
1.大規模言語モデルの台頭
「AIが人間の能力を超えた」という話を各所で聞くようになりました。たとえば、人が翻訳した文よりAIが翻訳した文のほうが自然な訳になっていることも珍しくないでしょう。また、AIが書いた文章が、人間が書いたものであると間違われる事例も知られています。これらの背景には、AIが人間の言葉を上手く扱うための“言語モデル”の存在があります。
近年、特に注目が集まっているのは「GPT-3」などの大規模言語モデルです(※1)。これらの言語モデルは、1000億を超える規模のパラメータを持ち、人間が一生かかってもインプットできないような量のデータを学習します。少し技術的な話に踏み込むと、GPT-3は“汎用”言語モデルに分類されます。事前に大量のデータを学習させておくと、推論時にタスクの説明文といくつかの例を与えるだけでそのタスクを解けるようになります。たとえば、「英語からフランス語に翻訳せよ」という説明文と、具体的な英文と仏文のペアを例示するだけで、任意の英文を仏文に翻訳できるようになります。翻訳を目的として訓練されたわけではないにもかかわらず、高い水準の機械翻訳が実現できてしまうというので驚きです。
GPT-3のインパクトは、私のようなソフトウェア研究を行う人間にとっても大きなものでした。というのも、GPT-3のデモンストレーションの中には、自然言語文からソフトウェアプログラムを自動生成するものがあったからです。まるで英語をフランス語に翻訳するように、GPT-3は英語をプログラミング言語に翻訳するというのです。
2.自動プログラミングの研究
自然言語などの抽象的な仕様からプログラムを自動生成する技術(学術的に言うと「プログラム合成」)には長い研究の歴史があります。参考として、昨年のNTTデータテクノロジーカンファレンスの講演の動画(https://www.youtube.com/watch?v=3Ccq2bY6BkE)をご覧ください。近年の研究動向としては、自動プログラミング技術はSyGuS(https://sygus.org/)などの研究コミュニティを中心に研究されてきました。SyGuSコミュニティでは、自動プログラミングのアルゴリズムの性能を測るためのベンチマークの提供や、定期的なコンペティションの開催を行っています。
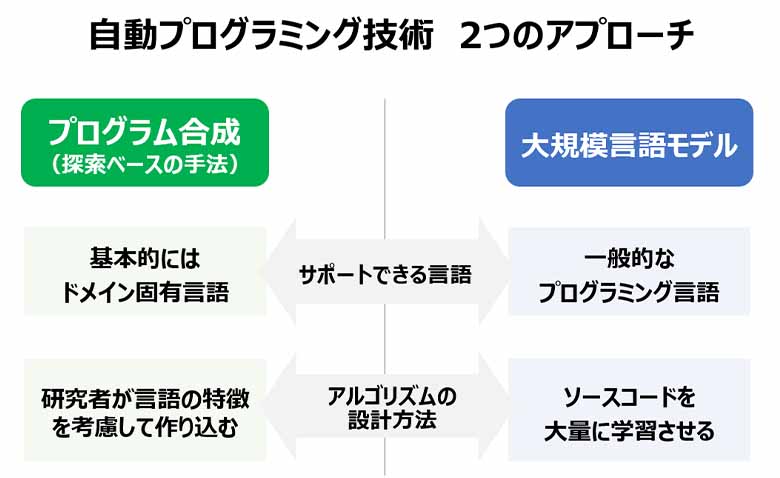
SyGuSなどの研究コミュニティで開発されてきた自動プログラミング技術は、構文がそれほど複雑でない独自のプログラミング言語(いわゆるドメイン固有言語)を用いてプログラムを生成するものがほとんどでした。自動プログラミングのアルゴリズムとしては、プログラミング言語を構成する各命令を上手く組み合わせながら仕様に合うものを探索するというアプローチが多くを占めています。つまり、研究者たちがプログラムの意味を考慮しながら、探索アルゴリズムを慎重に設計してきたといえます。一方で、このような設計方針は対象とする言語がシンプルな場合にのみ可能であり、PythonやC言語といった一般的なプログラミング言語を対象とすることは難しいとされてきました。
GPT-3のアプローチは、このような従来のやり方とはまったく異なります。GPT-3はインターネット上にあるウェブコンテンツを大量に学習するのみで、プログラミング言語がもつ構文や意味を明示的に教える必要はありません。しかも、GPT-3が生成するのは一般的なプログラミング言語を用いたプログラムであり、従来の自動プログラミング技術と比較すると破格といえるのです。
このような背景を踏まえ、世の中のソフトウェア研究者たちは大規模言語モデルによる自動プログラミングの可能性を探ることになります。以下では、2021年に発表された2つの最新研究について概要を紹介します。
3.Google Researchによる実証実験
Google Researchの研究チームはProgram Synthesis with Large Language Modelsという題目の論文を公開しました(https://arxiv.org/abs/2108.07732)。この論文では、1370億個のパラメータをもつ言語モデルを構築し、自然言語による説明文といくつかの入出力例からPythonプログラムを自動生成する実験を行っています。具体的には、与えられた入力をもとに80個のPythonプログラムを自動生成し、その中に正解プログラムと同じ意味を持つものが含まれているか調べています。学習データとして、インターネット上で収集したウェブページや会話データ、Wikipediaの記事など計30億個近くのコンテンツを用いています。実験の結果、入門レベルのプログラミングの問題974件のうち、約60%に対して正しいPythonプログラムを自動生成できたとの報告があります。入門レベルの問題とはいえ、これは従来のテクノロジーから考えるとかなり高い数値であり、やはり大規模言語モデルを用いた自動プログラミングは有効であるといえます。
さらに興味深いことに、この論文では「言語モデルがプログラムの意味を理解しているのか?」という問いに答えるための実験が行われています。具体的には、プログラムを自動生成する代わりに、プログラムに特定の入力値を与えたときの出力値を予測するようなタスクを設計しています。この実験の結果、プログラムと入力値だけからは出力値に対する高い予測精度は出なかったそうです。すなわち、現状の大規模言語モデルは、プログラムの意味を考慮したうえで仕様に合うようなものを生成するほど賢いわけではなさそうです。あくまでタスクの説明文や与えられた入出力例に対して、字面として自然なプログラムを生成しているに過ぎないというわけです。
4.ソースコードを学習した言語モデル
ここまで紹介した言語モデルでは、学習データとしてインターネット上から収集した大量のウェブページを用いていました。学習データの中にはソースコードを掲載しているものも含まれているため、言語モデルが自動プログラミングの能力を獲得できたわけです。ここまでの話を聞いて「より多くのソースコードを集中的に学習させれば、より複雑なプログラムを生成できるようになるのではないか?」と思った方もいらっしゃるのではないでしょうか。
OpenAIの研究チームは、この疑問に答えるべくEvaluating Large Language Models Trained on Codeという論文を公開しました(https://arxiv.org/abs/2107.03374)。この研究ではCodexという大規模言語モデルを構築しています。言語モデルCodexは、GitHub上で公開されている計159ギガバイトものPythonファイルを学習データとして用いています。なお、ソースコードにはコメント文などの自然言語文が含まれているため、他の言語モデルと同様に自然言語文の仕様とプログラムの対応関係を学習できます。実験の結果、164件のプログラミングの問題のそれぞれに対して1つのプログラムを生成する場合、ソースコードファイルを学習していない言語モデル(GPT-J)が解けた割合は11.4%であったのに対し、Codexはそれを上回る28.8%であったと記載されています。さらに、問題ごとに生成するプログラム数を100個まで増やすと、すべての問題のうち70.2%に対して1つ以上の正解プログラムを生成できるようになったそうです。これらの結果から、近年の大規模言語モデルは、学習データとしてソースファイルを用いることで、自動プログラミングに対する性能が大きく向上するといえそうです。
この研究で開発された言語モデルCodexは実用化されており、GitHub Copilotというサービスとして一般向けに提供されています。開発者がコーディングをするときに、先にコメント文を記述するだけで自動的にプログラム本体が生成されるようなユースケースを提案しています。このようなユースケースは従来の技術ではあまり現実的でなかったこともあり、新たなソフトウェア開発のスタイルとして注目を集めています。
5.AIはプログラムの意味を理解できるか?
ここまでの話では、大規模言語モデルを用いた自動プログラミング技術について紹介しました。実は自動プログラミングのみならず、ソースコードがもつ意味を理解するための機械学習技術は盛んに研究されています。
たとえば、Microsoft Researchのメンバーを中心とした研究チームは、機械学習分野のトップ国際会議ICML2021でHow could Neural Networks understand Programs? (ニューラルネットワークはいかにしてプログラムを理解できるか?)という論文を発表しています(https://icml.cc/virtual/2021/poster/9087)。この研究はソースコードがもつ意味の理解に特化した汎用言語モデルを提案するものであり、ソフトウェア開発における様々なタスクを効率化する狙いがあります。その他の機械学習を用いたソフトウェア研究についてはMachine Learning for Big Code and Naturalnessというウェブサイト(https://ml4code.github.io/)に最新研究が整理されているので、興味のある方はご覧ください。
6.さいごに
本稿では、大規模言語モデルを用いた自動プログラミング技術について紹介しました。我々NTTデータの研究チームでも、自動プログラミング技術の実用化に向けて研究開発を行っています。最近の研究成果として、データベース分野の最難関国際会議VLDB2021にて、入出力例からSQLクエリを自動生成する技術を発表しました(※2)。
今後も、引き続きアカデミックな研究動向をウォッチしつつ、実用的なソフトウェア技術の研究開発を続けていきます。ソフトウェア研究に関する情報交換や、共同研究・学生インターンなど、ご興味のある方はお気軽に「お問い合わせ」ボタンよりご一報ください。
