
1.企業の生成AI活用が直面する「データの壁」
ChatGPTの登場から早3年、生成AIは私たちの生活やビジネスに急速に浸透してきました。日常的な情報収集や文章作成のアシスタントとしてはもちろん、ソフトウェア開発でのコード生成支援、カスタマーサポートの自動応答、マーケティングの広告文作成など、活用範囲は広がり続けています。
こうした活用が進む一方で、よりビジネス価値の高い意思決定に生成AIを生かそうとすると、壁にぶつかる企業が少なくありません。顧客の購買履歴や製品の設計図、業務ログ、社内ナレッジなど、競争力の源泉となる独自データを生成AIに読み込ませたい。しかし、パブリッククラウド上のサービスにそれらを送信することは、社内ポリシーやコンプライアンス上、許可されていない。送信したデータを日本国外で処理することは法令・ガイドライン上認められていない。これが、企業の生成AI活用が直面する「データの壁」です。
そこで注目されているのが「プライベートAI」です。プライベートAIとは、自社が管理する環境で生成AIを動かし、学習や推論に用いるデータの所在と扱いを自社でコントロールできる仕組みを指します。データ主権とセキュリティを担保することで、安心・安全に生成AIを活用する選択肢として、導入を検討する企業が増えています。
かつては、モデルの中身が非公開なOpenAI社のGPTシリーズやGoogle社のGeminiなどのプロプライエタリモデル(※1)と比較して、モデルの中身が公開されているオープンウェイトモデル(※2)の性能は見劣りすると考えられてきました。しかし、Meta社のLlama 4、DeepSeek社のR1、OpenAI社のgpt-oss-120bといった高性能なオープンウェイトモデルの登場により、その性能差は着実に縮まりつつあります。
また、NTT社が開発した高い日本語処理能力を持つ大規模言語モデル「tsuzumi 2」をはじめ、比較的軽量なモデルも増えてきており、大規模なインフラを準備しなくても生成AIを利用できるようになりつつあります。高度な推論を要するタスクにおいては、依然としてプロプライエタリモデルの最上位クラスが優位な場面もありますが、一般的な業務タスクではオープンウェイトモデルでも十分に対応可能な水準に達しています。結果として、プライベートAIの導入は、より現実的な選択肢となっています。
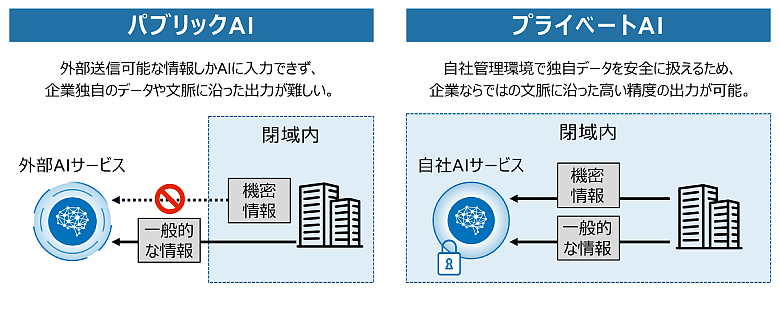
図1:パブリックAIとプライベートAI
提供元がモデルの仕様や学習済みパラメータ(重み)を公開しておらず、提供元へWeb API等でアクセスして利用できるモデル
提供元が学習済みの重みを公開し、利用者がダウンロードして利用・カスタマイズできるモデル
2.プライベートAIが選ばれる3つの理由
プライベートAIの活用が特に期待されるユースケースには、大きく分けて3つの特徴があります。
1つ目は、顧客データや財務情報、知的財産などの機密情報を扱う業務です。購買履歴や行動ログ、設計情報、契約書類といった独自データの利活用ニーズが高まっていますが、これらを外部サービスに送信することには、情報漏えいやコンプライアンス違反のリスクが伴います。企業内部の閉じたインフラ上で処理できるプライベートAIであれば、データ主権とセキュリティを確保しながら、高度な分析や意思決定に活用できます。
2つ目は、長期的かつ安定した運用が求められる業務です。クラウド型の生成AIのモデル更新やAPI仕様変更により、昨日まで正しく動いていたプロンプトが、ある日を境に期待通りの結果を返さなくなることがあります。品質管理やリスク評価、問い合わせ対応など、同じ入力に対して一定水準の出力が求められるシステムでは、こうした変化は大きなリスクになります。プライベートAIであれば、利用するモデルのバージョンや更新タイミングを自社で管理できるため、業務要件に合わせた運用が行いやすくなります。
3つ目は、コストコントロールが重要な業務です。多くの生成AIサービスは従量課金が中心で、利用が広がるほど費用も増加し、想定を超えた支出が発生するリスクがあります。特に、近年のReasoningモデル(時間をかけて深く思考・推論するモデル)やAIエージェント(自律的に計画を立ててタスクを実行する仕組み)を利用する場合、1つのタスクで消費するトークン(※3)数が従来比で数十倍に跳ね上がるケースもあり、その増加傾向は顕著です。つまり、同じ仕事でも、AI側が裏で何度も思考ややりとりを繰り返すため、結果として利用料が跳ね上がるケースが増えているのです。一方、プライベートAIでは必要なインフラやライセンス、運用体制をあらかじめ設計することで、中長期のコストを計画的にコントロールできます。生成AIを業務へ組み込むほど、このメリットは大きくなります。
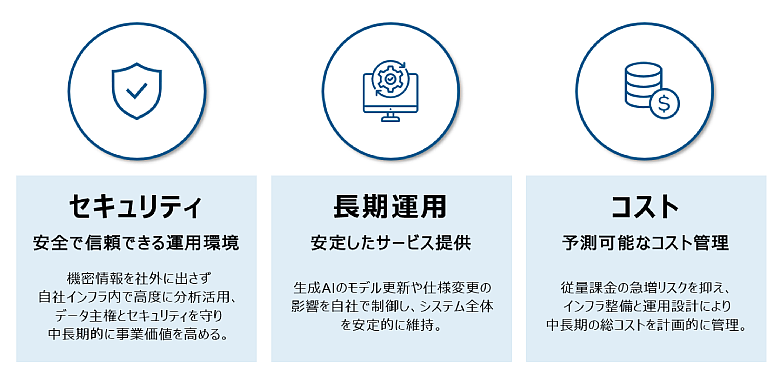
図2:プライベートAIが提供する3つの価値
AIが文章を細かく区切って処理する最小単位
3.プライベートAI導入のコツ
プライベートAIを効果的に導入するには、「業務」「アプリ」「インフラ」の3要素を意識することが重要です。
現場業務を棚卸しすると、つい「あらゆる業務をAIで」と考えがちですが、その業務をルールベースやRPAで代替できないか、パブリックなAIサービスで十分ではないか検討が必要です。単純な自動化が難しく、量があり、社外・国外へ送信できないデータが含まれる、つまり競争力の源泉となる独自データを扱う業務が最もプライベートAIの導入に適しています。また、AIに読み取らせるデータの整備も欠かせません。図や表が含まれたPDFファイルをAIが理解しやすいテキスト形式に変換したり、定期的に古い情報を削除し、新しい情報に更新するフローを整備したりすることで、推論精度の維持と業務への適応力が高まります。この業務設計の段階で、「どの業務をどこまでAI化するか(AIをベースにした業務に変革するか)」「必要なデータがそろっているか」を見極めることが、後続のステップに大きく影響します。
AIを用いたアプリケーションについて、文書検索や要約といった機能面はもちろん、利用ログの取得やユーザー権限管理などの運用面が実現できるかも考慮して選定する必要があります。使用するAIモデルについても単純な精度だけでなく、目的のタスクに対して適切に実行できるか、画像や音声などの入力に対応しているか、応答速度は十分かなど総合的に評価する必要があります。AIモデルを自社用にカスタマイズ(ファインチューニング)することも選択肢となりえますが、計算リソースや学習データの整備などに大きなコストがかかるため、目標を定めた上で実施することが必要です。
そして最後に「インフラ設計」です。プライベートAIを安定稼働させるには、GPU・サーバ構成の適切な選定が鍵となります。想定ユーザー数や同時接続数、アプリのピーク時に必要となる負荷を見積もり、必要に応じてGPUやサーバを増設できるスケーラブルな設計にしておくことで、利用拡大時も安定した運用が可能になります。また、実際にサーバを設置する場所も重要な検討事項です。GPUサーバは一般的なCPUサーバ(いわゆるIAサーバ)と比べて消費電力と発熱が大きいため、設置先の電源容量や空調能力を事前に確認する必要があります。自社のオンプレミス環境、パートナーのデータセンター、プライベートクラウドといった候補を比較し、データの機密性、運用体制、コスト、災害対策が問題ないか総合的に評価します。既存サーバルームでは電力やラックスペースが不足するケースも多く、設備増強の要否を含めて検討することが求められます。
「業務」「アプリ」「インフラ」の3要素は互いに密接に関係しています。高性能なモデルを選べばサーバ要件が上がり、結果として設置場所の選択肢が狭まることもありますし、逆に設置場所の制約からサーバスペックに上限がある場合は、その範囲で動作するモデルやアプリケーションを選び直す必要があります。プライベートAI導入を成功させるには、個々の要素を個別に最適化するのではなく、業務、アプリ、インフラを一体で設計する視点が重要です。
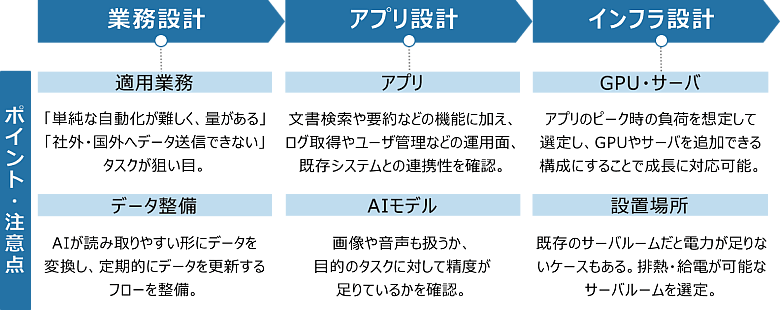
図3:プライベートAIの設計フロー
4.NTTデータが提供するプライベートAIソリューション
NTTデータは、プライベートAIの導入検討からアーキテクチャ設計、インフラ構築、アプリケーション実装・運用までを一体で支援するソリューションを展開しています。世界トップクラスのシェアを持つ自社データセンターを基盤に、データ主権とセキュリティを確保しながら、生成AIを業務基盤として活用できる環境を提供します。
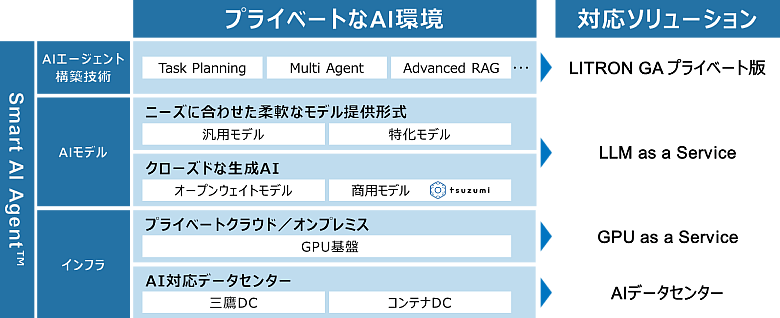
図4:NTTデータのプライベートAIソリューション
プライベートAIの導入に関するご相談やご質問がございましたら、ぜひお気軽にお問い合わせください。
【連載】スペシャリストが語る ビジネス変革に効く生成AI最新動向 これまでの連載はこちら
https://www.nttdata.com/jp/ja/trends/data-insight/2025/090902/

生成AI(Generative AI)についてはこちら:
https://www.nttdata.com/jp/ja/services/generative-ai
あわせて読みたい: