス指標の統一性を保ち、全社的なデータの一貫性と信頼性を確保するために、セマンティックレイヤーは非常に有効なのです。

図9:セマンティックレイヤーによる、ビジネス指標の一元管理
単語の意味や文脈を理解して、より関連性の高い検索結果を提供する検索方法
外部データベースや知識ベースから情報を取得し、その情報をもとにテキスト生成を行うAI活用の手法
少量の事例をプロンプト内に提示して、AIが新しいタスクに対応できるように学習させる方法
売上や利益などの分析対象となる数値データ
顧客、製品、地域などの数値データを分類・分析する属性
3.生成AI導入に向けた準備
(1)導入に向けた課題
生成AIに渡すテーブルごとの企業固有のドメイン情報は、データ分析基盤のデータマネジメント運用で管理・蓄積しているメタデータ情報が該当します。現状DMBOK(※11)で定義されている3種類のメタデータのうち、テクニカルメタデータ(例:DDL)やオペレーショナルメタデータ(例:リネージ)は、データ分析基盤で採用されている製品側で自動的に管理・取得していますが、ビジネスメタデータに関しては十分に整備できている企業は多くはありません。この理由としては、メタデータ整備に関するステークホルダー間のインセンティブや動機づけが十分でないことがあげられます。そのため、整備が十分に進んでいないケースが多い状況です。

図10:メタデータ整備の課題
(2)対応方針と生成AI時代のデータマネジメント運用
前章の通り、データ提供者もデータ活用者も生成AIによってメタデータの価値を最大限に引き出し、自身の業務に役立てることができます。したがって生成AI時代のデータマネジメントでは、この強いインセンティブを中心に据えて、生成AIに利用させやすい形でメタデータを整備することが重要になると考えられます。従来のメタデータ拡充の取り組みは、中々定量的な評価が難しい側面がありましたが、メタデータ拡充による生成AIの回答精度の向上を指標とすることで、現場のデータ提供者・データ活用者の業務に直結するインセンティブを定量的に測定・向上させる仕組みを構築できます。

図11:生成AI前提でのメタデータ運用
データマネジメントに関する知識を体系立ててまとめた書籍。DMBOKでは、メタデータの種類としてビジネスメタデータ、テクニカルメタデータ、オペレーションメタデータの3種類が定義されている。
4.具体的な製品事例
主要なCloud Native DWH(※12)製品とモダンデータスタック(※13)製品を対象に、LLMおよびText2SQLに関する機能を以下に示します。製品や機能ごとに、メタデータの管理方法や特徴が異なります。加えて、公開されていませんが、各製品に実装されているAIエージェントの構造も異なるため、これらの要素が組み合わさって、ユーザーの利便性向上やSQL生成の精度向上に寄与しています。

図12:生成AI×Text2SQL製品事例
(1)Databricks
(A)Databricks Assistant Databricks Assistant(※14)は、自然言語で問い合わせ可能なAIアシスタントで、コードやクエリの生成、デバッグ、最適化、説明をサポートします。具体的には、SQLやPythonコードに関する質問や指示文に対して、Unity Catalogのメタデータをもとに最適なクエリの生成や説明を提供し、エラーの自動修正やインラインコードの提案を行います。また、ダッシュボードからDatabricks Assistantを使用してデータの分析・視覚化、フィルタリングを行うことも可能です。
(B)AI/BI Genie AI/BI Genie(※15)は、ビジネスユーザーが自然言語を使用してセルフサービスのデータ分析や可視化を行うためのチャットボット機能を備えています。具体的には、ビジネスドメインの質問や指示文に対して、Unity Catalogのメタデータをもとに分析クエリに変換し、表や図を用いて視覚的に回答します。また、AI/BI Genieはデータの変更や新たな質問に応じて、メタデータを継続的に更新します。間違った回答に対するチューニングも可能であるため、より正確な分析情報をユーザーに提供できます。
(2)Snowflake
(C)Snowflake Copilot Snowflake Copilot(※16)は、自然言語で問い合わせ可能なAIアシスタントであり、SQLクエリの生成および最適化をサポートします。Snowflake Copilotは、SQLクエリに関する質問や指示文に対して、テーブルスキーマ情報をもとにテーブル間の関係を理解し、SQLクエリの生成や最適化、問題点の修正を行います。また、Snowflakeの機能に関する質問でも、Snowflakeのドキュメントをもとに回答が可能です。
(D)Cortex Analyst Cortex Analyst(※17)は、ビジネスユーザーが自然言語で質問し、高精度かつ信頼度の高い回答を得られるデータ分析用途のチャットボット機能です。具体的には、セマンティックモデル(※18)で事前定義したメジャーやディメンション情報をもとに、ビジネスドメインの質問や指示文を高精度なSQLクエリに変換し、信頼性の高い回答を提供します。また、REST APIを通じて、既存のビジネスツールとシームレスに統合でき、データはSnowflakeのセキュリティとガバナンス枠内で安全に処理されます。
(3)dbt
(E)Ask dbt Ask dbt(※19)は、セマンティックレイヤー機能とLLMを組み合わせ、自然言語でデータの問い合わせが可能なチャットボット機能です。dbtセマンティックレイヤーでは、テーブルからセマンティックモデルおよびビジネス指標であるメトリクスを定義できます。Ask dbtは、自然言語での質問や指示文に基づいて、dbtセマンティックレイヤーにて定義されたメトリクスやディメンションを選択および実行して、結果をアウトプットします。これにより、複雑なメトリクスの取得に対しても、一元管理されたメトリクスを使用して、高い精度の返答を実現します。
クラウド環境に最適化され、スケーラブルかつ柔軟にデータを管理できるデータウェアハウス
データの収集、加工、分析などの各機能に特化したクラウドサービスやSaaSを組み合わせて構築する考え方、またはその基盤
https://docs.databricks.com/ja/notebooks/databricks-assistant-faq.html
https://docs.snowflake.com/en/user-guide/snowflake-cortex/cortex-analyst
セマンティック検索において、データの意味や関係を提供するためのメタデータ
5.最後に
本記事では、データ活用における一般的な課題を提示した上で、LLM、Text2SQLおよびセマンティックレイヤーを用いた解決方法について紹介しました。データ活用を組織全体に拡大させていくためには、カスタマージャーニーの中で、活用の障壁となる課題を取り除く必要があります。その手法の概要については、本記事をご参考ください。NTTデータは、生成AIをお客さまのビジネスに適用し、お客さまのビジネス拡大に寄与できるよう、各種アセットの開発を進めています。本記事でご紹介したデータ活用に関するお困りやご相談がありましたら、いつでもご連絡、お問い合わせください。
