
- 目次
中央集権型の限界と「分散型」へのシフト
NTTドコモでは長年、社内のデータ活用を広めるべく、全社データを一か所に集める中央集権的な取り組みを推進してきました。しかし、デジタルマーケティングを通じて顧客一人一人に最適な体験を届けるミッションを担うマーケティングイノベーション部においては、既存の基盤だけでは解決できない課題が浮上していました。
生田 氏は、当時の状況を次のように振り返ります。「私たちが目指したのは、日本最大級の顧客データを駆使したパーソナライズ体験の創出です。そのためには関連子会社と密なデータ連携が不可欠ですが、中央集権的なデータプロバイダーとしての役割と、私たちのビジネスニーズが組織構造として一致しきれていない面がありました」
この組織とシステムのミスマッチを解消するために打ち出されたのが、現場組織が自ら基盤を持ち、自律的にデータを管理・共有する「分散型(データメッシュ)」戦略です。NTTデータはこの構想に賛同し、単なる基盤構築に留まらない、ビジネス成果の創出に向けた高度な技術支援を開始しました。
課題1:PB級データの壁と「再共有」に伴うコスト問題
分散型へのシフトにおいて最初に直面した最大の障壁は、当時提供されていた機能では、共有データをさらに別組織へ展開する際に追加設計が必要となるという、技術的制約でした。中央のデータ基盤(親)から提供されたデータを、さらにその先のグループ会社(孫)へ共有するためには、中間にあるNTTドコモの基盤で一度データを「実体化(テーブル化)」して保持し直す必要があります。
しかし、NTTドコモが扱うのはPB級の巨大データであり、愚直にすべてのデータをコピーして実体化すれば、膨大なコンピューティング(仮想ウェアハウス(WH))コストとストレージコストが発生し、プロジェクトの予算を容易に超過してしまいます。「データによって必要な期間も更新頻度も異なります。これらを一律に処理するのではなく、いかにインタラクティブにコントロールし、コストを最小化するかが最重要課題でした」と生田 氏は語ります。
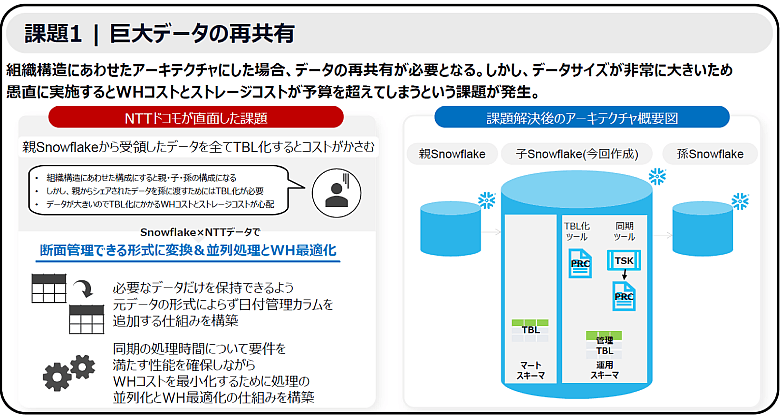
図1:課題1(巨大データの再共有)
解決策1:プロシージャとWH最適化によるコスト最小化の実装
この難題に対し、NTTデータは「最小限のデータ保持で最大の共有効果を生む」ための仕組みを構築しました。
まず、データ共有時に必須となる「期間」の絞り込みを可能にするため、元データに日付型カラムが存在しない場合でも、実体化のプロセスで動的に日付管理カラムを追加するパイプラインを作成しました。これにより、ビジネス要件に基づいた必要な期間のデータだけを抽出して保持することが可能になりました。
さらに、運用負荷とコストの最適化を両立させるため、処理の並列化と「WH(ウェアハウス)最適化」を導入しました。「ドコモさんのデータは、数百レコードのものから1億レコードを超えるものまで多種多様です。小さなデータに巨大なリソースを使えば無駄が生じ、逆であれば処理が終わりません。そこで、テーブルのサイズごとに最適なWHサイズを自動選択する独自の管理テーブルを構築しました」と田川は説明します。これにより、運用者は設定を登録するだけで、システムが自動でリソースをコントロールし、安定した同期処理を低コストで実行できる環境を実現しました。
課題2:グループ会社連携における厳格な「提供データ管理」
技術的な課題と並行して重要だったのが、法規制への対応です。グループ会社間であっても、データを社外に共有する以上、個人情報保護法を順守した厳格な管理が求められます。具体的には、「誰の、どのデータを、いつ、どの会社に共有したか」という記録を、法律で定められた期間、確実に保存しなければなりません。
また、NTTドコモ特有の事情として、同一のグループ会社に対して「ドコモからの業務委託」として提供するデータと、「その会社独自の事業」のために提供する第三者提供データが混在しているという複雑さがありました。これらを同一の領域で管理すれば、取り違えによる法違反のリスクが生じます。
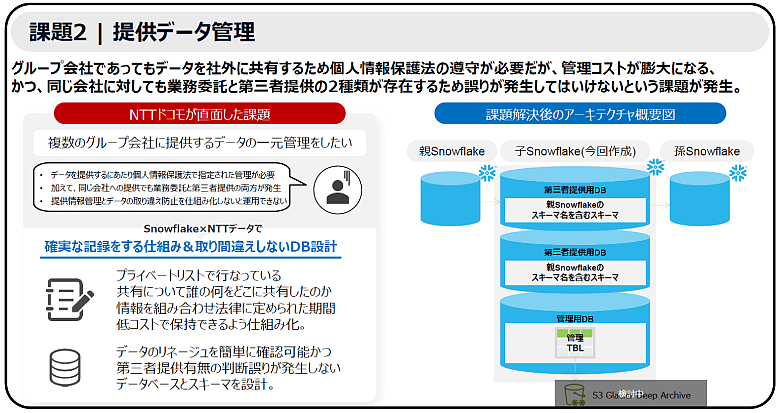
図2:課題2(提供データ管理)
解決策2:法令順守と誤共有防止を両立するデータベース設計
NTTデータは、ITコンサルの立場からこのガバナンス設計を支援しました。解決の鍵となったのは、徹底した「物理的分離」と「自動記録」の仕組みです。
まず、共有状況の可視化については、人手を介さず自動で同期情報を集約する管理テーブルを作成しました。業務に必要な最新データのみを各社に共有しつつ、法令対応のための履歴データは別領域に自動蓄積することで、運用効率とガバナンスの両立を図りました。
さらに、データの取り違えを根本から防ぐため、「業務委託用DB」と「第三者提供用DB」を明示的に分けたアーキテクチャを設計しました。「権限制御だけでなく、受け手となる子会社のエンジニアが迷わないよう、スキーマ名にも親基盤の名称を含めるなど、リネージュ(データの系譜)を一目で確認できる工夫を凝らしました」と田川は述べます。
成果:技術的制約を乗り越えた信頼のパートナーシップ
このプロジェクトの過程では、大きな試行錯誤もありました。当初、Snowflakeの標準機能である「チェンジトラッキング」を用いた更新追従を目指していましたが、開発後半でNTTドコモ特有のデータ仕様に適合しないことが判明しました。2~3か月分の実装を破棄し、作り直すという事態に陥りました。
この窮地を救ったのは、両社の深い信頼関係でした。生田 氏は言います。「田川さんは単なるベンダーではなく、信頼できる技術者でした。NTTデータのエンジニアが書くコードは非常に洗練されており、エラー通知やリカバリーの仕組みも最初から組み込まれていました。彼らの高いスキルを参考にすることで、私自身も快適に内製開発を進められました」
PB級の巨大データを扱いながらも、コストを抑えた安全な分散型データ流通基盤が完成しました。現在ではグループ6社へのデータ連携が安定稼働しており、現場主導のデータ活用が加速しています。
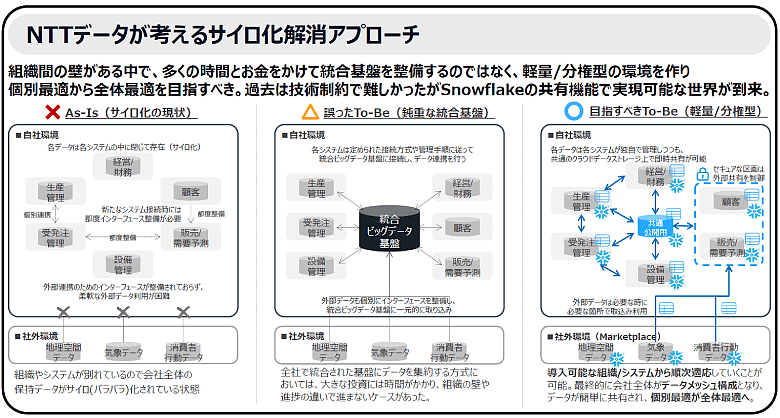
図3:NTTデータが考えるサイロ化解消アプローチ
展望:データメッシュの先にある「One NTT」の未来
今回の取り組みにより、NTTドコモにおけるデータシェアリングの基盤は整いました。今後は、専門知識を持たない社員でも自然言語でデータを扱えるようLLM(大規模言語モデル)を活用することや、Snowflakeの最新機能である「Resharing(再共有)」の適用によるさらなるコスト削減を視野に入れています。
NTTデータが考える「サイロ化解消アプローチ」は、重厚長大な統合基盤を数年かけて作るのではなく、成果の見える現場から軽量な分散型環境を構築し、それらをつないで全体最適を目指すものです。この知見を凝縮したデータ分析ソリューション群「Tirofog®(ティロフォグ)」を通じ、NTTデータは戦略策定から実装、現場の定着化までを一気通貫で支援しています。
「One NTT」として、持ち株会社やグループ各社が持つデータをセキュアに共有し合うデータメッシュな世界を実現し、日本企業のデータ活用を次のステージへ引き上げる。両社の挑戦は、データ活用の新たなスタンダードを築こうとしています。
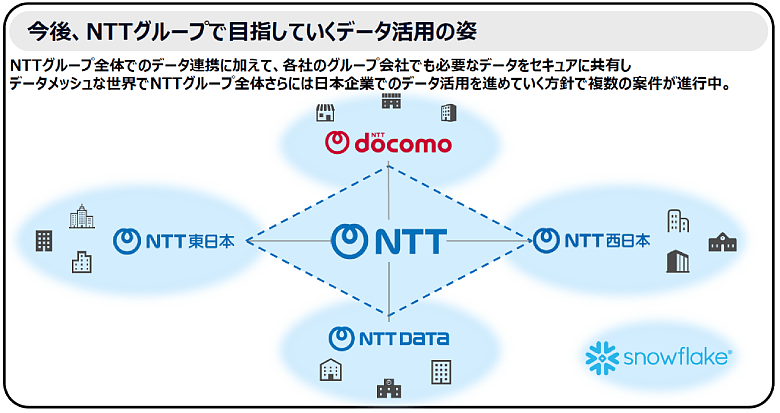
図4:今後、NTTグループで目指していくデータ活用の姿

Snowflakeプロダクトページについてはこちら:
https://www.nttdata.com/jp/ja/lineup/snowflake/
あわせて読みたい: