
- 目次
1.NTT DATAのソフトウェア開発における生成AI活用の全体像
近年、ソフトウェア開発で活用するLLM(大規模言語モデル)は、めざましい進化を遂げています。たとえば、2025年8月にOpenAI社が提供を開始したChatGPTの最新基盤モデル「GPT-5」は、最小限のプロンプトで高品質のコードを作成するなど、プログラミングの分野でも効果を発揮しています。
NTT DATAは、こうした生成AIの最新技術を活用し、お客さまの事業変革を推進するだけでなく、ソフトウェア開発の全工程にいち早く生成AIを適用し、開発プロセスの効率化、高度化、生産性向上を図ってきました。
当社は個々のタスクの生産性向上にとどまらず、さらなる高度化をめざし、開発プロセス自体の生産性向上、自動化の実現に向けても取り組みを進めています。
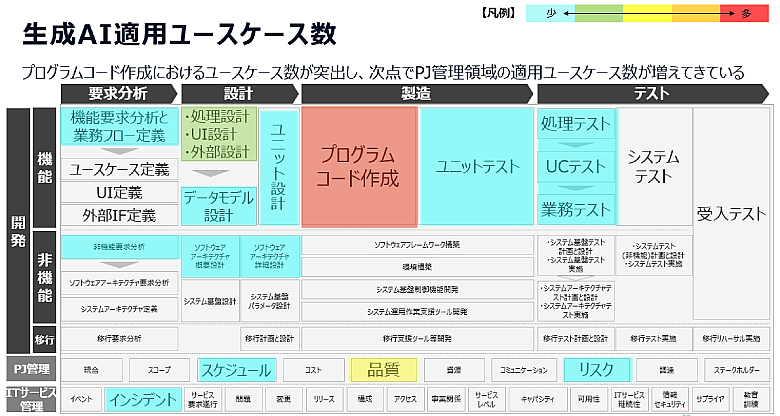
図1:AI技術部の生成AI適用ユースケース数
上記は、NTTデータグループ 技術革新統括本部 AI技術部が支援している生成AI適用のヒートマップです。プログラムコード作成が突出して適用が進んでいる状況に加え、NTT DATAが得意とするプロジェクトマネジメント、品質面での適用も増えています。
次章では、実際に当社で開発プロセスに生成AIを適用した事例をご説明します。
2.工程別に見る生成AI活用の効果と課題
2-1.ソースコードから設計情報の復元
まず、要件定義~設計工程における取り組みをご紹介します。
NTT DATAは、LLMを活用してソースコードを解析し、設計情報を復元するリバースエンジニアリングを実施しています。その取り組みの1つとして、レガシーな言語であるCOBOLのマイグレーションを進めています。
LLMは基本的にテキストを生成するため、図やテーブルを認識させるには、別のViewに変換できる言語で出力する工夫が必要です。こうした前段階を踏むことによって、人の目から見ても理解しやすい出力ができると捉えています。
リバースエンジニアリングを実施した結果として、生産性向上に関しては検証しきれていない部分があるため評価していませんが、品質については変換結果も良好で、ソースコードから設計情報を復元するのは可能だと考えています。
また、リバースエンジニアリングを実施した結果をRAG(Retrieval-Augmented Generation)に登録し、有識者以外でもシステム仕様が調べやすくなるなど、問い合わせ対応の迅速化は実現しています。今後、有識者とAIエージェントの対話による暗黙知の形式知化が可能になれば、これまで有識者にかかっていた負担の改善が期待されます。
2-2.テスト工程における生成AIの活用
続いて、テスト工程への適用例です。
現在、LLMを活用してテスト項目やテストシナリオ、テストスクリプトを出力させることが可能になっています。しかし、Excel形式の長大な図や表を入力すると、LLMが構造を正確に認識できず、出力結果に問題が生じるケースがあります。
この課題に対し、NTT DATAは複数のAIエージェントを組み合わせ、LLMが理解しやすい形式に前処理を行うことで、総合テスト項目表の生成を実現しました。
一方、AIエージェントを一つひとつ構築すると、どうしてもコストと時間がかかるという課題があります。
当初は既存のAIエージェントサービスの活用も検討しましたが、プロジェクトに特化した情報を十分に読み込ませるため、独自構築を進めています。将来的には、構築したAIエージェントを社内に展開することで、各プロジェクトの初期構築の負担を減らし、共通化によるさらなる効率化をめざします。
また、生産性向上については、ルールベースによる自動生成も効果的です。自動化技術と生成AIそれぞれの強みを踏まえ、うまく使い分けて実行することが重要です。
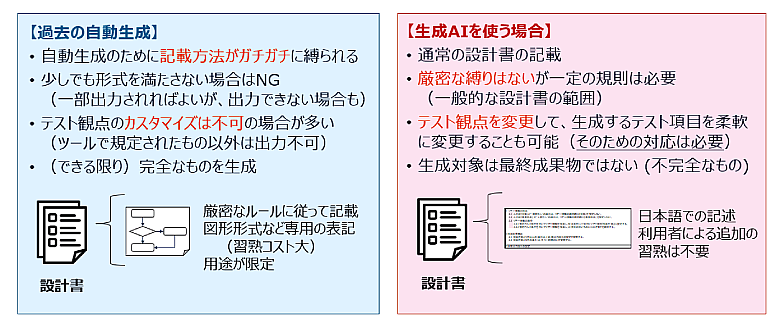
図2:旧来の自動化と生成AIの違い
2-3.プロジェクト管理・品質管理への応用
さらに、プロジェクト管理や品質管理への応用も進んでいます。
開発プロジェクトでは、進捗(しんちょく)情報や問題・課題、故障情報などを管理する必要があります。近年はチケット管理ツールの活用が進んでいますが、メンバーによってチケット記入時の表記ゆれや情報の欠落などが発生しやすいという課題があります。
そこで、生成AIによって入力チェックを含めた記入補助を行うことで、差し戻しにかかる作業を効率化しました。加えて、適切なチケット管理や運営も可能になるなど、導入によりさまざまな効果が確認されています。
さらに、成果物の品質管理やリスク評価・対策立案といった品質分析の領域でも、これまで人手によって行われていた作業負荷を軽減するため、AIエージェントを活用した効率化を試みました。
AIエージェントに品質分析を実施させるには、大量のバグ表をLLMが理解できる言語に変換する前処理が必要になりますが、この工程を踏むことでLLMとの連携が容易になり、真因分析や追加・再発防止の対策案などが自動出力できるようになりました。
このユースケースに限らず、生成AIが出力したものに関しては人の目によるチェックが必要です。しかし、従来の手作業で対処した場合と比較すると、大幅な効率化の実現が見込めます。
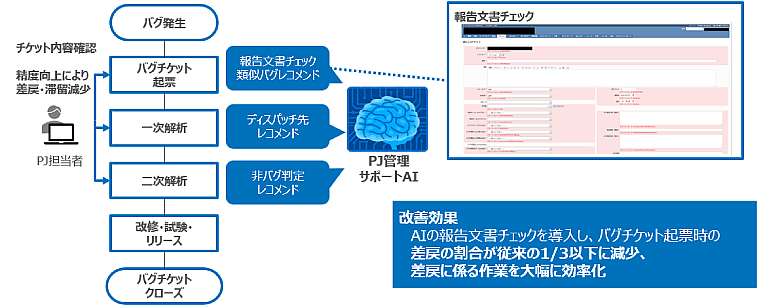
図3:PJ管理/保守工程のチケット管理
3.さらなる生産性向上をめざして
先述したように、NTT DATAは開発工程内の特定のタスクの効率化が図れており、生成AIの適用も徐々に進んでいます。しかし、従来のソフトウェア開発は、人が開発することをベースにプロセスを確立しているため、生成AIに最適化されたプロセスではありません。生成AIを最大限活用するには、既存プロセスとは異なる新しい開発プロセスを考えていく必要があるでしょう。
実際に従来のWモデルにおいて、要求分析から詳細設計までをLLMで効率化する検証を行いましたが、日本語では自然言語生成を繰り返す過程で精度が高まりにくいという課題が見られました。
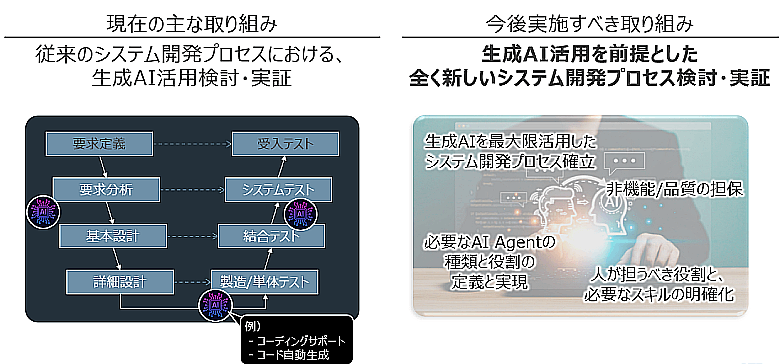
図4:生成AI時代のあるべきシステム開発プロセス
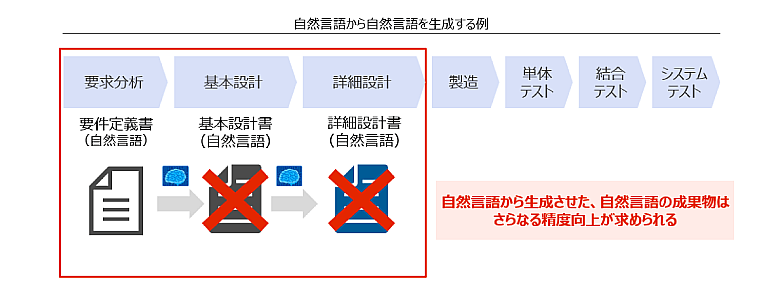
図5:自然言語(要件定義書)から自然言語(基本設計書、詳細設計書)を生成する例
生成AIを最大限活用する場合は、設計を段階的に詳細化していくのではなく、別のプロセスの適用も視野に入れることが重要です。たとえばテスト駆動型の考え方を取り入れ、要件定義の段階から要求分析の記載の仕方を工夫することにより、粒度によってはソースコードを出力できます。LLMは比較的ソースコードを理解しやすいという特徴があります。単体テスト項目およびテストコードをセットで作成し、動作確認できているシステムから設計情報を復元することで、自然言語から自然言語を繰り返して出力した設計情報と比較して、品質が向上すると考えています。
さらに、有識者が模範成果物のフォーマットやコーディング例をLLMに読み込ませることで、有識者が作成するものと同様の形式を出力できるのではないかと考え、実現に向けてプロジェクトに適用中です。
ほかにも、要求分析の段階で「バイブコーディング」を活用した場合にソフトウェア開発にどのような影響があるのかを検証しました。バイブコーディングとは、仕様レベルの要望を自然言語で指示するだけで、生成AIが構造を理解し、迅速にプロトタイプを構築する手法のことをいいます。
バイブコーディングは、プロトタイプの作成において非常に強力なツールである一方、エンタープライズ領域のソースコードの出力においてはそのまま使用できるレベルではありません。品質確保の方法やチェックすべき指標の体系化が今後の課題だと捉えています。
4.おわりに
ソフトウェア開発において生成AIの適用に伴う課題はあるものの、生成AIはエンタープライズの領域において非常に強力なツールになります。しかし、1つの会社での対応には限界があり、社会および業界全体でどのように活用していくかを検討することが重要です。
NTT DATAは、プロジェクト全体での効率化の観点からソフトウェア開発への生成AIの活用について先進的な取り組みを進め、技術革新による新たな価値創出に挑戦しています。
当社は生成AIと人との協働による新しい開発スタイルを追求し、これからも社会への価値提供に貢献してまいります。
※本記事は、2025年7月3日に開催された「開発生産性カンファレンス2025」での講演をもとに構成しています。


生成AI(Generative AI)についてはこちら:
https://www.nttdata.com/jp/ja/services/generative-ai/
あわせて読みたい: