
- 目次
「自動化」と「自律化」--似て非なるパラダイムシフト
この罠を理解するために、「自動化」と「自律化」の違いを整理していく。
RPA(Robotic Process Automation)に代表される「自動化」は、あらかじめ決めた手順や条件に従う。想定外が起きれば停止。あくまで「人間の手」の代行だ。
それに対して「自律化」は、目標を基準に動く。AIエージェントが状況を判断し、手段を選んで実行する。想定外の事態でもポリシーの範囲内で適応を試みる。これは判断という「人間の脳」の代行である。
この差は決定的で、自動化は事前に手順や条件を定義すれば動く。しかし自律化には統治の設計が前提になる。どこまで任せるのか、どの条件で人間が介入するのか、失敗したときに誰がどう修正するのか。設計のない自律化は、制御不能な暴走と同義だ。
ほとんどの企業はこの統治設計が欠落している。そのためPoCは「実験」で止まり、本番には進めないのだ。
立ちはだかる3つの壁--日本企業はなぜ抜け出せないのか
では、具体的に何が壁になっているのか。
第一に、Knowledge(知識)の壁。PDFの契約書、メール、チャットログ、会議音声。企業の知的資産の大半は「非構造化データ」だ。さらに厄介なのが暗黙知。ベテラン社員の頭の中にしかない判断基準を、AIが参照可能な形に構造化できなければ、自律型エージェントは誤判断を繰り返す。
日本企業でこのハードルが高いのは、業務をベンダーに丸投げする体質が背景にあるからだ。「AIベンダーに頼めば業務を理解して設計してくれる」という期待は根強いが、LLMに注入すべき自社固有の業務判断基準や例外ルールは、ベンダーが持っていない知識だ。業務フローと実際の運用が乖離し、「なぜこの確認業務が必要なのか」を説明できる人がいない企業も少なくない。AIに渡すべきKnowledgeが、そもそも組織の中に存在していないのだ。
第二に、Tooling(道具)の壁。継ぎ接ぎだらけのレガシーシステムではAIは「手足をもがれた」状態だ。API連携もままならず、ログも残らなければ、自律化の改善ループも回らない。JUAS(一般社団法人日本情報システム・ユーザー協会)の調査では、言語系生成AI導入企業の約6割が効果測定を実施していない状況だ。(参照元)
そして第三に、Permission(権限)の壁。AIにどこまで任せるかの設計が部門ごとにバラバラでは、全社での統治は成立しない。日本の合議・稟議を含めた多層的な承認フローはAIの権限設計を難しくする。しかし裏を返せば、この権限管理の経験を活かすことで、むしろ緻密な設計という強みに転じる可能性がある。
重要なのは、これら3つの壁が「個別の課題」ではなく連動していること。さらに日本企業では、部門PoCが成功しても横展開の仕組みがないまま、担当者の異動とともに消えてしまうことも多い。PoCの乱立と、学習の不在。この断層を埋めるのが、次に述べる全社の運用設計だ。
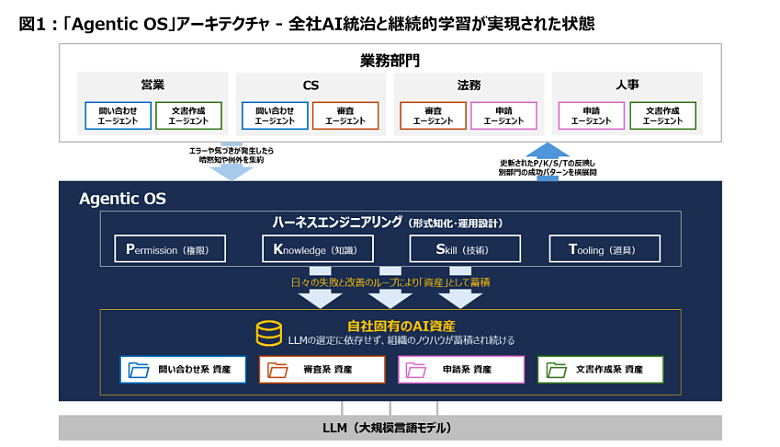
Agentic OSの構築--「ハーネスエンジニアリング」の実践
3つの壁を個別に埋めても、部門の最適化にとどまる。必要なのは全社を横断する運用OSだ。
経営者に馴染みやすい言い方をすると、AIエージェントの管理は、新入社員のオンボーディングと同じ構造だ。Permission(P)は職位と承認権限の設計。Knowledge(K)は研修資料とナレッジベースの整備。Skill(S)はスキルマトリクスと評価基準の定義。そして、Tooling(T)は業務ツールとシステムアクセスの支給だ。新しいのは、対象が人間からAIに変わったことだけだ。
ただし、人間は経験を蓄積するが、LLMは毎回記憶喪失になる。だからこそ、P/K/S/Tを組織の外部記憶として設計し、運用し続ける仕組みが不可欠なのだ。この設計思想がハーネスエンジニアリング。そして、ハーネスエンジニアリングを部門最適で終わらせず、全社レベルで実装したものが「Agentic OS」だ。
全社でこの仕組みを回す鍵は、部門名ではなく「業務類型」でくくること。「問合せ系」「審査系」「申請系」といったくくりで見れば、ある部門で作ったP/K/S/Tを別部門にも展開でき、全社レベルの学習速度が上がる。
組織の成熟度で言えば、多くの企業は導入段階にいる。次に必要なのは運用、そして最終的に目指すのは学習だ。失敗と改善のループを組織に定着させ、LLMの選定に依存しない「学習が累積する状態」を築く必要がある。これが整わないまま全社展開を進めると、失敗を大量生産する結果になってしまう。
私が率いたバックオフィス改革で見えたもの
私は自社および顧客企業のバックオフィス改革プロジェクトを率いる中で、財務・人事・業務統括の3領域に生成AIを同時に導入した。その結果、検収審査のような定型度の高い業務で大幅な工数削減が見込める一方で、例外対応の多い業務では削減効果は限定的だった。
この差はAIの性能ではなく、業務設計の構造差だ。定型業務はSkill(手順化)とTooling(自動連携)が整っていたが、例外業務はKnowledge(暗黙知の構造化)とPermission(承認権限のルール化)が不十分だった。P/K/S/Tで見れば、次にどこを改善すべきかが一目瞭然である。
さらに大きかったのは、長年にわたる事務委託の中で、業務の全体像を把握している人が誰もいなくなっていたこと。公式の業務フローと実際の運用が乖離し、「なぜこの手順が必要なのか」の文脈が失われていた。この状態でAIを入れても、「現在の業務を少し便利にする」程度の改善にとどまる。AI導入以前にKnowledgeが壊滅的に欠けていたからだ。
一方で、部門を横断して「問合せ系」「審査系」といった業務類型でくくると、ある部門で得たP/K/S/T設計が、別部門の同種業務にも活用できることが見えてきた。
ただし、すべてが横展開できるわけではない。人事系の業務には、自治体ごとに様式が異なる書類や制度固有の例外処理といった外部ルールに依存する特殊性の高い領域があり、他部門の知見をそのまま使うことはできなかった。横展開できるものと、個別に設計すべきものを見極める力が、Agentic OSの設計者には求められるのだ。
バックオフィスは「処理の場所」から「統治の中枢」へ
この連載では、生成AIが組織に根づかない構造的な理由を、3つの現場から描いてきた。
それぞれの現場は異なるが、共通する解は一つ。失敗をP/K/S/Tの4分類で切り分け、改善を運用資産として全社に積み上げていく。この仕組みが、LLMを「便利ツール」から「経営資産」に変える鍵となる。
OpenAIやグーグルは優れたプラットフォームを提供している。しかし、自社固有のP/K/S/T設定はどのベンダーも提供できない。自社の承認フロー、業務知識、品質基準、システム環境を設計し、運用し、改善し続けるのは、自社にしかできない。
バックオフィスは、処理の場所ではなく、企業の知性と統治を司るインテリジェンスの中枢へと進化すべきだ。しかし、その議論の多くは米国の商慣習を前提としている。日本企業が直面する「稟議文化の複雑さ」「ベンダー丸投げの体質」「業務実態の空洞化」。これらの課題に向き合い、解決策を提示した人はまだ誰もいない。
企業の競争力を左右するのは、どのLLMを選ぶかではない。どれだけ優秀なハーネスを設計し、運用し、学び続けられるか。その一点にかかっていると我々は確信している。

生成AI(Generative AI)についてはこちら:
https://www.nttdata.com/jp/ja/services/generative-ai/
あわせて読みたい: