
Apache Hadoopとは
Apache Hadoop(以下Hadoop)とは、大規模データの蓄積・分析を分散処理技術によって実現するオープンソースのミドルウェアです。
Apacheプロジェクトの元で、Hortonworks社、米国Yahoo!社、Cloudera社といった初期から参加していた企業に加えて、Intel社、Microsoft社などより多くの企業のメンバーによって開発が続けられています。

Hadoopの特長
Hadoop分散処理基盤の代表的な特長は、以下の通りです。
単純なサーバの追加によってスケーラビリティを実現
HDFSの容量や分散処理のためのリソースが不足する場合、サーバを追加することで容量および処理性能の向上が可能です。
サーバの追加はHadoopクラスタの停止を必要としません。サービスを継続した状態での運用が可能です。
また、アプリケーションや基盤設計に影響を及ぼすことなく、新たにスケーラビリティを得ることができます。
非定型データの格納を想定した処理の柔軟性を実現
従来型のRDBMSやDWHと根本的に異なる点は、HDFSにデータを格納する際にはスキーマ定義が不要であることです。
そのため、事前の設計の手間を低減することができます。
Hadoopでは、処理するタイミングでHDFSに格納したデータにその都度意味づけするので、とりあえず格納して、処理の方針が決まった際にデータの扱い方を定義することができます。
コモディティ品の利用を前提とした基盤構成・耐障害性
Hadoop環境を構成するサーバは、専用ハードウェアや特別なスペックを必要としません。そのため、市販で入手できるサーバを利用することで、基盤構築の費用を抑えられます。
また、大量のサーバを利用する際には、サーバ故障時の扱いに気を付けなければなりませんが、Hadoopは故障発生を前提としたアーキテクチャであるため、任意のサーバが故障してもシステム全体として問題なく動作します。
商品ラインナップ
NTTデータでは、Hadoopに関する各種ソリューションサービスを提供します。

Hadoopコンサルティングサービス
お客さまが保有する多種多様なデータの活用し、新たな価値を生み出すために、専門技術者がご支援いたします。
提案支援、システム化コンサルティング、設計書レビューなど、まずはご相談ください。
Hadoop評価支援サービス
実機を用いてHadoopを評価したいというお客さまを、専門技術者がご支援いたします。
検証方法のご提案~結果の分析、チューニング観点のアドバイスなどを行います。
Hadoop構築サービス
十数~数千台の構築経験を活かして、専門技術者がHadoopシステムの構築を実施します。
最適な機器選びからチューニングまで、トータルにご支援いたします。
Hadoopサポートサービス
Hadoopの保守契約です。基本サポート内容はメールベースの技術問い合わせ・故障問い合わせ対応です。
保守プロダクトは、Hadoop、Spark、Kafkaをはじめとするオープンソースソフトウェアです。
オプションとしてオンサイトの故障対応も実施します。ご希望の方はお問い合わせください。
Hadoop教育サービス
「社内にHadoop技術者を育成したい」等、プライベートセミナをご希望の方はお問い合わせください。
お客さま事例
オープンソースの並列分散処理基盤「Hadoop」を数台~千台規模で構築・運用したノウハウを活用し、他の仕組みでは実現が難しいお客さまのデータ活用をご支援いたします。
ビッグデータ活用をご検討の方、既存のバッチ処理の長時間化にお困りの方に対し、オープンソースの並列分散処理基盤「Hadoop」のコンサルティングから、PoC、システム構築、運用設計、導入後のサポートまで幅広く提供いたします。

アクセスログやセンサデータ等「全て」蓄積し、全件分析を現実的な時間で実施→新たなサービスの検討や、迅速な戦略立案
【Point】
サンプリングデータではなく全てのデータを蓄積し、分析できます。

専用ホスト上のバッチ処理をコモディティサーバ上で大幅に短縮化→コスト対効果の高いバッチ処理基盤に
【Point】
Hadoopは、全件走査を必要とするバッチ処理を手堅く高速処理できます。公共/金融分野の基幹バッチ処理にも適用可能です。
Hadoop登場の背景
Hadoopは、Google社が論文として公開した、Google社内の以下の基盤技術をオープンソースとして実装したものを利用しています。
- GFS(Google File System:Google社の分散ファイルシステム)
- Google MapReduce(Google社での分散処理技術)
検索サービスで扱うWebページの情報をGFSに保存して、検索用インデックスをGoogle MapReduceで生成するなどの用途で利用されました。
これらの論文をもとに、Doug Cutting氏(現在、Apacheコミュニティの議長)を中心としたメンバーがJavaベースで開発したものが始まりです。
Doug氏たちは、Hadoopとして以下のコンポーネントを開発しました。そして、現在に至っています。
- HDFS(Hadoop Distributed File System:Hadoop分散ファイルシステム)
- Hadoop MapReduce Framework(Hadoop MapReduceフレームワーク)
なお、Hadoopという名前は、Doug氏のお子さんが持っていたお気に入りの象のぬいぐるみの名前を利用しています。
Hadoopの提供機能
Hadoopは、分散ファイルシステムであるHDFS(Hadoop分散ファイルシステム)と分散処理フレームワークであるHadoop MapReduceの2つから構成されます。
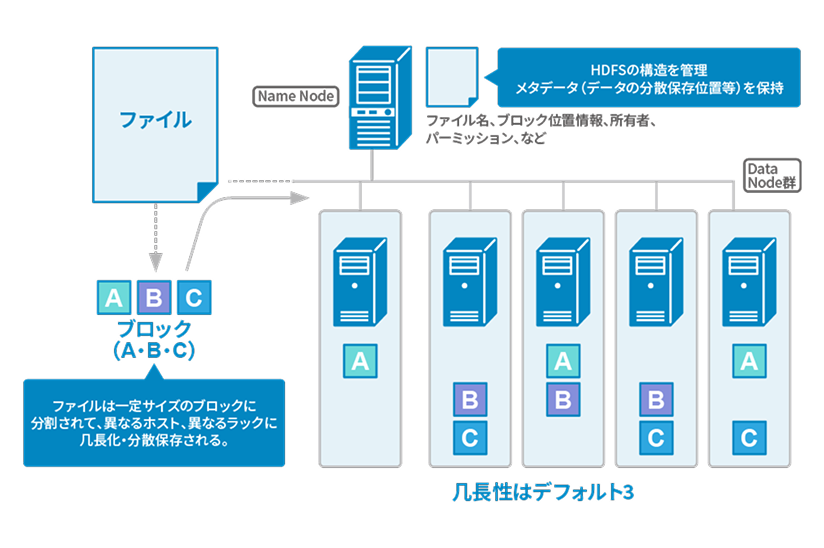
HDFSはNameNodeとDataNodeで構成され、レプリカで冗長性を確保し、大規模ファイル保存に適した分散ファイルシステムです。
Hadoop MapReduceは、分散処理を実現するMapReduce処理基盤と処理基盤上で実行するMapReduceアプリケーションの2つのコンポーネントがあります。
また、Hadoop2系ではYARNによるリソース管理が導入され、MapReduce以外の処理にも対応可能となり、より柔軟で拡張性の高い分散処理環境を提供します。
NameNodeがメタ情報を管理し、DataNodeがデータを保存する分散ファイルシステムです。
ファイルはブロックに分割され、複数のDataNodeにレプリカを配置することで耐障害性を確保します。
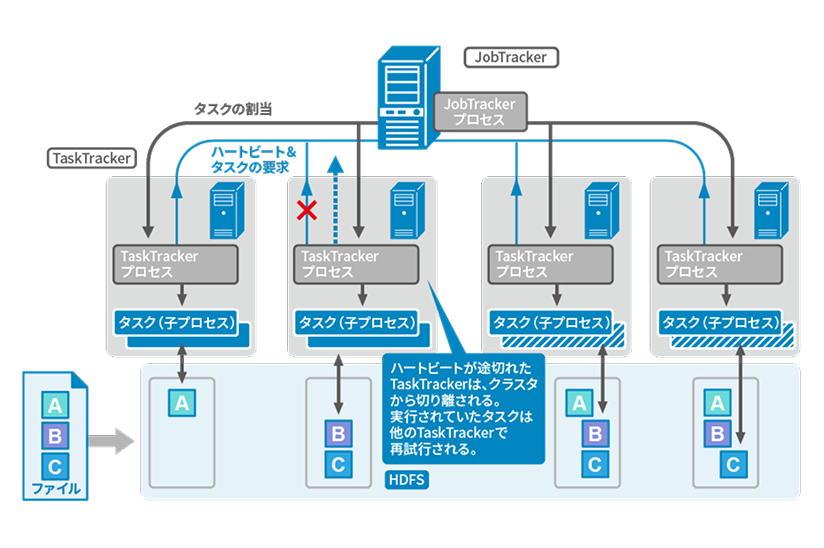
JobTrackerとTaskTrackerで構成され、ジョブ管理とタスク実行を担います。
故障時はタスクを再割り当てして処理を継続し、Mapタスクではデータローカリティを活用して通信負荷を軽減します。
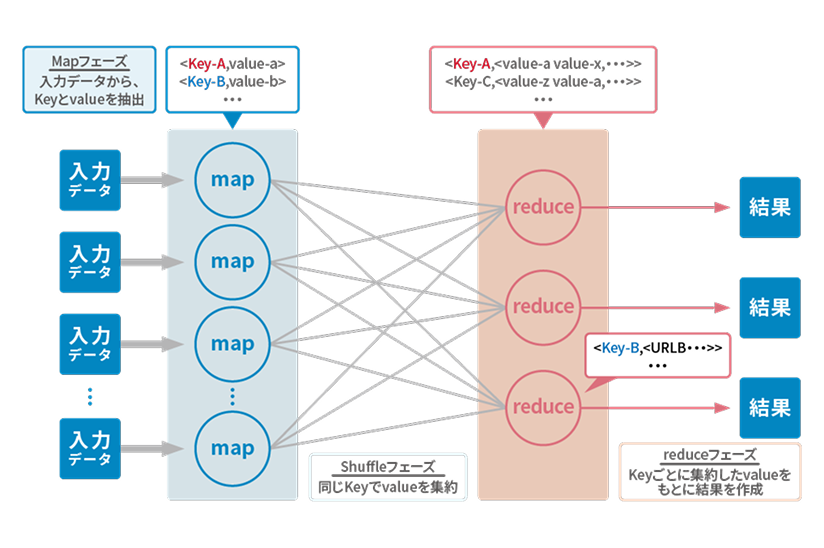
このアプリケーションは、map処理で入力データをキー・バリュー形式に変換し、reduce処理で集約データを処理します。
ジョブ定義により入力・出力や並列度を指定し、Hadoopが分散処理の複雑な実装を吸収するため、利用者は簡潔にバッチ処理を記述できます。
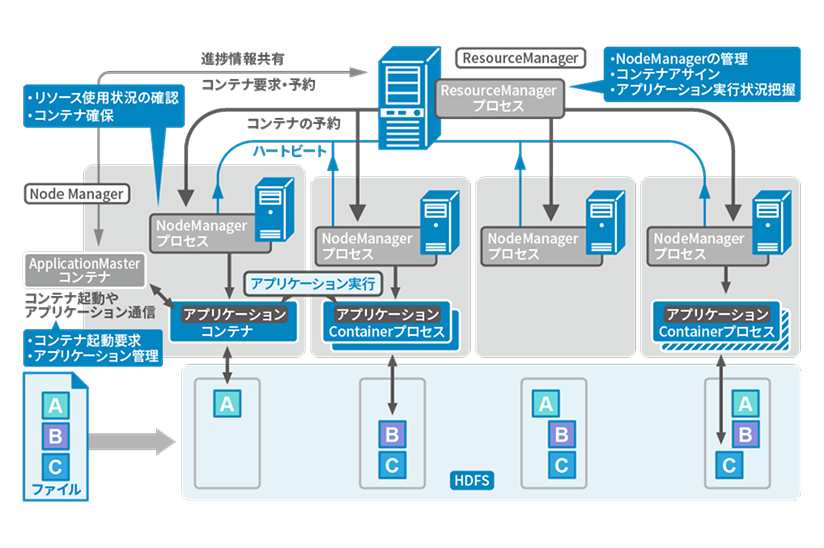
Hadoop2系ではMapReduceの仕組みがYARNに分離され、リソース管理をResourceManagerとNodeManagerが担います。
YARNによりMapReduce以外の分散処理も可能となり、Apache Sparkなどが活用されています。
これによりクラスタ規模は1系の約4000ノードから1万ノード程度まで拡張可能です。
補足・商標
- 記載されている会社名、商品名、サービス名等は、各社の登録商標または商標です。