
目的を考慮した学習
機械学習とは、簡単に言うとデータから法則やパターンを学習するための技術です。機械学習には、教師つき学習や強化学習などの手法があります。
ビデオゲーム(※1)や囲碁(※2)の例では、ゲームのボタンを押すことや、石をどこに置くかといった判断を繰り返します。
このような逐次的な判断の学習方法の1つとして、上手な人の判断履歴を用いる方法があります。上手な人の判断履歴から、さまざまな状況での適切な判断を教師つき学習手法で学習します。ビデオゲームの例だと、上手な人の各場面での操作のデータから学習するイメージです(図1)
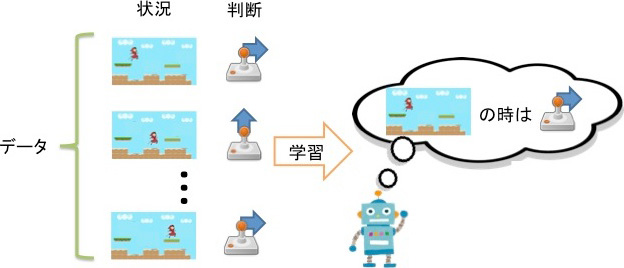
図 1:判断の履歴からの学習
別の方法として、強化学習による学習が考えられます。強化学習では、直接的な判断(=操作)の代わりに、目指すべき状態・目標や目的から、その目標に近づくような判断の仕方を学習します。ビデオゲームの例だと、得点を獲得することを目的として、得点を獲得できるような操作の仕方を学習します(図2)。
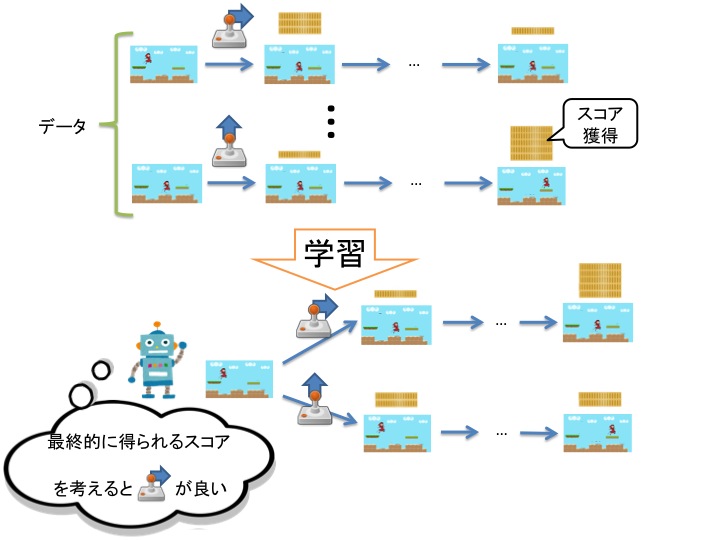
図 2:目的を考慮した学習
ただし、強化学習ではデータが不要というわけではありません。目標の他に、ある判断の結果としての状況の遷移や、目的を達成できたか(=得点が獲得できたか)といった履歴のデータも必要です。この履歴は必ずしも上手な人の履歴でなくても良いのです。どちらの方法が良いかは問題によりますが、上手な人のデータが得られない場合や、上手な人より更に良い判断を学習したい場合などは、強化学習の利用が考えられます。
試行錯誤しながら効率的に学習
強化学習では、他の機械学習と同様に、予め蓄えたデータから学習できます。しかし、実際に判断を下す状況において自律的に試行錯誤させながら(=データを集めながら)の学習もできます。
直接的に正解の判断を基にするのではなく、判断の結果として目的を達成しているかを基に学習するので、自律的に判断を下す状況でも学習できます。この方法では、それまで得られたデータや学習の途中結果を基に、試行錯誤(=データを集める)することで、効率的に学習を進められるという利点があります。
最初に挙げた囲碁やビデオゲームの例では、学習主体が自由に遊んだり対局したりできる環境を用意しています。その環境の中で学習主体は勝手に遊んだり、自分自身と対局したりして学習します。ただ、実社会への応用を考えると、現実で間違った行動をとると危険な場合もあります。この場合、シミュレーターを用意して、シミュレーション環境の中で学習させてから、現実で動かすことが考えられます。
2つの例は遊戯方面の応用ですが、交差点における交通流の最適化を目的とした信号制御や、ロボットの制御といった、より実用的な分野への応用も研究されています。複雑な意思決定の問題を扱え、自律的に学習を進められる強化学習は今後よりさまざまな問題に適用されていくでしょう。
http://www.nature.com/nature/journal/v518/n7540/abs/nature14236.html
http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html
