
1.生成AI導入における企業の課題
生成AIの導入が進み、多くの企業がPoCを経て実業務への適用を検討する段階に入っています。一方で、「効果は確認できたが全社展開に踏み切れない」といった課題も顕在化しています。
その背景にあるのは、生成AIが自社の業務や環境に適した条件を満たしているかを見極めきれていないという点です。セキュリティやデータ統制、既存システムとの整合、運用コストといった要件を満たせなければ、PoCで有効に見えたとしても実運用にはつながりません。
こうした条件を大きく左右するのが生成AIモデルの選定です。技術革新により選択肢は大きく広がっています。海外の高性能モデルを中心に据えるのか、あるいは国産モデルを活用するのか。クラウドサービスとして利用するのか、自社環境での運用を前提とするのか。いずれも一長一短があり、単純な比較で優劣を決めることは難しくなっています。
特に悩ましいのは、「性能が高いモデルを選べばよい」という単純な話ではない点です。実際の業務に適用しようとすると、セキュリティやデータの取り扱い、既存システムとの連携、運用コストといった観点が意思決定に大きく影響します。その結果、PoCでは有効に見えたものの、本格的な活用に踏み切れないというケースも少なくありません。
企業は、「どの生成AIモデルが高性能か」ではなく、「どの生成AIモデルが自社の業務や環境に適しているか」という視点を持つ必要があります。この視点を持たない限り、生成AIの導入は部分的な活用にとどまり、全体最適にはつながりません。
2.生成AIのモデル選定で検討すべき3つの観点
では、生成AIのモデル選定において、企業は何を基準に判断すべきなのでしょうか。ここでは、実際の業務適用を前提とした場合に重要となる3つの観点を整理します。
1つ目は、セキュリティとデータ統制です。
企業の業務では、顧客情報や契約情報、社内の機密情報など、外部に出すことができないデータを扱う場面が多くあります。そのため、どのような環境でAIを利用するのか、データがどのように扱われるのかは、最初に確認すべき重要なポイントです。特に、閉域環境やオンプレミスでの運用が可能かどうかは、活用範囲に大きく影響します。
2つ目は、業務適合性です。
実際の業務では、生成AIモデルの性能のみならず、日本語特有の表現や業界ごとの文脈、前提知識を踏まえた理解が求められます。こうした要素に適合しない場合、出力の修正や確認に手間がかかり、結果として業務効率化につながらない可能性があります。精度そのものだけでなく、「そのまま業務で使えるか」という観点が重要です。
3つ目は、運用の現実性です。
生成AIは導入して終わりではなく、継続的に運用していくことが前提です。そのため、計算コストや応答速度、システムへの組み込みやすさ、生成AIモデルのアップデートに関する管理・対応といった要素を考慮する必要があります。PoCでは問題なくても、全社展開を見据えたときにコストや運用負荷が課題になるケースは少なくありません。
これら3つの観点に共通しているのは、「実際に使い続けられるか」という点です。
生成AIモデルの性能そのものは重要な要素の一つですが、それだけでは十分ではありません。セキュリティ、業務適合性、運用現実性のバランスをどのように取るかが、生成AI活用の成否を左右します。
3.NTTの国産生成AIモデル 「tsuzumi 2」という選択肢
ここまで見てきたように、企業が生成AIを実業務に適用するためには、セキュリティ、業務適合性、運用の現実性といった観点を満たすことが前提となります。
こうした要件に対応する選択肢の一つが、NTTがフルスクラッチで開発した生成AIモデルである「tsuzumi 2」です。tsuzumi2は、1GPUで動作可能な軽量モデルでありながら、超大型モデルに迫るトップクラスの性能と、高い日本語処理能力を備えています。パラメータサイズが小さいため、学習やチューニングに必要なコストを抑えられる点も特長です。さらに、金融・自治体・医療分野に関する知識を幅広く学習しています。
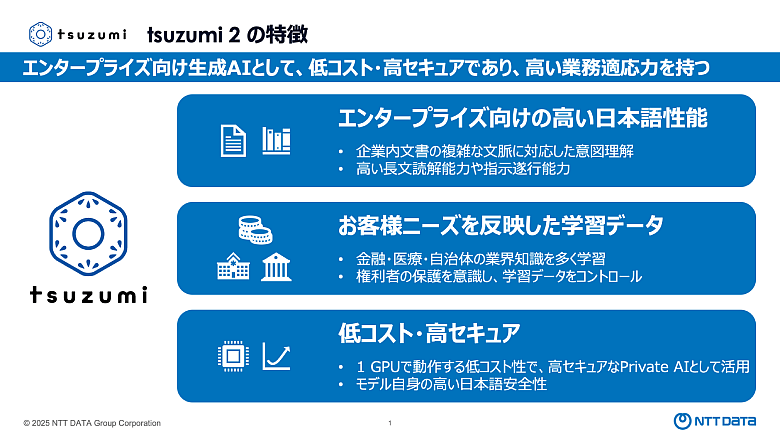
図:tsuzumi2の特徴
前章で整理した3つの観点に照らして見ると、tsuzumi 2の位置づけがより明確になります。
まず、セキュリティとデータ統制の観点です。tsuzumi 2は国産の大規模言語モデルであり、企業の要件に応じてクラウドだけでなく、閉域環境やオンプレミスでの利用も視野に入れることができます。これにより、機密性の高いデータを扱う業務においても、運用設計の自由度を確保しやすい点が特徴です。データの取り扱いに慎重な企業にとっては、この柔軟性が重要な判断材料となります。
次に、業務適合性の観点です。tsuzumi 2は、日本語のビジネス文書や業務文脈への適合性を重視して設計されています。企業の業務では、多くの情報が文書として蓄積されています。社内規程や業務マニュアル、過去の報告書などをもとに業務を進める場面は少なくありません。こうした文書を活用する際には、単に文章を読むだけでなく、文書の構造や意図を踏まえて必要な情報を整理することが求められます。例えば、前提条件と結論の関係を整理したり、複数の文書を横断して要点をまとめたりといった処理です。tsuzumi 2は、日本語のビジネス文書における構造や表現の特徴を踏まえた処理を行いやすく、こうした文書活用の場面で、業務に沿った形での情報整理や出力を行いやすい点が特徴です。
そして、運用の現実性という観点です。tsuzumi 2は比較的コンパクトなモデル設計を採用しており、必要な性能を確保しながら、計算資源やコストを抑えた運用が可能です。これにより、PoC段階にとどまらず、実際の業務への展開や利用範囲の拡大を見据えた運用がしやすくなります。また、既存システムや業務フローへの組み込みやすさにも優れています。さらに、NTT DATAが提供を行うため、モデルのアップデートに関する管理もお客さまの要望に応じて行うことができます。
このように、tsuzumi 2は「突出した単一の強み」で選ぶモデルというよりも、セキュリティ、業務適合性、運用現実性といった複数の要素をバランスよく満たすモデルと位置づけることができます。
生成AIの選定においては、最も性能の高いモデルを選ぶことが最適解とは限りません。むしろ、自社の業務環境の中で無理なく使い続けられるかどうかが重要になります。その観点から見ると、tsuzumi 2は、生成AIモデルの選定基準にバランスよく応えられるモデルといえるでしょう。
4.tsuzumi 2の活用事例
こうした観点は、すでに具体的な取り組みにも現れています。
例えば、デジタル庁の生成AI利用環境「源内」では、国産モデルの一つとしてNTT DATAが提供するtsuzumi 2がガバメントAIとしての試用対象に選定され、行政文書作成支援や職員向け対話、業務アプリへの組み込みといった用途での活用が検討されています。ここでは、デジタル庁の業務に必要な基準について各モデルが評価され、適合したモデルとしてtsuzumi 2が選定されました。
また、NTT DATAは大手製造業の川崎重工業様の設計業務において、熟練者の暗黙知を生成AIによって抽出し、整理・共有する取り組みをtsuzumi 2を用いて行いました。この取り組みは、GENIAC-PRIZE領域01「国産基盤モデル等を活用した社会課題解決AIエージェント開発」において特別賞(ユーザー変革賞)を受賞しています。若手が必要な知識にアクセスしやすくなり、熟練者の負担軽減にもつながるエージェントを、機密情報を取り扱う業務に適合できるよう構築しています。
これらの事例からも、生成AIの価値は「どの生成AIモデルが高性能か」ではなく、「どの生成AIモデルが自社の業務や環境に適しているか」によって評価されることが分かります。
NTT DATAでは、tsuzumi2をはじめとした生成AIの活用において、業務プロセスの再設計、ユースケースの具体化から導入・運用定着までを包括的に支援し、お客さまの業務変革を伴走・支援していきます。

デジタル庁「ガバメントAI」でのtsuzumi 2試用に関する報道発表についてはこちら:
https://www.nttdata.com/global/ja/news/topics/2026/032302/
「GENIAC-PRIZE」製造業の暗黙知形式知化において「ユーザー変革賞」を受賞 に関する報道発表についてはこちら:
https://www.nttdata.com/global/ja/news/evaluation/2026/041700/
NTT DATAの生成AIへの取り組みについてはこちら:
https://www.nttdata.com/jp/ja/services/generative-ai
tsuzumi2についてはこちら:
https://www.nttdata.com/jp/ja/lineup/tsuzumi/
あわせて読みたい: