
- 目次
1.企業バリューチェーン(SCMやCRMなど)におけるデータ分析の現状
企業において、データ分析はどのように利用されているのでしょうか?「企業IT動向調査報告書2025」(発行:一般社団法人日本情報システム・ユーザー協会)によると、「データは無形の“資産”であり、データを十分に活用できるかできないかによって、企業の競争力が左右される局面は増えている。」とされています。
また、同文献にて業務プロセスでの活用(80%)に加え、新サービスの創出(50%)にも利用されており、企業活動に定着してきているといっても過言ではないと思われ、当社においても、生成AI/機械学習/BIがさまざまな企業活動において利用されており、得意な用途も異なっています。
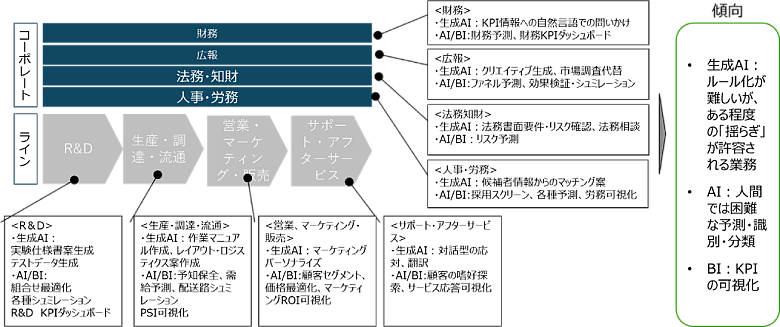
図1:企業のバリューチェーンにおけるデータ活用
2.生成AIとデータ活用への応用
生成AI(Generative AI)の進化により、自然言語を用いたデータ分析(GenBI)の普及が進みつつあります。
GenBIはデータ分析の工程によって使いどころは異なりますが、従来は専門知識を要したデータベース操作や分析業務を、自然言語での質問や指示によって自動的に実行可能とする点に特徴があります。これにより、エンジニア以外のビジネスユーザーでも容易にデータ活用できるようになります。
BI(※1)は大きく、定型分析と自由分析に分別されます。定型分析は、レポート形式であらかじめ決まった指標や集計結果を表示するもので再現性が高く、業務プロセスに組み込みやすいという特徴があります。
自由分析は、利用者が目的に応じてデータを自在に組み合わせ、探索的に洞察を得る分析であり、仮説検証や新たな気づきの発見に適しています。
GenBIは確率的に答えを生成するだけでなく、自然言語で探索できるため、従来のBIにおける自由分析として利用可能です。
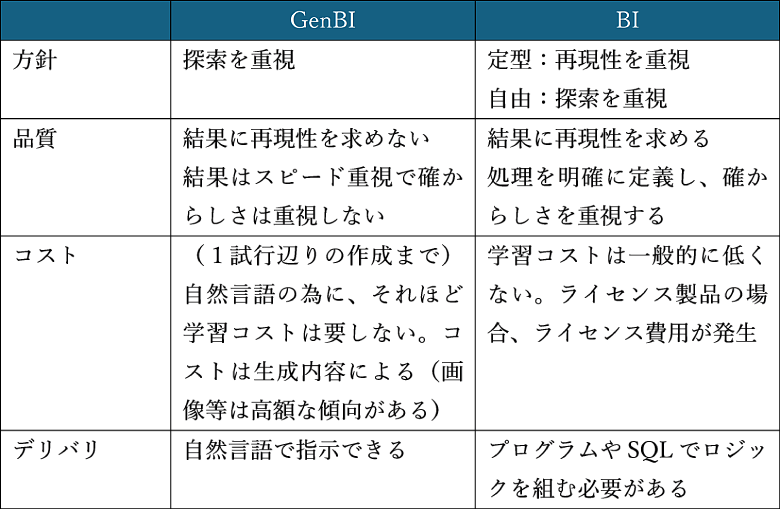
表1:GenBIとBIの特徴比較
本稿におけるBIは、ダッシュボードによる可視化に限らず、探索的分析や仮説検証を含む広義のビジネスアナリティクスを指します。
3.GenBI活用事例と実装の方向性(例:サプライチェーンマネジメントSCM)
このような特性を踏まえ、企業のどういったバリューチェーンでGenBIが活用できるか?本稿では、SCMを例に考えていきます。
多くの企業では、特性上、SCM領域の分析は実績・予測系における統計的・計量的手法が主流です。具体的には、サプライチェーンの可視化、レジリエンス評価、需要・供給計画最適化などが重点領域。これらに対して、現在はダッシュボードを設計・構築してPSIデータ等の定型的な可視化が行われています。定型では賄えない個別の分析ニーズや新たなインサイト導出はBIの自由分析で行われていますが、この精度はデータ、ツールの制約やユーザースキルに依存する部分が大きいと言えます。
ここに自然言語による対話型分析が加わると、よりTPOを踏まえた直観的な課題仮説やひらめきをデータ分析へと落とし込むことが可能となり、さらに、その分析を実現できるユーザの数も飛躍的に増やすことが可能になります。
在庫管理・需要予測・物流最適化など膨大なデータを扱う領域こそ、自然言語による対話型分析の価値が大きく、生成AIを用いたレポート生成や異常検知、サプライヤーリスク分析などの導入が進めば、意思決定スピードと精度が大幅に向上することが期待できるでしょう。

表2:SCM領域における生成AI・GenBIの応用例
4.自然言語での問い合わせにおける留意点
自然言語でのデータ分析においては、データ(DWH)をいかにLLMが理解するかが重要となります。LLMはデータ(DWH)にクエリを投げる際、意味解析・スキーマ理解・SQL構文生成という3段階から成り、プロンプト設計や組織固有の用語辞書、システムのメタデータ(※2)を活用することで精度を高めることができます。
近年では、システムメタデータを自動生成することも可能ですが、補助的な意味合いが強く、自然言語におけるデータ分析を構築、準備する際には、データマネジメントについても並行して検討することが望ましいでしょう。
また、自然言語から出力された結果については、何をもって正とするのかという評価基準も必要です。これは既存の業務においても言えることですが、自然言語による分析では余計に基準が見えづらくなるためです。
データそのものではなく、テーブルの定義、カラムの意味、値の粒度、データの更新頻度など、データのためのデータを指します。生成AIが自然言語から正確に解釈するために必要で、特に企業のバリューチェーンで複数のシステムから異なるドメインのデータを利用する場合に特に有効となります。
5.自然言語によるデータ分析(Text to SQL)の活用
前章までで、生成AIを用いたGenBIがデータ活用の裾野を広げること、またその前提としてメタデータや用語辞書の整備が重要であることを整理しました。本章では、その中核技術の一つであるText to SQLを中心に、データ収集・データ加工・データ可視化/インサイト発見という一連のプロセスの中でどのように活用できるのかをまとめていきます。
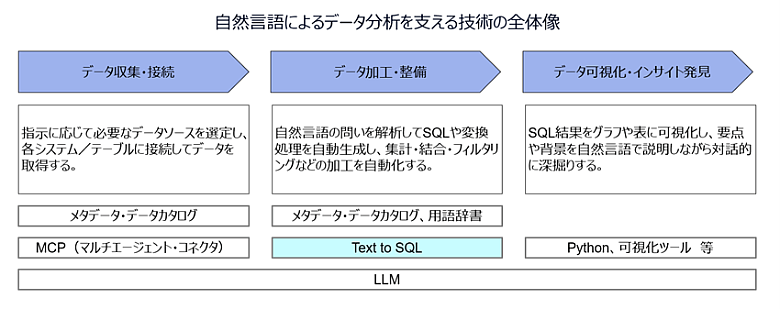
図2:自然言語によるデータ分析を支える技術の全体像
Text to SQLは単独の技術ではなく「自然言語インターフェースを通じて、データ収集から可視化までをつなぐ中核コンポーネント」と位置づけることができます。自然言語の質問を解析してSQL文を自動生成し、データベースから回答を導くText to SQLによって、ユーザーは「今週の在庫回転率が低い倉庫を、上位5件教えて」「主要サプライヤー別に、過去3ヶ月の納期遅延率を比較して」といった問いかけだけで、必要な集計・結合・グルーピングを含むSQLを自動生成し、分析結果を得ることが可能です。
Text to SQLの内部処理は、大きく以下の3段階で整理できます。
(1)意味解析(自然言語理解)
- ユーザーの質問から、「期間」「対象指標」「集計粒度」「条件」などの要素を抽出。
- 例:「今週の在庫回転率」→期間:当週、指標:在庫回転率、粒度:倉庫別、条件:在庫回転率が低い順。
(2)スキーマ理解(業務用語とデータ構造の対応付け)
- 業務用語(例:出荷遅延、欠品、主要サプライヤー)を、実際のテーブル名・カラム名・コード値にマッピングします。
- この際、前章で述べたような組織固有の用語辞書やメタデータが重要な役割を果たします。
(3)SQL構文生成と最適化
- テーブル結合、集計関数、フィルタ条件、並び順などを含むSQL文を自動生成します。
- 必要に応じて、問い合わせを分割し、事前集計テーブルを利用するなど、パフォーマンスや運用上の制約を踏まえた最適化も行います。
この3段階を高精度に機能させるためには、LLM単体の性能だけでなく、次のような工夫が不可欠です。
(1)プロンプト設計
業務シナリオに応じて、「どのような前提でSQLを生成すべきか」「どのような形式で返すべきか」をあらかじめ指示する必要があります。
(2)用語辞書・シノニム管理
「売上」「販売額」「売上金額」など、多様な表現を同一指標として解釈できるようにしておきます。
(3)ガバナンス・権限管理との連携
ユーザーの権限に応じて参照可能なテーブルやカラムを制御し、不必要な個人情報へのアクセスや誤った集計を防ぐことも大切です。
Text to SQLによって生成されたクエリは、可視化ツールやダッシュボードと連携させることで、自然言語を起点とした可視化・インサイト発見のサイクルを実現できます。具体的には次のような利用イメージが考えられるでしょう。
(1)自然言語でのダッシュボード操作
「在庫回転率ダッシュボードで、期間を直近3ヶ月に変更して」「倉庫別ではなく、エリア別に集計し直して」といった指示をもとに内部でクエリを書き換え、グラフを再描画。
(2)対話的な深堀り分析
ユーザーが結果を見ながら「なぜこの倉庫だけ回転率が低いのか?」「サプライヤー別に見た場合はどうか?」と追加質問を行うと、その都度Text to SQLが新たなクエリを生成し、段階的な分析を支援。
このように、Text to SQLは単に「SQLを書く手間を省く」ための技術ではなく、
- ビジネスユーザーが自ら問いを立て、
- その場で回答を得て、
- さらに深掘りしていく
という対話型の分析プロセスを支える基盤と言えるのではないでしょうか。
6.今後の展望:対話的データ分析への進化
自然言語分析は、単なるSQL生成に留まらず、「対話的データ分析」へと進化していくと予想されます。ユーザーの質問意図を理解し、段階的に補足質問を行うことで、分析結果の精度と納得性を高める仕組みが求められていくでしょう。また、外部知識ベースやシミュレーションエンジンとの統合により、SCM領域の意思決定を支援するAIエージェントの実用化が進み、これによりビジネスユーザーが自然言語でサプライチェーン全体を探索・最適化できる未来が現実のものとなります。
生成AIによるレポート生成は、専門的な分析業務を誰もが扱える形に変え、サプライチェーン全体の意思決定スピードを飛躍的に高めます。企業固有のデータ構造に適応し、対話型で洞察を提供するAI分析プラットフォームの開発が鍵となるのです。
一方で、自然言語での分析においても、どのようなデータを結合するか、適切に事前集計するかといったデータエンジニアリング観点での工夫、分析目的に応じたKPIや指標の設定といったデータサイエンス観点での工夫など、人間自身がデータサイエンスの知見をもっておくことが必要です。
こうした取り組みを実現するためには、技術・データ・人材を一体で推進することが重要となります。
NTT DATAは、生成AI、GenBI等の全社構想、戦略からAP実装、インフラ構築、メタデータ付与におけるデータマネジメント等、さらにはデータサイエンスの人材育成まで、幅広い支援が可能です。ご相談があれば、ぜひお気軽にお問い合わせください。

あわせて読みたい: