
1.生成AIを活用したインタビューエージェントとは
インタビューエージェントとは、AIが自律的にインタビューを行うことで、熟練者の頭の中にある知識や知恵を“見える化”し、ノウハウを効率的に抽出する技術です。インタビューエージェントは図1に示すような複数のAIエージェントから構成されます。業務内容などの情報や関連ドキュメントをAIにインプットすると、「質問生成エージェント」や「回答解析エージェント」、「成果物生成エージェント」といったAIエージェントが連携し、熟練者の暗黙知抽出を省力化しながら実現します。
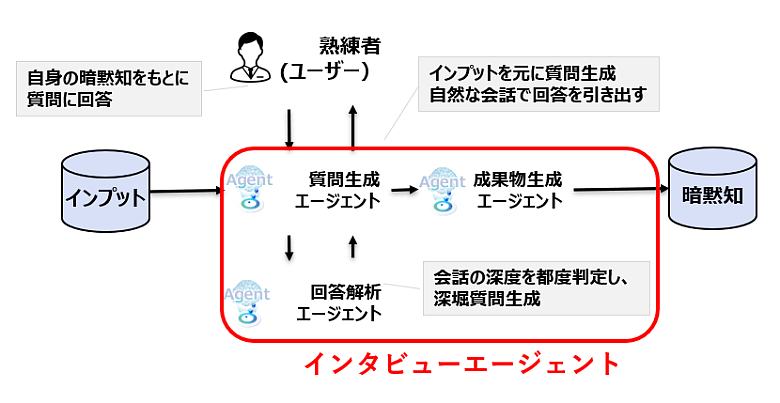
図1:インタビューエージェント×暗黙知抽出のアプローチ
2.インタビューエージェントの特色
インタビューエージェントは容易に導入可能です。事前に関連情報やドキュメントをインプットすることで、お客さまの業界や業務特性に合わせたインタビュー設計を行います。さらにチューニングなどの調整を行うことで、業務特化型のインタビューエージェントを比較的簡単に開発できます。
インタビューエージェントは技術・技能教育研究所 森 和夫氏の『暗黙知の継承をどう進めるか』(※1)の理論を踏まえ、プロのインタビュアーの手法に基づいてインタビューを実施します。森氏は、図2のように暗黙知を4つの階層に分類し、各階層に応じて形式知化する方法を記述しています。
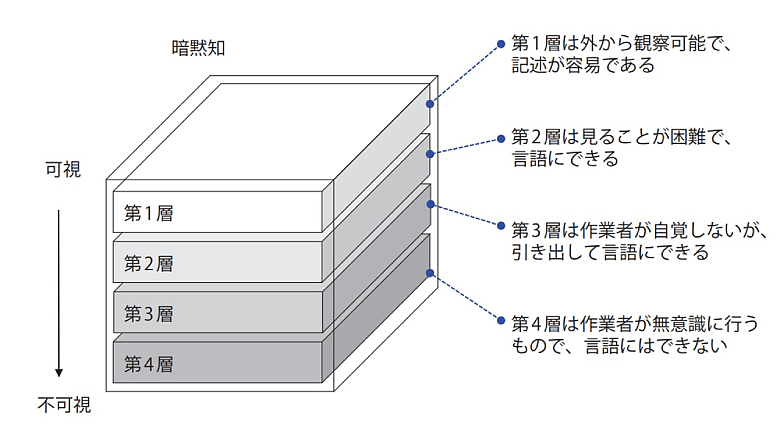
図2:暗黙知の4階層
インタビューエージェントは、この理論の第3層とされる「作業者が自覚しないが、引き出して言語にできる」暗黙知の抽出をめざしています。熟練者の回答が必要なレベルに達していないと判定すると、NTT DATAが提案する生成AIの活用コンセプト「Smart AI Agent®」の技術要素である「UITL(User-In-The-Loop)」(※2)によって、解像度を高める質問を動的に繰り返します。また、会話の流れに応じて柔軟にシナリオを変更し、不要な質問はスキップするため、効率的に回答を引き出すことができます。
さらに多言語対応も可能で、NTT DATAの海外事業会社では、日本語版に加えて英語版も活用しています。
インタビューエージェントの活用事例
現在、NTT DATAは大手製造業の川崎重工業様の設計業務において、熟練設計者の暗黙知を形式知化して若手設計者に伝承する取り組み(※3)を実施中です。この事例では、インタビューエージェントと生成AIを活用した文章検索・回答生成システム「LITRON® Generative Assistant」を組み合わせ、暗黙知の抽出および活用に取り組んでいます。
この2つの技術により、若手設計者は業務上の不明点を効率的に解消し、独力で業務範囲を広げられるようになります。一方、熟練設計者は若手設計者からの質問対応が減少し、自らの業務に専念できる効果が期待されています。
次章では、インタビューを実施するプロセスや差別化ポイントについて解説します。
ユーザー(人間)の意図や判断を取り込み、AIエージェントの出力や振る舞いを継続的に調整・最適化するアプローチ
3.暗黙知抽出のためのプロセス設計
暗黙知をもれなく引き出すために、インタビューエージェントは熟練者がインプットした情報を基に暗黙知を「工程(プロセス)」単位で構造化し、段階的に情報密度を高めたシナリオを作成します。その後、「(1)全体概要・意義の確認」、「(2)初期質問の生成」、「(3)各工程の深掘り」の3ステップでインタビューを実施します。

図3:インタビュープロセスの設計思想
インタビュープロセスの3ステップ
- ステップ1:全体概要・意義の確認(入力整理と工程ツリー生成)
インタビューエージェントが、熟練者の関連ドキュメントを工程レベルに分解し、階層(ツリー)構造として出力します(これを「工程ツリー」と定義します)。工程ツリーは、後続の初期質問と深掘りするための土台(索引)を生成します。 - ステップ2:初期質問の生成(全工程の基本的な情報を広くヒアリング)
初期質問の目的は深掘りではなく、各工程の基本的な情報(何を、どのように、何のために、何を使い、どの程度で)をヒアリングし、工程ごとの情報の土台を作ることです。先述した森氏の理論を基に、暗黙知を引き出す質問を設計します。次に工程ツリーの各プロセスに対して、汎用(はんよう)的な4観点(A.視覚・聴覚、B.動作、C.コミュニケーション、D.判断)から初期質問を自動生成します。 - ステップ3:各工程の深掘り(深度判定に基づく追加質問の自動生成)
ステップ2の初期質問で得られた基本情報は、暗黙知の抽出としては不十分なケースが一般的です。そこで、回答の「深さ」や「広さ」の解像度を高めるために深度判定を行い、不足がある観点に対しては深掘り質問を生成します。
深度判定は、以下の3観点に集約して適用します。
- 具体性:手順・条件・基準・例示が十分に具体化されているか
- 因果関係:背景・理由・判断根拠・失敗回避のロジックが説明されているか
- 表現のあいまいさ:適切な用語や明確な表現が使われているか
上記3観点から深度が不十分と判断した場合は、「具体化」、「理由の掘り下げ」、「例外ケースの確認」といった質問を生成し、より深い暗黙知の抽出を図ります。図4に示した質問例は一例ですが、ターゲットによって深度判定の観点と深掘り質問は柔軟に変更できるよう設計しています。
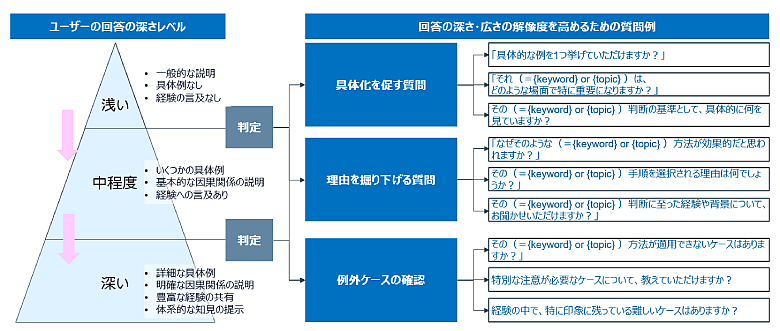
図4:ユーザーの回答の深さレベルと回答の解像度を深めるための質問例
インタビューエージェントの設計上の差別化ポイント
インタビューエージェントは質問の手順を固定化せず、返答に応じて動的に質問を生成します。その特徴は、以下の通りです。
- (1)インタビュー時に質問の順番を変更可能
追加情報が得られた場合、工程の追加・分割・統合などを更新し、実務に即した質問を行います。 - (2)深度判定および深掘り質問の設計
深掘り質問は、その場で思いついた質問ではなく、深度判定(具体性、因果関係、用語適切性)に基づいて、不足分を補完生成します。 - (3)入力分類ロジックの導入
従来、ユーザーの返答はすべて「回答」として処理されていましたが、実運用では回答だけではなく、逆質問や質問のスキップ、補足依頼なども混在します。そこで、ユーザーの入力を分類するロジックを追加し、対話制御の精度を向上させました。
入力を分類するロジック
- 回答:質問に対する情報提供
- 逆質問:質問意図や用語定義の確認など、ユーザーからの問い返し
- スキップ:回答不能・対象外・記憶にないなどの明示
この分類により、誤った質問を継続したり、論点が逸脱したりしないよう抑制できるため、よりスムーズにインタビューを行えます。
インタビュー結果の取り扱いについて
インタビューエージェントは、インプットドキュメントおよびインタビューを通じて得られた情報を、当該インタビューの分析・整理という目的に限定して利用します。これらの情報は生成AIの学習データとして使用されることはなく、処理に必要な期間を超えて保持されることはありません。
4.おわりに
NTT DATAは、「暗黙知の抽出」と「暗黙知の共有・活用」の両輪で、組織の生産性向上および業務効率化を図ることが重要だと考えています。現在は、暗黙知の抽出および活用をグローバルレベルで推進し、国内外でのソリューション開発に取り組んでいます。インタビューエージェントの活用においても、先述したLITRON® Generative Assistantに加え、NTT DATA, Inc.のアセットであるKANO(※4)との連携も開始しました。
暗黙知伝承は、ノウハウの消滅を防止するためにも早急に取り組むべき課題です。NTT DATAでは、暗黙知伝承についてのご相談やご質問を受け付けております。今後も、暗黙知の抽出と形式知化された情報活用を推進し、お客さまの業務効率化と生産性向上に貢献してまいります。
https://www.nttdata.com/global/en/-/media/nttdataglobal/1_files/insights/reports/agentic-ai/virgin-media-o2-information-discovery-acceleration-a-moonshot-realized.pdf

あわせて読みたい: