
1.生成AIモデルを使い分ける必要性
ChatGPTの登場から1年以上が経過し、企業や研究機関から様々な生成AIモデルが発表され、テキスト生成だけに絞ってもいまや50,000以上のモデルが存在しています(※1)。表に代表的なモデルを示します。
表:代表的な生成AIモデル
| モデルシリーズ名 | 開発元 | 実行環境パターン |
|---|---|---|
| GPT | OpenAI | サービス利用型(OpenAI, Azure OpenAI Service) |
| Claude | Anthropic | サービス利用型(Anthropic, Amazon Bedrock) |
| Command | Cohere | サービス利用型(Cohere, Amazon Bedrock) ローカル型(※2) |
| Gemini | サービス利用型(Vertex AI(Google Cloud)) | |
| Llama | Meta | サービス利用型(Azure, AWS, Google Cloud) ローカル型(OSSで公開) |
- ※サービス利用型:他社環境にデプロイされた生成AIモデルをWebAPIを介して使うパターン
- ※ローカル型:自社環境にデプロイした生成AIモデルを利用するパターン
生成AIはプロンプトと呼ばれるユーザーからの指示によって、テキスト分類や機械翻訳、要約、発話生成など様々なタスクを実行できます。汎用的にも思える生成AIですが、モデルによって生成文章の品質や生成の速度、生成にかかるコスト、モデルの利用可能な環境が異なるため、ユースケースによって使い分けが求められます。
次のような例を考えてみましょう。
金融機関のセキュリティポリシーにより、外部環境へデータ送信が行えないケース
- インターネットを介した生成AIの利用ができないため、機関内のサーバーに生成AIモデルをデプロイするローカル型を検討する。
既存システムとの連携の都合上、特定のクラウド環境でシステムを完結したいケース
- 各種クラウドベンダが自社内環境で利用できる生成AIサービスを公開しており、それらの利用を検討する。
多くのユーザーが高頻度で生成AIを利用するケース
- 金銭コストが大きくなることが想定されるため、生成単価が低いモデルや、処理容量の予約が可能なモデルの利用を検討する。
2.生成AIモデルの選び方
生成AIモデルの選び方の観点と流れを図1にまとめました。ここでポイントとなるのは、あるユースケースに対して、満たさなければいけないフィルターとなる観点と、他の観点とのバランスを考慮して検討する観点があることです。最初の観点でモデルを絞り込み、その後に残った代表的なモデルをユースケースに即して検証します。

図1:生成AIモデルを使い分ける観点とフロー
モデルが対応するタスク
生成AIモデルは、モデルごとに扱える入出力のデータ種別とタスクが決まっています。自然言語タスクにはテキスト生成モデルが、画像生成タスクには画像生成モデルが適しています。さらに自然言語タスクの中でも、分類、要約、質問応答など多くのタスクがあり、モデルによっては扱えないタスクがあるため、モデル仕様を確認しましょう。
テキストを入力するモデルの場合、入力可能なプロンプトの長さもモデルごとに異なるため、比較観点のひとつになります。長文を一度に扱いたい場合、例えばAnthropic Claudeシリーズが有力な候補になります(最新のClaude 2.1は20万トークンを入力可能)。
モデルが対応する言語
日本で利用する場合には、日本語への対応も見逃せないポイントです。海外発のモデルは日本語に対応していない場合や、日本語での性能が他言語に比べて低い場合があります。また、翻訳タスクの場合には、翻訳元と翻訳先の2つの言語を確認します。各モデルの説明から対応言語を確認し、タスクにあったモデルを選びましょう。
実行環境とセキュリティ
生成AIの利用パターンには、他社の生成AIサービスを利用するサービス利用型と、独自の環境にデプロイするローカル型の2つがあります。生成AIは多量な計算資源を必要とするため、GPT等の高性能のモデルはサービス利用型となっています。反対に、ローカル型は比較的軽量なモデルが多い傾向にあります。
図2に、実行環境を起点にしてどちらのパターンのモデルを利用するかのフローをまとめました。
外部環境へのアクセスが可能な場合は選択肢が最も多く、任意のサービス利用型モデル(図2の(1))や、ローカル型モデル(同(2))から選べます。
次に、セキュリティ要件等から外部環境へのインターネットアクセスができない場合です。システムがオンプレミスにある場合は、ローカル型モデル(同(3))のみが選択肢となります。例えば表の中では、CommandやLlamaが候補になります。
また、システムがクラウド上にある場合、クラウドと同一の事業者が提供するサービス利用型モデル(同(4))かクラウド環境内のサーバーに独自にデプロイするローカル型モデル(同(5))から選びます。(4)は、例えばAWS環境で完結させたい場合を考えると、AWS Bedrockから利用できるモデルを意味します。このときセキュリティ面だけでなく、AWSのエコシステムの恩恵を享受できることもメリットになります。AWSだけでなく、Microsoft Azure, Google Cloudでも同様です。
このように、実行環境に合わせてモデルを選択することがポイントです。反対に、モデルの実行環境が自由に選べる場合は、モデルに合わせて実行環境を後から決める場合もあるでしょう。
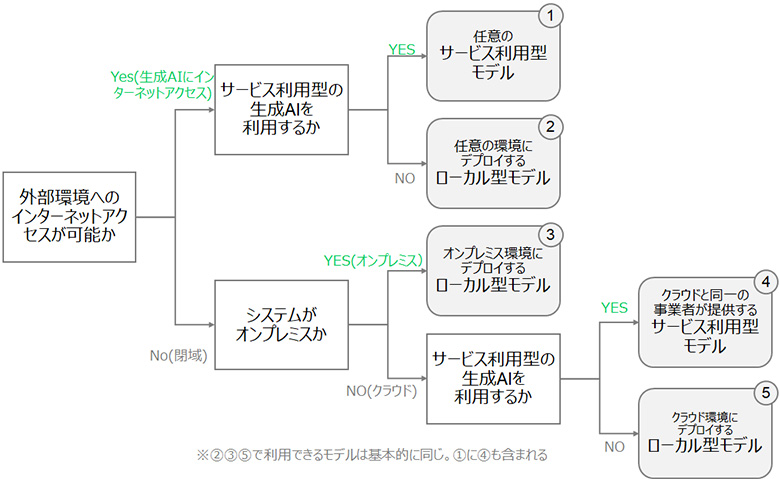
図2:生成AIモデルの実行環境ごとの選択肢
著作権侵害リスク
生成AIは大量のデータを学習することで知識を獲得していますが、モデルによっては利用する学習データの著作権侵害の可能性も指摘されています。モデル利用者は利用するモデルの学習方法や利用規約、訴訟状況当の情報を集め、権利侵害リスクを評価しましょう。
情報漏洩リスク
サービス利用型の場合、ユーザーが入力したプロンプトが生成AIの学習に再利用される場合や、プロンプトをサービス提供者が閲覧する場合があります。特に個人情報や機密情報を扱うユースケースでは、再学習されたモデルがそれらを出力してしまうリスクがあるため、利用するサービスに再学習されない設定ができるか確認しましょう(※3)。より詳しくは別の記事でも解説していますので、ぜひご参照ください(※4)。
商用ライセンス
特にオープンソースとして公開されているモデルについて、商用利用が制限されているモデルがあります。ライセンス条項を確認し、商用利用可能なモデル選びが不可欠です。サービス利用型の場合、料金プランによってライセンスが変わる場合もあるため、商用利用可能なプランを選びましょう。
モデルの性能
ユーザーはプロンプトによって複数のタスクを生成AIに指示できますが、モデルごとに得意なタスクがあるため、導入したい業務に合わせたモデル選択によって性能の向上が見込めます。
例えば、日本語での自然言語処理タスクについて比較を行い、タスクとデータによって性能の良いモデルが異なることが示しているリーダーボードが公開されています(※5)。公開情報をもとにモデルの候補を絞り込み、実際に使用するデータとタスクで検証を進めることが、性能面で最適なモデル選択のアプローチになるでしょう。
モデルのカスタマイズ性
生成AIは大量のデータから一般的な知識を獲得していますが、専門性の高い文書や各企業特有の表現などは学習していないため、業務利用時に期待した応答が得られないケースがあります。このようなケースでは、生成AIに追加で学習させることが一つの解決手段になります。サービス利用型の場合、学習機能が提供されていないものもあるため、学習機能有無もモデル選びの観点とするとよいでしょう。
なお、モデルに知識を与えるアプローチは追加学習以外に、Retrieval-Augmented Generation(RAG)等もあり、必ずしも追加学習が必要とは限りません。
応答速度
生成AIは、モデルのサイズを大きくすることで高い性能を獲得することが基本的な考え方です。一方で、モデルサイズが大きくなると、計算時間が多くかかる傾向にあります。また、サービス利用型のモデルの場合、通信にかかる時間やサービス側のサーバー負荷もレスポンスタイムに影響を及ぼします。このため、応答速度の要件が厳しいシステムでは、軽量モデルやローカル型モデルを選択するなど、性能と応答速度の双方の要件を満たすモデルを検討すると良いでしょう。
コスト
応答速度と同様に、サイズが大きく性能が良いモデルほど、その利用コストが高くなる傾向にあります。必要十分な性能や許容できるコストを見極め、性能とコストの双方の要件を満たすモデルを検討すると良いでしょう。場合によっては、軽量なモデルと大規模なモデルを併用し、簡単なタスクは軽量モデルを使うようにルーティングするようなアーキテクチャーの検討も考えられます。
開発生産性
ユースケースごとにモデルを選ぶことは大事な一方で、開発者の立場では同じモデルを繰り返し利用することでモデルの扱いに習熟し、生産性向上に結び付きます。生産性が上がればその分だけコストと納期が抑えられます。慣れたモデルでなく別のモデルを利用する場合は、ドキュメントや実装例が豊富なモデルを選ぶことで生産性の低減を少なくできるでしょう。
ここまでに解説した、生成AIモデルを使い分ける観点と選び方のポイントをまとめます。

図3:生成AIモデルの選び方のまとめ
https://www.nttdata.com/jp/ja/trends/data-insight/2023/1024/
https://wandb.ai/wandb-japan/llm-leaderboard/reports/Nejumi-LLM-Neo--Vmlldzo2MTkyMTU0
3.生成AIモデルの使い分けに役立つTips
ここから、実際に使い分けるときに(特に図1のバランスを見て検討する観点で)知っておくと役立つTipsを紹介します。
生成AIによる生成AIの性能評価
従来のAIが得意とした分類タスクや数値予測タスクの評価は機械的に算出ができましたが、生成AIが扱う質問応答や要約などのタスクは定性的な評価も求められ、機械的な実施が難しい場合があります。人手での評価が望ましい一方でコストがかかるため、性能評価を生成AIが行うLLM-as-a-Judgeと呼ばれる技術があり、例えばGPT-4が評価した結果が人間の評価と相関すると報告されています(※6)。このような技術の活用により、評価工数の削減が期待できるでしょう。
モデルごとのプロンプトの使い分け
生成AIに入力するプロンプトについて、複数のモデル間で同じプロンプトを使うのではなく、モデルごとに推奨されるプロンプトのフォーマットに従うことが大切です。
さらに、生成AIから良い応答を得るためのテクニックとして、ユーザーの入力を工夫するプロンプトエンジニアリングがあります。このテクニックは、どのモデルに対しても共通的に有効なものもあれば、モデルによって異なるプロンプトを利用したほうが良い応答が得られる場合があります。プロンプトエンジニアリングガイドを発表しているモデルもあるため、それらを参考にしたプロンプトの調整をお勧めします(※7)。
開発者と生成AIを中継するミドルウェア
複数のモデルを検討する際、モデルごとのモデルファイル入手や、API仕様の確認は手間がかかることです。このような場合、開発者とモデルを中継するミドルウェアやサービスの利用も有効でしょう。例えばHugging Faceのようなモデルハブを利用すれば、多くのOSSモデルを一つのサイトから入手できます。LangChainのような開発フレームワークを利用すれば、異なるモデルを統一的なインターフェースで扱え、特にモデルの初期検討時において開発生産性の向上が期待できます。他にも、プロンプトに応じてモデルを自動選択するModel Routing技術など、ミドルウェアの領域でも新しい技術やサービスが登場していますので、継続的なキャッチアップが欠かせません。
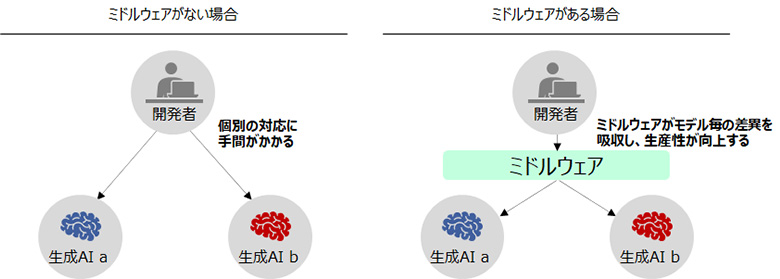
図4:生成AI開発におけるミドルウェアの利用
https://docs.anthropic.com/claude/docs/guide-to-anthropics-prompt-engineering-resources
4.おわりに
本記事では、複数の生成AIモデルを比較する観点やその使い分けについて解説しました。生成AIの発展は著しく、今後も情報のアップデートが必要です。NTTDATAでは、お客さまに最適なシステムをお届けするために、これからも様々な生成AIの調査と検証を継続してまいります。生成AIの活用についてお困りの際は、NTTDATAにお声がけください。

生成AI(Generative AI)の詳細はこちら:
https://www.nttdata.com/jp/ja/services/generative-ai/
データ&インテリジェンスの詳細はこちら:
https://www.nttdata.com/jp/ja/services/data-and-intelligence/
あわせて読みたい: