
1.ローカルLLM活用に向けた合成データの課題
社内の暗黙知や機密データを処理する方法として、ChatGPTなどのオープンLLMに代わり、ローカル環境で動作するLLMに注目が集まりつつあります。NTTが開発したtsuzumiもローカルLLMの一種であり、社内知識やセキュリティが求められる場面を中心に活用ニーズが確認されています。こういった場面では、業務に特化した知識をローカルLLMに学習させることでより高精度な回答が期待できます。
一方で、ローカルLLMを業務に特化させるには学習データが必要であり、実データの不足や偏りは避けて通れません。従来は、学習に必要なデータを確保するための手段として、LLMによって説明文を生成する手法が一般的に用いられてきました。この際、単純に大量のデータを生成させると似通ったデータばかりとなってしまい、汎化性能(※1)が下がってしまうリスクがあります。そのため、学習を効果的に進めるためには多角的な表現での説明文が重要であることが知られています。しかし、説明文の準備には手間がかかり、人手での対応には限界があります。
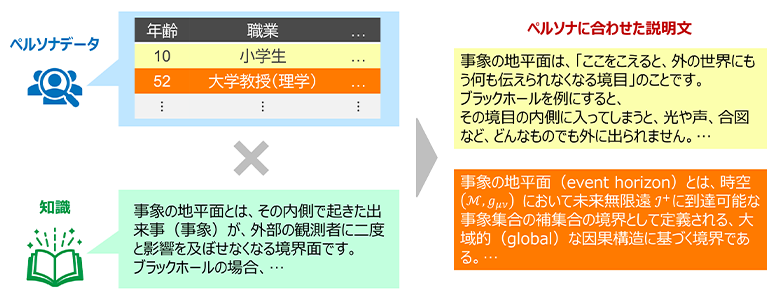
図1:ペルソナデータによるデータ拡張の全体イメージ
そこで、こうした制約を乗り越える手段として、ペルソナデータを用いた学習データ拡張に着目します。
ペルソナデータを用いた学習データ拡張では、年齢・性別・趣味・特技・職業など、個人に関する情報を説明文の生成時に参照し、その特性に合わせた説明文を自動で生成します。これにより、事前に多様性を定義せずとも、ペルソナデータが持つ多様性に応じて、バリエーションに富んだ説明文が生成されることが期待できます。
例えば、小学生のペルソナ向けには重要なポイントのみをシンプルに平易に説明した説明文を生成し、専門分野のプロフェッショナル向けには具体的な詳細まで専門用語を含めつつ生成する、といった具合です。
本検証では、ペルソナデータ活用により、低コストで十分な量の学習データを生成できるかどうか、こうして生成された学習データがモデルへの知識追加にも効果的であるかの2点を確認しました。
モデルが学習時と異なる未知のデータにも正しく対応できる能力のこと。学習データに過剰に適合すると、学習データに対しては良い性能を示すが、汎化性能は下がる。
2.法律知識追加でペルソナデータの有効性を実際に検証
今回は、検証対象のモデルとして弊社の「tsuzumi 2」を利用し、ペルソナデータとしては「Nemotron-Personas-Japan」を用いました。
Nemotron-Personas-Japanは日本の人口統計、地理的分布、文化的特性に沿ったペルソナを含むオープンなデータセットであることから、今回の目的に適していました。
このデータセットは100万人分のレコード情報で構成され、それぞれに図2に示すような6つのカテゴリがあることから、600万件分のペルソナが含まれています。各カテゴリごとのペルソナを用いることで、理論上、最大600万通りの説明文を生成することが可能です。
また、ペルソナデータは完全に人工的に合成されていることから、個人を特定できる情報は含まずに、実データの統計的な特徴だけを模倣します。
モデルに知識が追加できるかを検証するにあたり、元々モデルが持っていない知識を選定することも重要です。
今回の検証では図3のような30種類の架空の法律データを準備し、その法律に関する質問に答えることができるかどうかにより、学習後のモデルが知識を獲得したかどうかを判定しました。
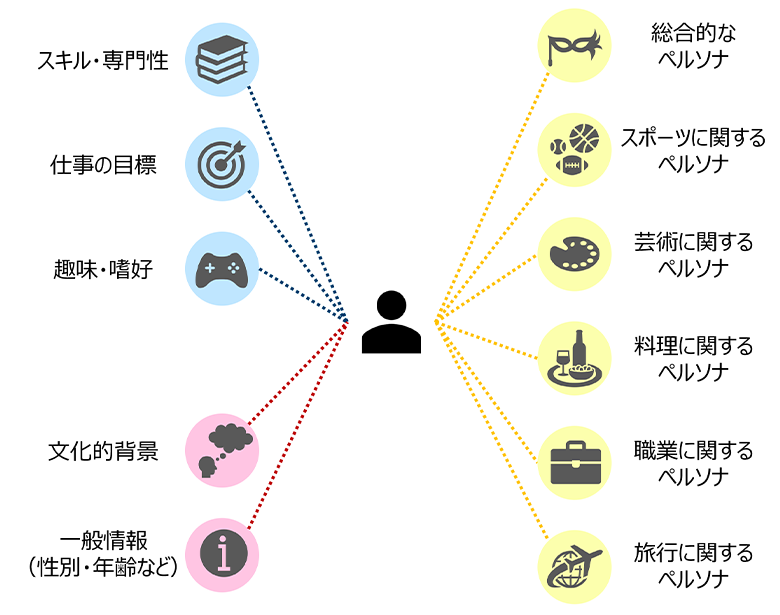
図2:Nemotron-Personas-Japanに含まれるペルソナ情報

図3:検証で用いた架空法律の例
モデルの学習は1.継続事前学習(教師なし)、2.インストラクションチューニング(教師あり)の流れで構成し、合成データの有無や学習段階の違いによる効果を比較しました。評価は、
- 網羅性(質問に対してどの程度要点をカバーできているかを指標化したもの)
- 基法律との矛盾回避(学習対象とした法律定義とモデル回答の整合性を指標化したもの)
の二軸で行いました。
評価にはGPT-5によるLLM-as-a-judge(※2)を用いており、人手評価ではない点には留意が必要です。
LLMによりモデルの回答内容を評価する方法。今回の検証では評価モデルが誤った結果を返す可能性も考慮し、同一の問題に対して5回正誤判定を実施し、4回以上正解判定されたものを正解扱いとした。
3.ペルソナデータによりQA正答率が5倍以上に!
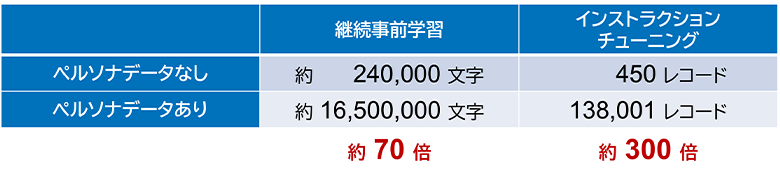
本検証の結果、ペルソナデータをプロンプトに組み込む処理を準備することで、ほぼ全自動で表1の通り学習データ量を増やすことができました。この結果から、1つ目の検証ポイントであった「低コストで十分な量の学習データを生成できること」については十分満たしていると考えられます。
表1:ペルソナデータ活用による学習データ量の増加
2つ目の検証ポイントである「生成された学習データがモデルへの知識追加にも効果的であるか」については、表2に示す結果となりました。
学習前は15%弱だったQA正答率が、ペルソナデータを用いた学習により80%弱まで向上し、知識追加が進んでいることが確認できました。特に、ペルソナデータなしでの学習と比較すると網羅性において大きな差がみられ、ペルソナデータにより深く知識が獲得できているといえます。
表2:ペルソナデータ有無によるQA正答率の違い
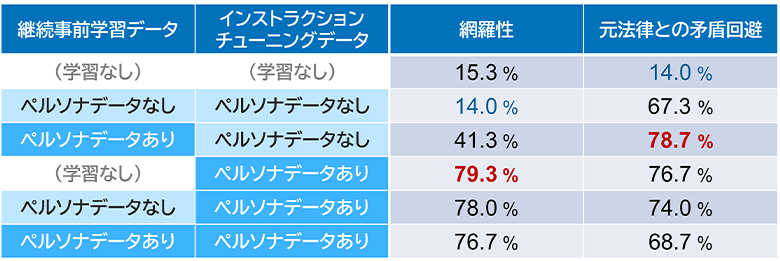
一方で、継続事前学習時のみデータ拡張した場合は、インストラクションチューニングでデータ拡張した場合ほど大きな効果はありませんでした。ただし、網羅性・矛盾回避の両面で大きく値が上がることからモデル能力の底上げとしての可能性が示唆されます。
これらの結果から、元の学習データ量が少ない場合でも、モデル能力を大幅に向上する学習データがペルソナデータにより手軽に合成でき、ローカルモデル活用において重要な役割を果たすことが分かりました。
4.今後の展望
今回ご紹介したペルソナデータによるデータ合成手法により、これまで業界特化・企業特化モデル実現において大きな壁となっていた学習データ量不足を乗り越え、より手軽に社内の独自用語や専門知識を持ったローカルLLM実現に大きく近づいたといえるでしょう。
合成データは「量を補う技術」から「品質と多様性を両立させる戦略」へと進化しつつあり、ローカルLLM活用において、今後さらに重要な位置づけになると考えています。
NTT DATAでは今後もこれらの検証を重ね、カスタマイズされたローカルLLMの実業務での活用に向けて適用ノウハウを蓄積してまいります。

Nemotron-Personas-Japanについてはこちら:
https://huggingface.co/datasets/nvidia/Nemotron-Personas-Japan
あわせて読みたい: