
はじめに:企業間データ連携の必要性
複数の企業が保有する情報を機械学習に活用するためのデータ収集や、二酸化炭素排出量をゼロにするカーボンニュートラルの実現に向けたサプライチェーン上のデータ収集など、企業同士の協働によるイノベーションや社会課題の解決に向けて、企業や業界、組織を超えたデータ連携の必要性が高まっています。 一方、複数の企業からデータを収集する場合、各社の取り決めやインターフェースに沿ったデータの送受信が必要とされるので、ユースケースごとに仕組みやアーキテクチャを検討・実現しなくてはなりません。そこで業界・企業横断で用いられるデータ連携の技術、基盤が期待されています。
NTT DATAが取り組むデータ連携基盤のその他取り組みについては、過去の記事(※1)(※2)(※3)を参照ください。

図1:データ連携基盤の全体像
データ連携を支える技術は多々ありますが、ここでは企業同士が利用したいデータを探して集めるまでの課題を解決する機能を紹介します。
データ連携を支えるその他の技術については、過去の記事(※4)(※5)を参照ください。
実際に企業同士がデータを探して集めるまでにどのような課題に直面するのでしょうか?ここでは、図2に示す企業間データ連携の流れに沿って考えていきます。
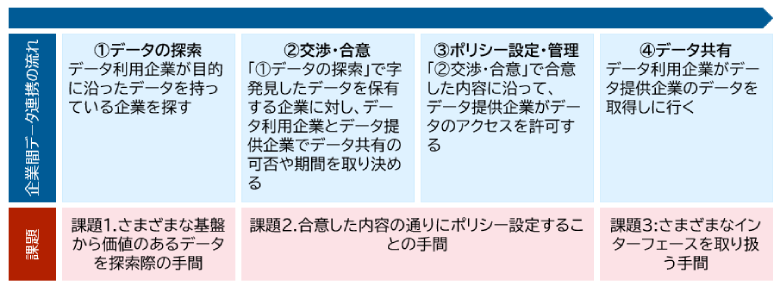
図2:企業間データ連携の流れと課題
データ連携基盤の動向:国内の議論も進む企業間データ流通インフラの実現構想 ~ウラノス・エコシステムが目指す国内産業界のデータ連携基盤~
IDS・Gaia-Xの概要:注目!欧州発の企業間データ連携の仕組み作り:IDS・Gaia-X
データ利活用を促進するデータスペースの概要:データスペース
企業間データ連携の安全性を高める秘匿処理技術:企業間データ連携の安全性を高める秘匿処理技術
企業間データ連携のデータ共有を担うコネクタ技術:データスペース技術動向
データの探索時の課題と解決のための機能
課題1.さまざまな基盤から価値のあるデータを探索する際の手間
最初に課題となるのが、さまざまな基盤から価値のあるデータを探す手間が挙げられます。例えば、データ利用企業Aが機械学習に使用するため、複数の企業から「学習データ」を収集するシーンを考えてみましょう。利用したいデータは、各企業によってパブリッククラウドやオンプレミスシステムなど、さまざまな基盤に分散している可能性があります。目的に合った価値のあるデータを見つけるためには、それぞれの基盤に対して個別のプロトコルに沿ってデータを探す必要がありますが、各基盤を行き来しながら探していく場合、結果として価値のあるデータを探し出すのに多大な時間がかかる恐れがあります。

図3:価値のあるデータを検索することの手間と解決の機能
メタデータの一元管理機能
この課題を解決するためには、各基盤に保存されているデータのファイル名や登録日時などのメタデータを一元的に管理し、データを探す際に利用させるような機能(メタデータの一元管理機能)が有効と考えられます。 例えば、データ利用企業Aがこの機能を持つコンポーネントによってデータを探す場合、「学習データ」に関連したメタデータ(図3の例では「学習データ」というファイル名)の検索を、メタデータの一元管理機能を持つコンポーネントに対して行います。すると、データ利用企業Aは、メタデータの一元管理機能を持つ基盤に対してのみアクセスすることで「学習データ」を見つけ出すことができ、各基盤に対して個別に検索する必要がなくなります。これにより、基盤を行き来して検索するような時間の無駄を最小限に抑えることが可能になります。
交渉・合意~ポリシー設定・管理時の課題と解決のための機能
課題2.合意した内容の通りにポリシー設定することの手間
データ利用企業Aが学習データとして価値のあるデータの所在を発見できたとしても、そのデータを共有してもらうためには、データ提供企業に対し、データを共有して欲しい旨の合意を得た後にデータ提供企業側にアクセス条件の設定変更をしてもらう必要があります。この際に課題となるのが、交渉・合意で使用したツール(メールやチャットなど)の内容をファイルの送受信システムのポリシーに反映する手間です。
例えば、データ利用企業Aがデータ提供企業Bに、「学習データB」へのアクセスを「10日間許可する」という交渉を行った場合を考えてみます。交渉のツールとしてメールを利用した場合、サイズが大きい学習データ自体をメールで送付することは難しくなります。この場合、データ提供企業Bは、メールで交渉した「学習データB」へのアクセスを「10日間許可する」という内容をファイル共有システムのポリシーに反映する必要があります。このように、データ共有のたびに合意事項を間違えずにファイル共有システムに反映させるという手間が発生します。

図4:合意した通りにポリシー設定することの手間と解決の機能
ポリシー連携機能
この課題を解決するためには、合意した内容をファイルの送受信のツールに反映するような機能(ポリシー連携機能)を持った基盤を使用するアプローチが有効であると考えられます。 例えば、データ利用企業Aがこの機能をもつコンポーネントを用いて交渉を行った場合、データ提供企業Bとの間で交渉・合意した「学習データB」へ「10日間のアクセスを許可する」という内容がファイル送受信のシステムのポリシーに自動的に適用されます。これにより、データ提供企業Bでもともと実施していたような、手動でのポリシー設定を省くことができ、その結果、手間やミスを最小限に抑え、効率的なデータ共有が可能となります。
データ共有時の課題と解決のための機能
課題3.さまざまなインターフェースを取り扱う手間
データ利用企業とデータ提供企業間でデータの使用について合意形成およびポリシーの設定変更がされると、いよいよデータ共有を行うフローとなります。この際に課題となるのは、複数のシステムをまたがるような共有インターフェースを取り扱う手間です。
例えば、データ利用企業Aがデータ提供企業B、C、Dの学習データを取りに行くことを考えます。すると、データ利用企業Aは「データ提供企業Bのデータを取得するためクラウドXにアクセスし、データ提供企業Cのデータを取得するためにクラウドYにアクセスし、データ提供企業Dのデータを取得するために、、」というように、企業毎にインターフェースに沿ってデータを取得する必要があります。このようなケースではインターフェースを行き来することになり、多くの時間がかかることが懸念されます。
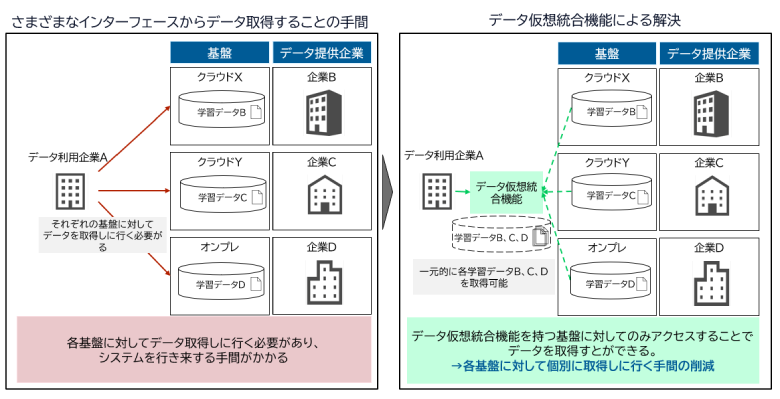
図5:さまざまなインターフェースからデータ取得することの手間と解決の機能
データ仮想統合機能
この課題を解決するためには、複数の基盤からデータを一元的に取得できる機能(データ仮想統合機能)を提供するアプローチが有効と考えられます。
例えば、データ利用企業Aが学習データB、C、Dを取得する場合、データ仮想統合機能を持つコンポーネントにアクセスします。このコンポーネントには、各基盤に存在するデータを取得する機能が備わっているため、データ利用企業Aはひとつのコンポーネントから全ての必要なデータを取得することができます。これにより、各基盤に対して個別にデータを取得する手間と時間が軽減され、作業効率を向上させることができます。
おわりに
今回は、データの探索からデータ共有という流れに沿った課題についての詳細を説明しましたが、NTT DATAでは解決についての機能開発を実施しています。 NTT DATAでは、様々な企業の方が抱えているデータを活用し、ビジネス価値創出を支援するためのソリューションを提供しています。ご興味をお持ちいただけましたら、是非お問い合わせください。

データスペースについてはこちら:
https://www.nttdata.com/jp/ja/services/dataspace/
あわせて読みたい:
~ウラノス・エコシステムが目指す国内産業界のデータ連携基盤~
~Eclipse Dataspace Components(EDC)とDataspace Protocol~