
はじめに
SOC(Security Operation Center)を立ち上げる、拡張する、あるいは運用を見直す際に、まず検討すべきなのは「SOCに何を期待し、何を成果として示すのか」という設計です。運用の初期段階では、対応件数や対応時間といった活動量は示しやすい一方で、「何が改善され、何が課題として残っているのか」といった成果を説明可能な形で示すことが難しくなることがあります。このズレが大きくなると、アラート処理が中心の運用に寄りやすくなります。
本稿では、アラート対応を「回す」だけで終わらせず、SOC起点で継続的な改善につなげるための考え方を紹介します。なお本稿はSOCの一般論を整理するものではなく、運用が行き詰まりやすいポイントを回避するための「設計・運用の勘所」を、実務の観測に基づいて示します。
なぜSOCはアラート対応中心になりやすいのか
SOCがアラート対応中心になりやすいのは、現場の努力不足というより、個々のツール設定や担当者の努力だけで解消しにくい「構造」の問題があるからです。
1つ目は、検知技術の高度化により、これまで見えにくかった事象がアラートとして可視化され、SOCが扱うイベントやアラートの総量が増加しやすくなることです。監視対象が増えるほど対応するアラートも増えるため、まずは「止めずに回す」ことが優先され、一次対応(トリアージ/初動)が中心業務として定着しがちです。
2つ目は、SOCの成果は検知や封じ込めによる被害の最小化にある一方で、「もし対応しなかった場合」との比較が必要になるため、その効果を直接数値で示しにくい側面があります。その結果、成果指標よりも説明しやすい対応件数や対応時間といったプロセス指標が、評価や合意形成の軸になりやすくなります。
この2つの構造的な問題が重なることで、アラート処理そのものが目的化しやすい運用構造が生まれます。さらに、一定規模を超えると、運用の行き詰まりが表面化していきます。
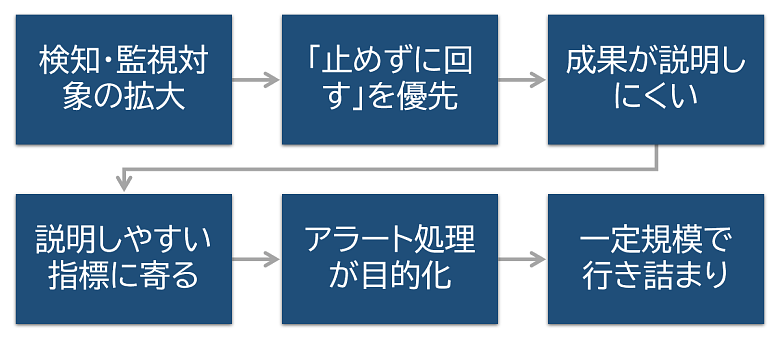
図1:アラート中心SOCの傾向
アラート中心SOCが抱える構造的な限界
限界(1):アラート総量の増加に歯止めがかからない
監視対象(クラウド/SaaS等)が増えるほど、SOCが扱うログ・イベント・アラートの総量は増加しがちです。誤検知はチューニングで抑制できますが、実際の監視対象が拡大し続ける限り新たな検知対象も増えるため、総量を恒常的に減らすことには限界があります。さらにアラート総量を減らすこと自体が目的化すると、チューニングの維持管理負荷や複雑性が増し、抑えすぎれば本来検知すべき事象の見落としにもつながり得ます。
限界(2):アラート単体では判断に必要な情報が不足する
アラートは「何が起きたか」は示しても、業務への影響や優先度、停止可否といった判断材料は十分でないことが多いです。そのため同じ事象でも、基幹システムか検証環境かで優先度が変わるにもかかわらず、SOCだけでは判断が完結できずシステム担当者や業務部門への確認が必要になります。結果として確認待ちがボトルネックとなり、判断が人の記憶や関係性に依存しやすくなります。この傾向は、判断基準が未整備であるほど顕在化します。
限界(3):判断が特定の担当者に依存しやすい
最終的な対応判断を人が担う以上、アラート中心のSOC運用は属人化しやすく、経験者に問い合わせが集中しがちです。その結果、一部の担当者に負荷が偏り、対応を「回すこと」が優先されるようになるほど、判断の背景や根拠が記録・共有されにくくなります。この状態では組織としての学習が進まず、同様の判断を個別対応として繰り返す構造が固定化しやすくなります。また、役割や判断範囲が明確でない場合、確認やエスカレーションも増え、課題をさらに助長します。
次章では、決めておくべき設計・運用の勘所を、3つの秘訣として整理します。
SOCが詰まないための3つの秘訣
秘訣(1):「判断の物差し」を先にそろえる
アラート対応が滞る要因は、個々のアラートの難しさというより、判断の物差しがそろっていない点にあります。重大性・優先度・エスカレーション条件(誰に/いつ連絡するか)・SOCが判断し実施してよい措置などを言語化し、関係者で合意しておくことが重要です。基準がそろうと、「その場の判断」や都度の確認が減り、対応の速度と品質が平準化します。結果として属人性が下がり、部門連携も進めやすくなります。
秘訣(2):アラートを「処理」で終わらせず、「改善」につなげる
アラートは原因ではなく、設定や運用の状態が表面化した「結果」として現れることが多いです。そのため、実際の攻撃でなかったとしても、判定して終える運用だけでは、同種の事象が繰り返され、負荷が減りにくい構造が残ります。アラートを起点に「なぜ起きたのか」を整理し、誤設定や権限、運用ルールなどの改善につなげることが重要です。ここでの改善とはSOC運用だけでなく、影響を受けるシステムの脆弱な設定や構成の改善も含みます。大掛かりな変更に限らず、小さな是正を継続的に積み上げることで同種のアラート発生を抑制でき、再発抑止と運用負荷の低減につながります。
秘訣(3):部門連携を「個人技」ではなく「仕組み」にする
アラート単体では判断材料が不足しがちなため、他部門やシステム担当者との連携は不可欠です。ただし、連携が個人の関係性に依存すると、照会・回答のばらつきが生まれ、関係部門への確認待ちがボトルネックとなります。そこで、やりとりの型(誰に/何を/いつまでに)を決め、照会と回答を標準化することが重要です。型が整うほど合意形成を進めやすくなり、判断の停滞を防げます。
たとえば、ログの傾向分析から、ある脆弱になり得るプロトコルや運用手順が恒常的に利用されていることが判明したケースでは、直ちに影響を受けると断定できなくても、放置すれば将来的な弱点となり得ます。この場合、利用実態の確認(関係部門へのヒアリング)と是正方針の合意を行い、改善計画へつなげていくことが重要で、流れを仕組みとして定着させることによって、アラート対応を「判定で完了」ではなく「改善の入り口」として活用できます。
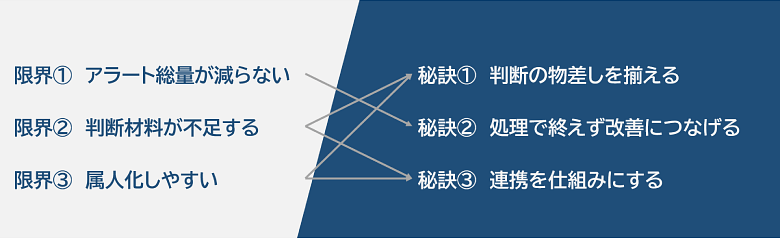
図2:3つの限界と3つの秘訣
おわりに
3つの秘訣は、「判断の迷い」「関係部門への確認待ち」「同種対応の反復」をなるべく減らし、本来注力すべき改善活動を取り戻すための設計ポイントです。まずは発生頻度が高い領域に絞って、判断基準の言語化と連携の型化を進め、運用が安定してきた段階で、アラート対応を改善へつなげる流れを小さく始めることが現実的です。
こうした積み重ねにより、SOCの活動は単なる対応量の積み重ねではなく、組織全体のリスクの発見や低減につながる継続的な改善活動として捉えやすくなります。SOCの運用に正解はなく、置かれた環境や体制によって取るべき形も異なります。本記事で紹介した考え方が、アラート対応に課題を感じている読者にとって、自らのSOC運用を見直す一つの視点となれば幸いです。

EDRとSIEMの違い|連携による相乗効果と導入のポイントについてはこちら:
https://jp.security.ntt/insights_resources/security_magazine/edr-siem-difference/
国内マネージドEDR市場は前年比42.6%増、中堅・中小企業に導入が広がる─ITRについてはこちら:
https://it.impress.co.jp/articles/-/25633
あわせて読みたい: