
1.従来のソフトウェアとは異なるAIの特性
AIは学習と呼ばれる機能によって入力されたデータに潜む様々な関係性を抽出し、細かな条件分岐を記述することなく、多様な入力に対して期待する値を出力する推論処理を獲得します。この推論処理は、昨日までの売り上げデータを入力として明日の売り上げを出力として得る場合は予測と呼ばれ、写真などの画像を入力として画像内の植物の種類を出力する場合は認識や分類と呼ばれます。
従来のソフトウェアと比較すると、AIが学習によって獲得する処理を開発者が完全にはコントロールできないことが大きな違いです。一般的に、ソフトウェアは開発者によって記述されたプログラムに沿って入力を処理します。想定外の出力が得られた場合は、プログラムのどこかに開発者の意図しないバグが存在するはずです。一方で、AIは学習時に入力されたデータ(学習データと呼びます)によって自動的に推論処理に必要なパラメータの最適化を行うため、開発者が同じプログラムを記述したとしてもデータが変われば異なる処理を獲得します。
この時、AIは学習データ間の関係性を用いた推論処理を獲得しています。そのため、下記のような場合には期待する値を出力できない可能性があります。
| 問題が発生する可能性がある場合 | 例 |
|---|---|
| 学習データに似たデータが無いデータが入力された | 花の分類のために日中の画像のみを学習に用いたAIに夜間の画像を入力する |
| 学習データ内に似たデータが少ないデータが入力された | 車載カメラ画像で学習したAIに雪の日や工事現場などの希少なケースの画像を入力する |
| データ間の関係性が変わってしまったデータが入力された | 学習時には合格だったが、基準が変わって不合格になった 季節が変わって売れる商品が変わってしまった |
一般的に、AIを導入したいユースケースにおいて、学習データは過去に観測されたデータを用いるため、運用後に入力されるデータよりも多様性が乏しくなります。特に、エンドユーザーからのデータ入力を許すような場合には、学習時には想定していなかったデータが入力されることがあります。
このような場合、新たなデータを学習データに追加して、再学習を行うことでAIの推論処理を最新化することが可能です。AI自体には推論処理の失敗に気づく機能は無いため、外部からデータや推論結果をモニタリングしてその予兆をつかむ必要があります。このモニタリング機能に強みを持つソリューション開発を進めている企業がCitadel AIです。
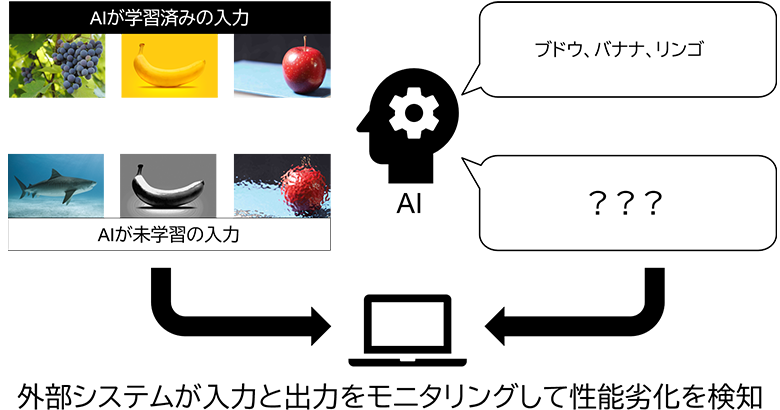
図1:AIの性能劣化を検知
2.Citadel AIのAIモニタリングソリューション
株式会社Citadel AIは「24時間信頼できるAIをあなたに」を事業ビジョンに、AIを自動モニタリングするためのソリューション「Citadel Radar」を開発しています。Citadel Radarは運用しているAIに入力されたデータを可視化し異常を検知・ブロックすることで、正常なシステム運用を支援します。現在は表形式データを入力とするAIをサポート対象にしていますが、画像を入力とするAIのサポートや検知機能拡張などを進めています。
また、Citadel AIは本稿で紹介するCitadel Radarだけでなく、開発が完了したAIに対して自動でストレステストを行う「Citadel Lens」を開発しています。
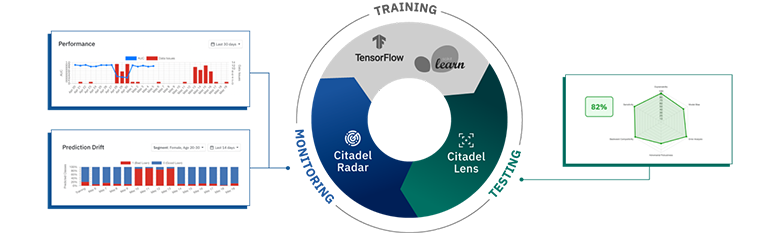
図2:Citadel AI社のソリューション「Citadel Radar」と「Citadel Lens」
3.安定的なAI運用の実現に向けた共同実験
安定したAI運用の実現に向け、Citadel Radarを用いた運用支援が可能か、Citadel AIとNTTデータは金融系の公開データを用いたAI構築を通して実験を行いました。
実験に用いたデータは融資審査業務を対象にしたもので、融資の対象者の各種属性と対象者に実際に割り付けられた融資可否のフラグを含みます。今回は実験のために対象者の属性の内、勤続年数が短い人のデータを多く抽出して学習を実施しました。そうして構築されたAIは勤続年数が短い人に対しては適切に推論が可能で、学習データに少ない勤続年数が長い人のデータに対してはうまくいかないことが想定されます。また、その他の異常検知機能を実験するために様々な加工を行い、AIに入力した際の挙動をCitadel Radarで調べました。
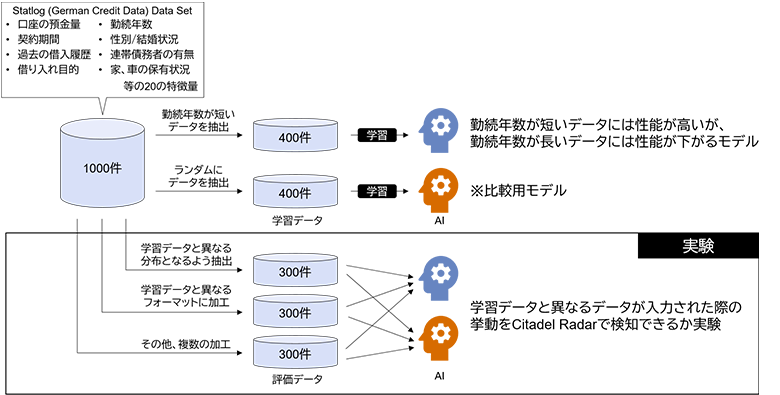
図3:実験設定
今回の実験ではOpen Cloud環境に構築されたCitadel RadarにAIモデルと入出力データを登録し、その結果をブラウザからモニタリングしました。(なお、Citadel Radarには投入されたデータが異常な場合に入力を保留するためのFirewall APIも存在しますが、本実験では目的外のため使用していません。)
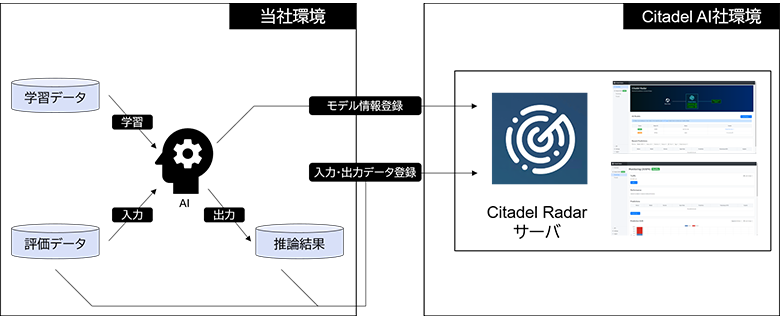
図4:実験環境の概要
それでは、入力したデータとCitadel AIによる検知内容の一例を紹介します。
入力データとCitadel Radarによる検知の一例
| 入力データ | Citadel Radarによる検知可否 |
|---|---|
| 学習データから特徴量数を減少させたデータ | Schema Violationsアラートが発生し、検知可能 |
| 学習データの特徴量に含まれないカテゴリのデータ | Schema ViolationsアラートとRisky Prediction Detectedアラートが発生し、検知可能 |
| 学習データに含まれる値から極端に離れた値のデータ | Schema Violationsアラートが発生し、検知可能 |
| 大量の勤続年数が長い人のデータ | Data Skewアラートが発生し、検知可能 |
| 大量の学習データと傾向が異なるデータ | Data Skewアラートが発生し、検知可能 |
個々の入力に異常が存在する場合についてはSchema Violationsというデータの定義に沿わないデータが投入されたことを示すアラートが発生し、また、学習時に観測した値から大きく離れた値や十分なデータ量が存在しないカテゴリを持つデータに対してはRisky Prediction Detectedという得られた出力に十分な信頼性が無いことを示す警告が発生しました。加えて、学習データとは異なる分布のデータが大量に入力された場合では、Data Skewアラートが発生し、学習時のデータの傾向と現在の傾向が変わり始めていることに気づくことができました。実際に分布の変化が発生している状態でのAIの推論精度を確認すると、学習時と同様の傾向のデータに対しては73%の正答率だったのに対して、傾向変化後のデータに対しては48%まで正答率が下がっていることが分かりました。そこで、分布変化後のデータと同様の傾向を持つデータを学習データに追加して再学習を実施すると、正答率が68%まで回復することが確認できました。
このようにCitadel Radarを活用することで、常にAIを監視し続けることなくトラブルを検知し、適切な対応を取ることができるようになり、安定した運用に寄与できることを確認しました。
4.まとめ
本稿では、AIの挙動をコントロールすることの難しさや長期運用によるAIの性能劣化などのAI固有の課題について説明し、Citadel Radarを用いた実験を通して、運用時に発生するデータの異常やモデル性能の劣化を検知できるか、またその対策は可能か確認しました。NTTデータでは、信頼可能なAIの社会実装を目指し、AI固有の特性を踏まえたサービス提供のための技術開発、技術検証を続けていきます。
