
1. はじめに
NTTデータは10年以上前から並列分散処理のためのオープンソースソフトウェアに関する研究開発、それらを活用したシステム開発に携わってきました。また様々なプロジェクト経験から得られた知見を開発コミュニティへの貢献活動を通じて世の中に還元してきました。これらの経験を元に、「データ活用基盤を実現するオープンソースソフトウェアの歴史やデータレイクに関する技術の新潮流」、「オープンソースのビッグデータ活用基盤技術と機械学習技術の連係に関する事例」の2件について、国際カンファレンスOpen Source Summit(※1)にて福久、梅森、土橋が講演しました。
https://events.linuxfoundation.org/open-source-summit-japan/
2. データレイクアーキテクチャの歴史と変遷
本発表では「History and Evolution of Data Lake Architecture - Post Lambda Architecture」と題し、最初にデータレイクやストリーム処理を実現するオープンソースソフトウェアの歴史を紐解いて紹介しました。2008年頃から台頭してきたApache Hadoop(※2)に始まり、Apache HBase(※3)、Apache Kafka(※4)、Apache Storm(※5)、Apache Impala(※6)、Presto(※7)、Apache ORC(※8)、Apache Parquet(※9)など、関連する技術の背景・特徴を紹介しました。
ここで挙げた技術は一例ですが2021年現在に至るまで、多数の技術が登場しています。これらは同一目的・内容の技術だけではなく、互いに補完関係にあるものも多く、システムを実現する際には様々なトレードオフを踏まえたうえで組み合わせていく必要があります。
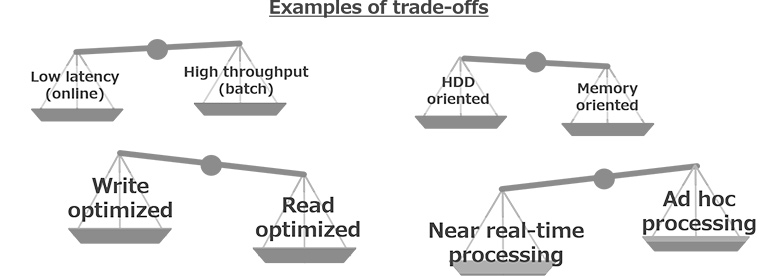
図1:トレードオフ関係の例
またトレードオフ関係にある処理を統合する一例として、データを定期的に蓄積・処理する「バッチ処理」の流れと、時々刻々と生じるデータを処理する「ストリーム処理」の流れを統合する考え方「ラムダアーキテクチャ」について触れました。
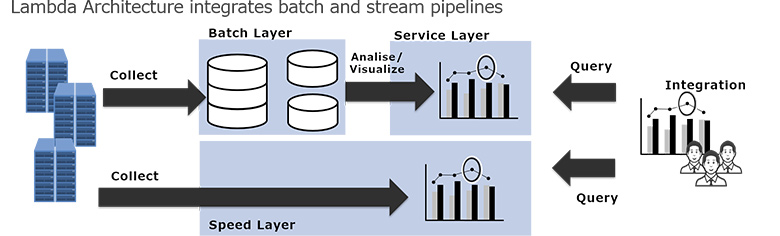
図2:ラムダアーキテクチャの考え方
このアーキテクチャは、2種類の流れを考慮してデータを統合し活用するのが大変であることが難点です。そこで近年注目を集めている「ストレージレイヤソフトウェア」という技術を用いて、データレイク周りのアーキテクチャを描きなおす考え方の例を紹介しました。
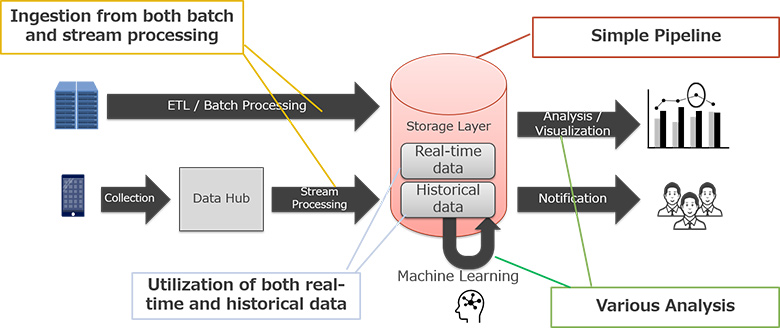
図3:ストレージレイヤソフトウェアを活用したシステム実現のイメージ
発表では2018年以降登場したApache Iceberg、Apache Hudi、Delta Lakeといったオープンソースソフトウェアを紹介しました。特に、まだ黎明期の技術であることから「似ているところ」、「異なるところ」が分かるように、誕生の背景、主な特徴、下層のストレージ技術、対応ファイルフォーマット、データ構造など内部実装調査に基づく見解も踏まえて説明しました。
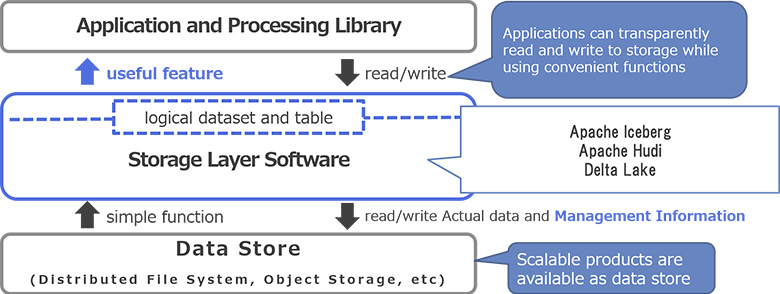
図4:旧来のアーキテクチャに対する位置づけのイメージ
3. ビッグデータ活用基盤技術と機械学習技術の連係事例
本発表では、「Lessons Learned from the Collaboration of Big Data and AI/ML Technologies for Giant Hogweed Eradication」と題し、ビッグデータ活用基盤技術と機械学習技術の連係事例を紹介しました。
発表冒頭では取り組み背景として、デンマークにおける危険外来種植物に関する課題、取り扱うデータ、画像を用いた対象物検知の処理イメージを紹介しました。
本システムでは、ドローンが撮影した空撮画像を利用し、機械学習を用いて学習したモデルにより特定の危険外来種植物の生息有無を自動検知します。広大な土地の空撮画像のデータ量は膨大であるため、NTTデータのビッグデータ活用基盤リファレンスアーキテクチャを基に図5の通り並列分散処理基盤であるApache Hadoop、Apache Sparkをデータ活用基盤の中心に据えて、TensorFlow(※10)と連係させるアーキテクチャを構成しました。
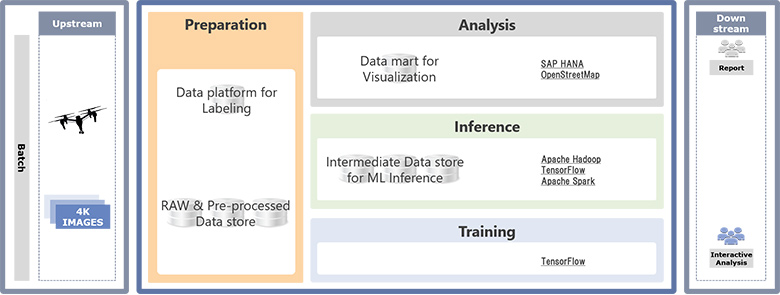
図5:採用した主要技術
本システムで取り扱うデータ処理の流れは、NTTデータのビッグデータ活用基盤リファレンスアーキテクチャ(※11)(※12)をベースとした図6のような矢印で描かれる「パイプライン」に沿って整理できます。本発表では、大きく4つのパイプラインに沿ってポイントを紹介しました。
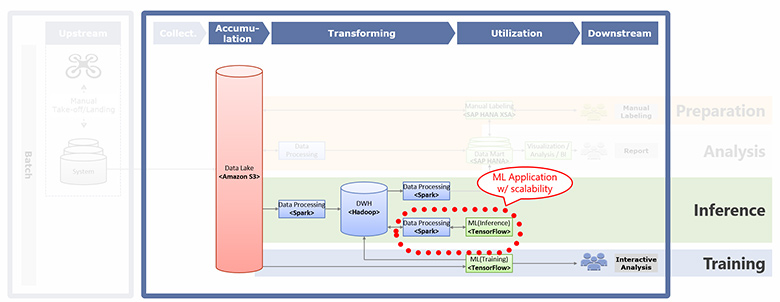
図6:データ処理パイプラインの一例
発表後半ではパイプラインの詳細や設計思想に踏み込み、図7のようなステークホルダやフェーズの違いを意識した技術選定の考え方を紹介しました。特に、機械学習ならではのモデル開発(Dev)・運用(Ops)の性質に着目し、これらの組み合わせパターンに応じた技術選定とその具体例について言及すると共に、先進企業におけるオープンソースソフトウェア活用の具体事例等について言及しました。
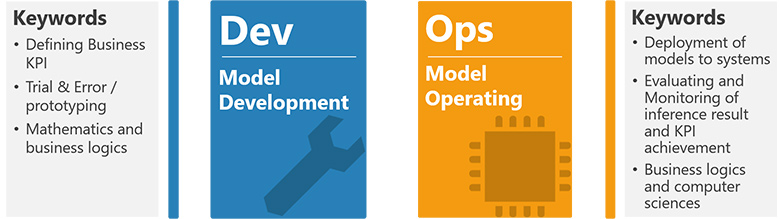
図7:フェーズやステークホルダの違い
本システムでは、システム全体の性能担保を考慮するのみならず、Dev・Opsの責任分解モデルの考え方を踏まえたデータの流れと図5で示したような複数の技術の組み合わせ方が重要でした。本発表ではその中でも特に、Apache SparkとTensorFlowを例とした処理フレームワーク、実装イメージを例示することでオープンソースソフトウェアの具体的な組み合わせ方を示しました。
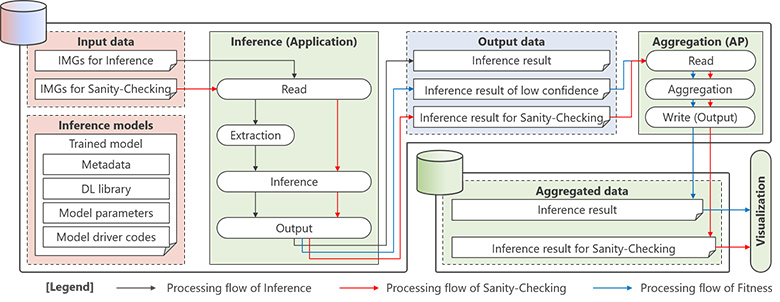
図8:処理の流れと組み合わせ方の例
https://www.nttdata.com/jp/ja/news/services_info/2021/012900/
4. まとめ
データ活用基盤の実現には、多くのオープンソースソフトウェアが活用されています。近年、ユースケースが多様化し、さまざまな技術が登場することで、少し複雑になり分かりづらくなった印象があります。そこで今回の登壇では、NTTデータの知見を踏まえつつ、事例や技術の組み合わせ方の例を添えて、関連技術を俯瞰する内容を説明しました。
本発表の中心トピックである「データを蓄積・流通・処理するための技術」はデータを活用したサービス、業務の起点で使用される重要なものであると考えており、私たちはこれまでにないデータ駆動の業務、ビジネスを実現しやすくするための研究開発にも取り組んでいます。例えば、ストレージレイヤソフトウェアはその一例です。またそのような要素技術を効果的に組み合わせて使うためのリファレンスアーキテクチャも取りまとめており、2件目の発表のように様々なプロジェクトに適用しています。今後も得られた知見を世の中に還元し、業界全体の技術力向上に寄与していきたいと思います。
