
学習データの必要性
自然言語処理(natural language processing)の技術を利用して実問題を解決するアプローチとして、機械学習における教師あり学習(supervised learning)や教師なし学習(unsupervised learning)、半教師あり学習(semi-supervised learning)、Few-shot学習など様々なアプローチが存在します。しかし、実際にはビジネス要件に合わせた判断の結果、多くの場合はタスクの専門性および多様性に対応しやすい「教師あり学習」によるアプローチがとられます。例えば、製品に対して口コミのセンチメント(※)を分析するためには、文書分類(document classification)技術が使われますし、電子カルテから副作用に関する記述を抽出する場合は、主に情報抽出(information extraction)技術が利用されます。多言語間の自動翻訳なら、テキスト生成(text generation)技術の出番となります。
いずれの技術でも、準備した学習データの量および品質は、最終的な精度に直結します。テキストデータはインターネット上に大量に存在します。しかし、ウィキペディアやウェブサイト、SNSなどから大量にテキスト情報を入手できたとしても、学習データとしての可用性は非常に低いです。自然言語処理においてテキストデータを学習データとして活用するためには、テキスト情報に対して、解決したい問題に対する「正解」情報を付与する必要があるからです。上記の事例では、一件一件の口コミに対してポジティブ・ネガティブなどの極性情報を付与したり、電子カルテに副作用表現がどのフレーズに該当するかの情報を与えたりする必要がありますし、自動翻訳の学習のためには多言語の対訳文書の準備が必須となります。
また、同じジャンルの技術でも適用する課題や業務によって、折角整備した学習データが適用できない場合も多々あります。例えば、同じセンチメント分析でも、口コミデータとサポートセンターのデータを比較するとニュアンスがかなり異なり、高い精度の達成のためには、それぞれのテキストデータに対して学習データを準備する必要があります。
商品や市場に対する消費者側の感想や感情のこと
学習データ作成の一般手法
学習データの作成のためには、手動で「正解」情報を付ける作業が一般的で「アノテーション」と呼ばれています。自然言語処理における標準的なアノテーション工程では、最初にタスクに応じたラベルの定義や、判断が難しい場合の正解付与基準などを含むガイドラインを作成します。次に、ガイドラインに従って、作業者(アノテーター)がアノテーションを実施します。タスクの難易度によっては、関連業務有識者に依頼する必要があります。また、品質を保つため、多人数でアノテーションを行い、その結果を整合することも必要となります。しかしながら、実案件においてアノテーション工程でかけられるコストは限られているため、少量しか学習データを準備できないケースもあり、学習データ作成コストが精度の良いモデルを学習させることの障害になっています。
手動作業のコストを軽減するために、アクティブラーニング(active learning)がよく利用されています。この仕組みでは、アノテーション対象を大量なデータ全体ではなく、「モデルの学習に有効なデータ」を自動選定してアノテーションを実施します。対象を選定する際に、既存の学習済みのモデルを使って、モデルの自動判断が曖昧なデータだけをピックアップする手法です。
ただし、上記のアプローチは「正解」が付いていないデータ(いわゆるラベルなしデータ)が大量にあることを前提としています。対象業務のラベルなしデータ自体の入手が困難な場合はこのようなアプローチをとることができません。
データ拡張の技術開発
そこで、当社は少量の学習データを最大限に活用するために、データ拡張の技術を開発しています。データ拡張とは、既存の少量学習データを様々な手法を用いて水増しし、学習データとして利用することで高精度なモデルを作成するアプローチです。
画像処理の分野では、画像はノイズをある程度加えても画像全体の意味がほとんど変わらないという特性を利用し、画像の拡大、縮小、回転、ノイズ付与などによって疑似データを自動生成するデータ拡張手法が一般的に応用されています。(図1)
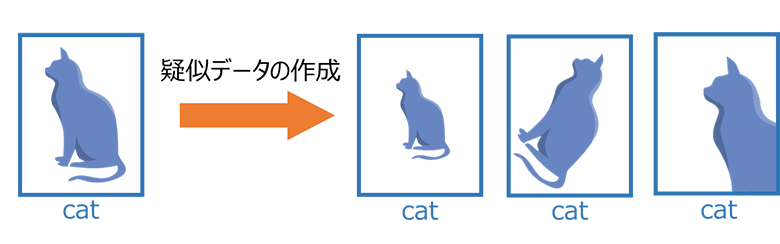
図1:画像処理におけるデータ拡張
一方、言語データにおけるデータ拡張は、単語一つを入れ替えるだけでも意味が逆転するケースもあり、画像より挑戦的なテーマとなります。(図2)
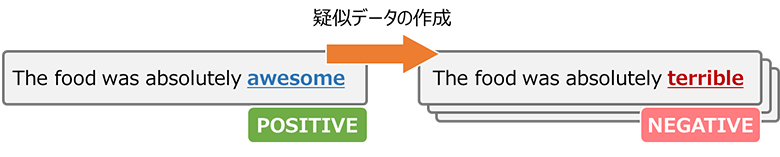
図2:自然言語処理におけるデータ拡張
自然言語処理のタスクの種類によってデータ拡張の難易度も異なってきます。例えば、文書分類系の学習データには、基本的に一文書に対して、一つのラベルが付けられています。文書全体に対して疑似データを自動作成する際に文書の意味を維持できれば、構文や出現する単語が変わっても問題が起こりません。例としては、ネガティブな口コミ記事を他の言語に翻訳してから、元の言語に逆翻訳する手法によって、似た意図のネガティブな口コミ疑似データを生成することができます。(図3)
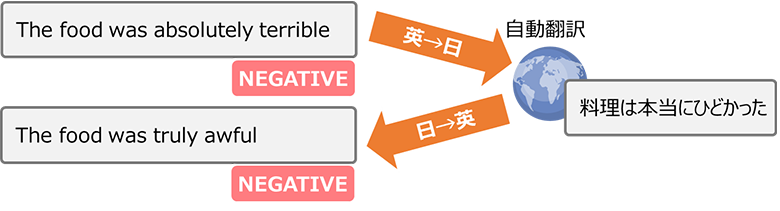
図3:文書分類系データ拡張
同じような手法を薬品の副作用表現抽出の学習データに適用すると、作成した疑似データ中のどの部分が副作用を表すかという情報が完全に失われてしまいます。(図4)当社は、このような難易度の高い、情報抽出系のタスクを中心として研究開発を行っています。
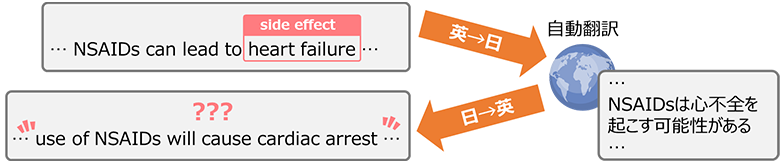
図4:情報抽出系データ拡張
データ拡張の技術開発によって、コストの高いアノテーション作業を実施せずに、僅かな学習データから高性能なモデルを構築できるようになってきました。当社の検証では、ニュース記事データから組織名の抽出を行うタスクや、医療データから症状名、薬名を抽出するタスクでは、最大10%程度の精度向上が確認できています。今後は、学習に効果的な情報の自動選定や半自動アプローチとの融合など、更なる高度化したデータ拡張技術によって、自然言語を活用したい方が学習データ不足問題に悩むことが無くなるよう、低コストかつ効果的に学習データを活用できる手法の開発を目指しています。
