
- 目次
生成AIの企業導入の現状と課題
国内の企業における生成AIの活用動向については、「企業IT動向調査報告書2025」(発行:一般社団法人日本情報システム・ユーザー協会)によると、日本企業の21.0%がすでに言語系生成AIを導入しており、約73%の企業が「何らかの効果を確認した」と回答しています。主な利用目的は「生産性向上(90.1%)」「人材不足解消(38.6%)」「データ分析力向上(34.3%)」であり、ROIは限定的ながらも実務改善効果は高いと評価されています。
グローバルでは、「The State of AI in 2025」(McKinsey & Company)によると、約90%の企業が生成AIツール導入を開始しています。しかし、PoCを経て本番稼働に到達したのは44%にとどまっている状況です。
このように、企業における生成AIの活用は急速に広がりますが、その多くはPoCであり、本番稼働の場合でもオフィス業務支援や文書作成補助など、いわゆる「業務改善レベル」にとどまっています。「業務改善」も全社で行えば大きな稼働削減につながりますが、「ビジネスモデル変革」「新規事業創出」といった戦略的活用はまだ少なく、生成AIが企業変革の中核に据えられる段階には至っていないと考えられます。
その原因としては、生成AIや機械学習を包括した「戦略の不在」「業務リデザイン・ロードマップの不在」「人・組織の不在や、教育(リスキリング)の不在」「生成AIに対応したシステムアーキテクチャの不在」が考えられます。本稿では、「生成AIに対応したシステムアーキテクチャの不在」に焦点をあてて、競争力確保のためのエンタープライズ生成AIアーキテクチャについて紹介していきます。
生成AIに対応したシステムアーキテクチャ 生成AIの構成要素
生成AIのシステムは、基本的に、「画面・生成AIアプリケーション・フレームワーク」「基盤モデル」「データストア」の技術要素で構成されています。OSSを中心にさまざまなソリューションが登場してきており、企業の生成AIの用途に合わせた提供が可能となってきています。
Microsoftは、アーキテクチャ・パターンとして、従来のMVC(Model, View, Controller)のControllerの代わりにAIを加えた「MVAアーキテクチャ(Model, View, AI)」を提唱しています。これを、基本的な技術要素に当てはめると、「画面・生成AIアプリケーション・フレームワーク=View」「基盤モデル=AI(Controller)」「データストア=Model」という位置づけです。
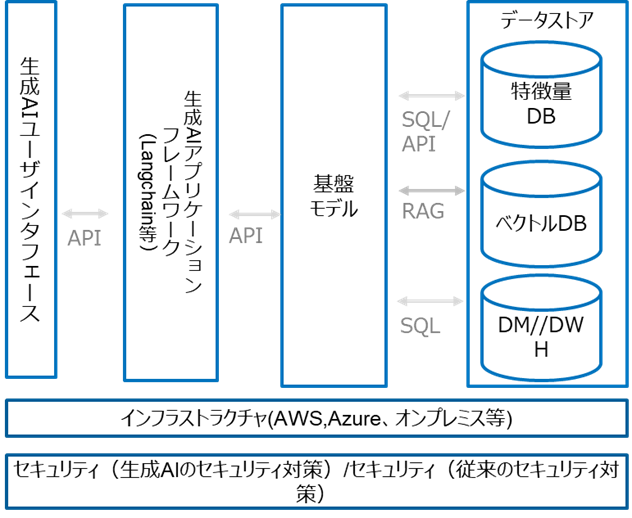
図1:生成AIの構成要素
それぞれの構成要素について解説しましょう。
画面・生成AIアプリケーション・フレームワーク
生成AIユーザインタフェースは、ユーザーが生成AIを利用するための画面やWebインタフェースのことです。例えば、Open WebUIなどがこれに該当します。
生成AIアプリケーション・フレームワークは、生成AIのチャット画面から基盤モデルへユーザーの指示を伝達したり、処理ロジックを記載したりする役割を担います。代表的なフレームワークとして、LangChain、LangGraphなどがあります。
基盤モデル
基盤モデルは、あらかじめ学習済みの言語モデルをAPIなどを通じて利用するものです。具体的には、OpenAIのGPTやAnthropic Claudeといった商用モデルと、LlamaなどのOSSモデルの両方が選択肢として存在します。普段「生成AI」として自然言語で問い合わせる先は、この基盤モデルを指しています。
データストア
データストアは、DWH(データウェアハウス)、ストレージ、RAG対応データベース、外部情報などを利用することができます。これらはそれぞれの専用プロトコル(APIやJDBC)を通じて接続することも可能ですが、MCP(Model Context protocol)という技術(規格)を用いた接続も可能です。
また、DWHにRAG機能の取り込む動きも見られます。MongoDBやPostgreSQLのpgvectorなど、RAG対応データベースも広がりを見せています。
生成AIに対応したデータ・アーキテクチャ提言 自社運用型AIへの変革
昨今のSaaS型生成AIサービスは、機能拡張や他サービスへの組み込みが目覚ましく進んでおり、複数の機能を内包し業種や領域に特化した、垂直統合型サービスへと進化していく様相を呈しています。
しかし、企業内で業務活用したいデータストアは、用途と内容によりセキュリティレベルやデータ量が異なるため、利用者による権限のコントロールや用途に応じた利用範囲の制限は欠かせません。モノリシックな単一の基盤モデルに社内基幹系データベースを接続し学習させることは可能ですが、その場合は、複雑な権限制御や認可・認証、セキュリティ設計が必要です。
最近では、OSSを中心に、SaaS型生成AIサービスと同様の機能を自分の用途に合わせて構成したり、「画面・生成AIアプリケーション・フレームワーク」「基盤モデル」「データストア」を個別に選んで利用したりできるようになってきました。本稿執筆時点において、Hugging Face(AIモデルやデータ、ツールを公開するためのプラットフォーム)では、100万以上のモデル、50万以上のデータセットが公開されています。
多様化する生成AIの用途と性能、セキュリティガバナンス、コストを保つために、今後は、用途に応じたさまざまな規模の言語モデルとデータを疎結合にし、マルチエージェントで業務課題を解決する「自社運用型AI」に移行すると、筆者は考えています。特に、基盤モデルにおいては、OSSと商用モデルのハイブリッド活用により、企業や業界ごとの独自のAIエコシステムが形成されるでしょう。それらの運用は、インフラストラクチャやデータガバナンス/データマネジメント、統合的なセキュリティ対策といった非機能要素によって支えられていくものと考えられます。
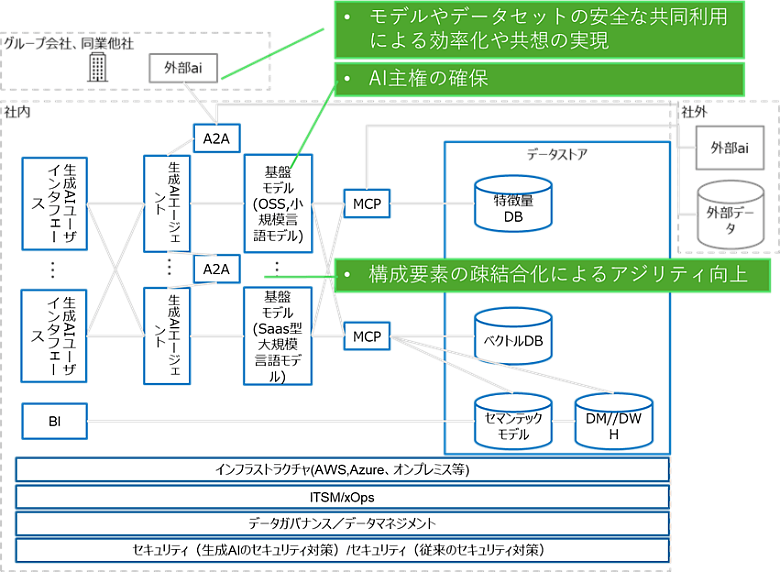
図2:自社運用型AIとその利点
一方で、「自社運用型AI」にはメリットとデメリットがあります。中でも、専門人材の確保は課題になると考えています。

表:自社運用型AIのメリット・デメリット
NTTデータにおける自社運用型AIの取り組み
生成AIの進化が続くなか、自社運用型AIへの投資は、単なるコスト削減策ではなく、生成AIを利用した競争力の源泉となる可能性があります。
NTT DATAは、クラウドでの自社運用型AIの提供や、そのシステムインテグレーションを提供しています。生成AI全体に対するコンサルティングを行い、構想から構築、ビジネス価値創出、人材育成まで、一気通貫の支援を行っています。

NVIDIA最新GPU を活用した大規模機械学習向け基盤提供を開始についてはこちら:
https://www.nttdata.com/global/ja/news/topics/2025/031900/
あわせて読みたい: