
「ビッグデータ」の時代から現在
Apache Hadoop(以降、Hadoop)(※1)やApache Spark(以降、Spark)(※2)に代表される「ビッグデータ」を取り扱うためのオープンソースソフトウェアの並列分散処理基盤は、ここ10年ほどで一般的なエンタープライズにも広く知られるようになりました。これらを用いたデータ活用事例は、国内外のカンファレンスを通じて多数公開されてきました。例えば、日本においてはNTTデータテクノロジーカンファレンス等でエンタープライズにおける事例が紹介されています。(※3)
図1:大量のデータ処理・活用に向けられた期待は高度化している
「活用」という観点では、最初は大量データの単純な処理を高速化するだけでも有益だと考えられていたものが、付加価値が高く複雑な処理を含む取り組みへの応用が期待されるようになりました。例えば、機械学習やAIの活用はその一例です。そういったユースケースで生じる要件に応えるため、スケーラブルであることを前提としつつも、より多様な構造・非構造データに対応し、高度な柔軟な仕組みが求められています。
データレイクに求められることも変化し続けている
要件の多様化・高度化の流れを受けて「処理の仕組み」については、Hadoop MapReduce フレームワークから後発のSparkのような新しい技術にデファクトスタンダードが移ってきました。それではデータを蓄積するための仕組みはどうでしょうか。Hadoopの分散ファイルシステムHDFSやオブジェクトストレージは今もよく使われている仕組みのひとつでり、「データレイク」を構成するための重要技術です。
しかし多様化、高度化する要件を踏まえたとき、これらの仕組みが提供する特徴、APIではやや不十分なケースも見られるようになりました。そこで、データレイクに新たな特長を付与する「ストレージレイヤソフトウェア」と呼ばれる技術が登場しています。ストレージレイヤソフトウェア全般についてはぜひ過去のInsight記事・講演(※4、※5)も参考にしてください。本稿ではその中でも、データ分析を特に指向した特長を有する「Delta Lake」を紹介します。なお、「D“a”ta Lake」と「D“el”ta Lake」が似ていますので、本稿ではそれぞれ「データレイク」(カタカナ)と「Delta Lake」(英語)と書き分けて表現することにします。
Delta Lakeはデータレイクに新しい特長を与える
Delta Lakeとは、信頼性の高い読み書きを高速かつ同時に実行できることが特長のオープンソースソフトウェアのストレージレイヤソフトウェアです。Delta Lake自体にデータ蓄積機能はなく、指定のフォーマット・動作でデータレイクのストレージに読み書きを行うのを補助するように機能します。
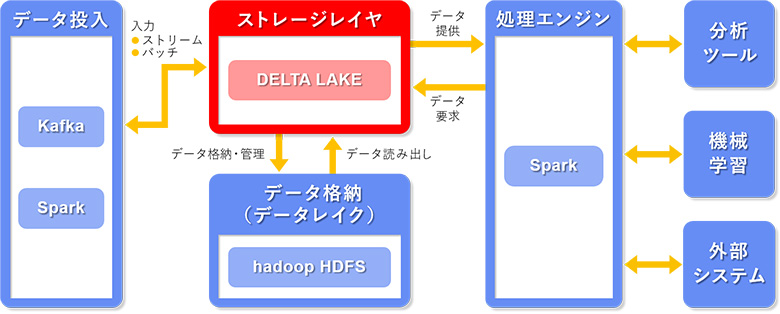
図2:SparkからDelta Lakeを経由してデータレイクのストレージにデータ書き込み/読み出しする
図のように旧来のデータレイクとDelta Lakeが一体となってデータレイクとして機能すると考えてもらうとよいです。Delta Lakeを利用することで、
- バッチ処理・ストリーム処理両方の入力が可能
- リアルタイムデータ・過去データともに活用可能
- シンプルなパイプラインを実現
- 多様な分析を行う処理ライブラリ、開発言語から利用可能
- スキーマを考慮してデータセットを更新可能
- ACID特性を担保した信頼性の高いデータの書き込みが可能
- データのバージョン管理により分析の再現や同一データセットの反復利用が可能
といった特長を利用可能になります。データレイクに特長を「付与」するようなイメージなので、アーキテクチャスタックで表すと以下のようになります。

図3:旧来のデータレイクに新しい特長を加えるDelta Lake
Delta Lakeの特長の一部を紹介!
ここでは、数ある特長のうち、「スキーマを考慮してデータセットを更新可能であること 」と「ACID特性を担保した信頼性の高いデータの書き込みが可能であること」について説明します。
1.スキーマを考慮してデータセットを更新可能であること
データ分析をしていると意図せずデータ構造(スキーマ)がばらばらのデータが混在することがあり、いざ使おうと思ったときに困る、という経験がありませんか。Delta Lakeを活用することで、書き込み時にスキーマが異なる場合にデータの更新を拒否したり、一定のルールに基づいて機械的にマージしたりできるため、読み込み時つまり分析するときに安心して取り組めるようになります。
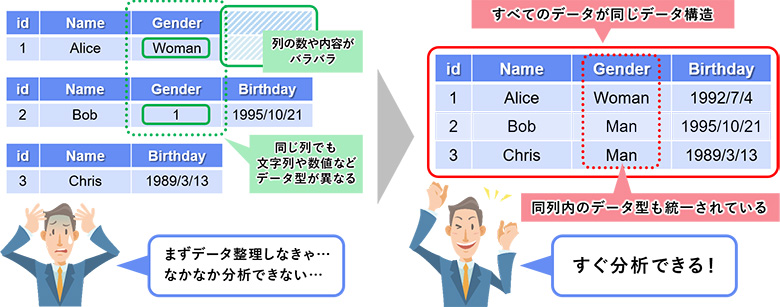
図4:データセットのスキーマが統一され安心して分析に着手できる
2.ACID特性を担保した信頼性の高いデータの書き込みが可能であること
データレイクに用いられるストレージは、部分更新を想定していないか、標準的に対応していないことがあります。その場合データ更新時は丸ごと置き換えるか、別のデータセットとして追記することになります。しかし、複数のアプリケーションによる同じデータセットに対する同時読み書き・更新をうまく扱えないと、意図しない書き込みや読み込みが生じてしまいます。Delta Lakeを用いると、データセット内で対象箇所のみ更新ができ、かつ同時読み書き・更新を安全に行うことができるようになります。
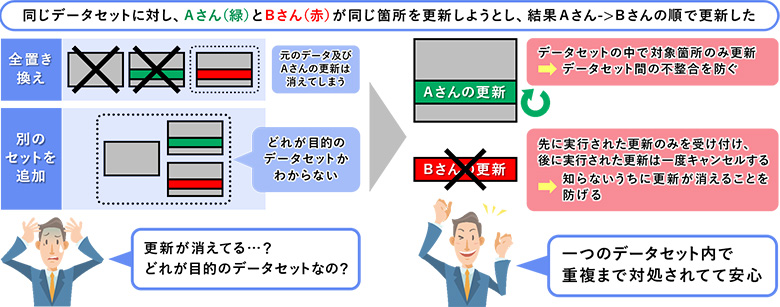
図5:更新が失われる、目的のデータセットが分からないという問題が解消される
また、Delta Lakeによるデータセット内の書き込みは、データ本体と操作ログがセットで保存され、データ更新時にも履歴が保持されます。そのため操作ログを利用して過去のデータを再現できるので、データをバージョン管理しながら再現検証したり、同一データセットの反復利用ができるようになります。
Delta Lakeの使い方の例
Delta Lakeは、SparkのAPIと互換性があります。そのため、これまでのSparkアプリケーションとほぼ変わらない実装方法でDelta Lakeを利用できます。ひとつ具体例を紹介します。Sparkでデータを集計するような以下のアプリケーションでは、
data.groupBy(“id”).agg(“score” -> ”avg”).write().format(“csv”).mode(“append”).save(path)
のような方法でデータをデータレイクに書き出します。ここではデータレイクにCSV形式で出力する例になっています。 上記の「format(“csv”)」となっている個所を「format(“delta”)」に変更することでDelta Lakeを通じてデータレイクに書き込めるようになります。

図6:formatの変更のみでDelta Lakeの恩恵を受けることができる
他にもDelta Lakeを通じて書き込んだデータに対して、所定の条件に基づいて新しいデータをマージする機能もあります。これを旧来のデータレイクだけで実現するには、様々なアプリケーション実装上の工夫が必要になることを考えると、大変便利な機能だと言えるでしょう。
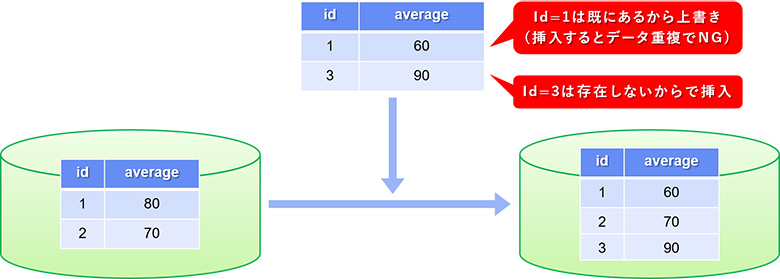
図7:旧来のデータレイク単体では工夫が必要だった、データのマージ処理
NTTデータの取り組み
NTTデータはHadoop、Spark、Apache Kafka(※6)を代表とするオープンソースソフトウェアの並列分散処理を活用したデータ処理・活用基盤に関する研究開発、システム開発を10年以上手掛けてきた専門家集団を有しています。それらの専門的知見を自然に活用してもらえるようなリファレンスアーキテクチャや本稿で紹介したような近い将来多くの企業が抱える課題を解くための技術の研究開発・普及展開を行っています。機械学習基盤、ストリームデータ活用基盤など「ビッグデータ」を基礎とした基盤技術に関して、これからも世に貢献できる知見、技術、情報を提供してまいります。
(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019/09/05)
https://www.slideshare.net/nttdata-tech/bigdata-storage-layer-software-nttdata
