
1.クロスドメインでのデータ流通における安全性について
企業や業界を超えたデータ連携では複数のプレーヤーがデータを持ち寄って活用します。ただし、これらのデータは個人のプライバシーや企業の機密情報を含むこともあるため、自組織以外のプレーヤーには秘匿しなければなりません。本記事では安全性を確保してデータを連携・活用するために重要な技術について紹介します。本記事で紹介しきれなかった他のさまざまなデータ保護技術について、筑波大学との共同研究をもとに作成したホワイトペーパーで解説していますので、そちらもぜひご覧いただければと思います。
https://www.nttdata.com/jp/ja/news/information/2022/072800/
2.データ保護技術カテゴリマップ
データを秘匿化した状態で活用することがデータ保護技術の目的です。そのための手法として主にデータを暗号化したまま処理を実行する「秘密計算」、データから個人を特定できる情報を取り除く「匿名化」、データ自体は共有せず機械学習モデルの情報だけを共有する「プライバシー保護ML」があります。
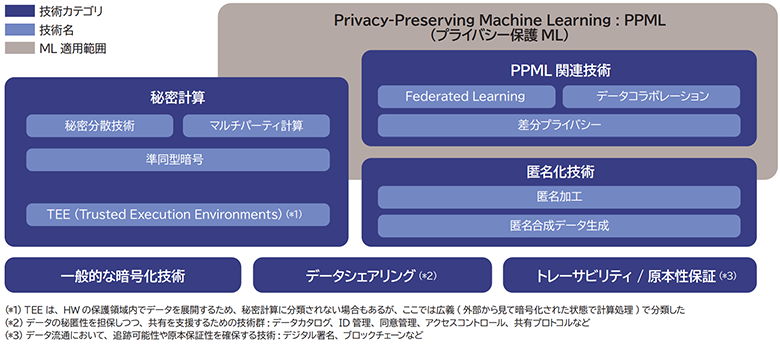
本稿ではプライバシー保護MLについて、もう少し詳しく解説します。なお、どういったデータを秘匿の対象にすべきか、また秘密計算、匿名化とはどういった技術かについては以前のDATA INSIGHTで紹介していますので、ぜひそちらもご覧ください。
https://www.nttdata.com/jp/ja/data-insight/2021/1122/
3.プライバシー保護ML関連技術
プライバシー保護ML(PPML)技術はオリジナルデータを持つデータ分析者(パーティ)が複数いる状況で、オリジナルデータを共有せず機械学習を行うための技術です。
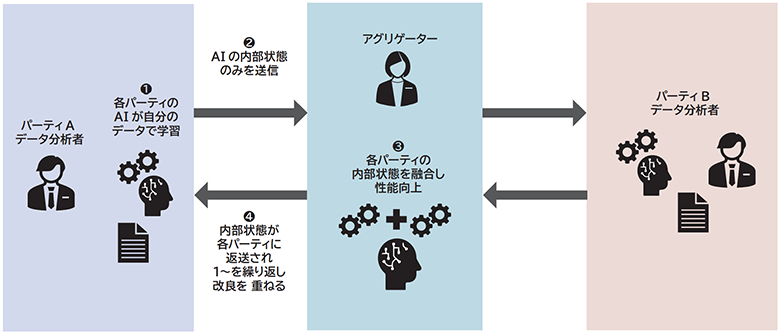
Federated Learning
Federated Learning(連合学習)はプライバシー保護MLとして良く知られた技術です。
- オリジナルデータを持つ各パーティは自分のデータで学習を進め、学習モデルのパラメータをアグリゲーターに集めます。アグリゲーターがパラメータ情報を融合させて学習モデルを作り、その結果を各パーティに返送して学習を続けます。
- ニューラルネットワークモデルを用いた機械学習で利用されます。
- オリジナルデータは、他のパーティ、アグリゲーターには知られませんが、パラメータのやり取りを頻繁に行うため、学習完了までには通信が多数必要です。
派生技術も多数生まれていて、ブロックチェーンを利用したSwarm Learning(※1)や中間ノードを共有するSplit Learning(※2)などがあります。
データコラボレーション
データコラボレーションは筑波大学が中心となって開発したプライバシー保護MLの一種です。機械学習の中間情報を共有する点はSplit Learningと似ていますが、以下の特徴があります。
- 各パーティは自分のデータを非可読な中間データへ非可逆変換し、各パーティから中間データをアグリゲーターへ集めます。アグリゲーターは各パーティから来た中間データを統合し学習を実行、生成した統合学習モデルが各パーティに返送されます。
- ニューラルネットワーク以外の機械学習モデルにも適用可能です。
- Federated Learningとくらべて計算コスト・通信コストが小さくなります。
差分プライバシー
差分プライバシーはプライバシー保護ML技術そのものではありませんが、機械学習分野で発展してきたプライバシー保護技術の一つです。機械学習で利用するための有用性を保ちながらデータにノイズを乗せて個人の特定が出来ないようにする手法です。その点では匿名加工技術の一種でもあります。
個人を特定できない情報として、元データを統計処理した結果が公開される場合があります。しかし、攻撃者が元データの一部を知っていると統計処理結果から個人のデータが逆算出来てしまう可能性があります。差分プライバシー手法では、統計処理の実施時に結果が大きく変わらない範囲でランダムノイズの付与や他のデータとの入れ替えなどを実施します。これにより、統計処理結果から個人のデータを特定することが難しくなります。
Warnat-Herresthal, S. et al. Swarm Learning for decentralized and confidential clinical machine learning. Nature 594, 265–270 (2021).
Gupta et al., Distributed learning of deep neural network over multiple agents, Journal of Network and Computer Applications, Vol 116, 2018, pp.1-8.
4.まとめ
本記事では安全性を確保してデータを連携・活用するために重要な技術について、プライバシー保護MLを中心に紹介しました。
今後、社会のデジタル化が進展する中で、企業や業界をまたぐデータの利活用はますます進んでいきます。今回ご紹介したテクノロジーはごく一部であり、他にもアクセス制御・認証やブロックチェーンの活用など、データの安全性担保のために多種多様な技術が存在します。用途に合わせて最新技術を組み入れてシステム化し、既存セキュリティ技術も合わせて全体として安全性を担保し、運用していく必要があります。
NTTデータでは、最新技術の活用とシステム開発・運用を含むトータルでのデータ流通・活用基盤を構築し、社会のデジタル化に貢献していきます。
